

4. Кластерная архитектура
Реализация объединения машин, представляющегося единым целым для ОС, системного ПО, прикладных программами пользователей.
Типы кластеров
Системы высокой надежности/готовности (High Availability Systems, HA).
Системы для высокопроизводительных вычислений (High Performance, HP, Compute clusters ).
Многопоточные системы.
Load-balancing clusters. (распределение вычислительной нагрузки)
Пример:архитектура кластера theHIVE
5.Numa архитектура Non Uniform Memory Access – неоднородный доступ к памяти
Каждый процессор имеет доступ к своей и к чужой памяти (для доступа в чужую память используется коммутационная сеть или даже проц чужого узла). Доступ к памяти чужого узла может поддерживаться аппаратно: спец. контроллеры.
- : дорого, плохая масштабируемость.
Сейчас: NUMA осущ доступ к чужой памяти программно.
Вычислительная система NUMA состоит из набора узлов (содержит один или несколько процессоров, на нем работает единственная копия ОС), которые соединены между собой коммутатором либо быстродействующей сетью.
Топология связей разбивается на несколько уровней. Каждый из уровней предоставляет соединения в группах с небольшим числом узлов. Такие группы рассматриваются как единые узлы на более высоком уровне.
ОП физически распределена, но логически общедоступна.
В зависимости от пути доступа к элементу данных, время, затрачиваемое на эту операцию, может существенно различаться.
Примеры конкретных реализаций: cc-NUMA, СОМА, NUMA-Q
Пример: HP Integrity SuperDome
Упрощенные блок-схемы SMP (а) и MPP (б)

Пять основных архитектур высокопроизводительных ВС, их краткая характеристика, примеры. Сравнение кластерной архитектуры и NUMA.
В кластере каждый процессор имеет доступ только в своей памяти, в NUMA не только к своей, но и к чужой (для доступа в чужую память используется коммутационная сеть и процессор чужого узла).
SMP архитектура. Принципы организации. Достоинства, недостатки. Масштабируемость в «узком» и «широком» смысле. Область применения, примеры ВС на SMP.
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.

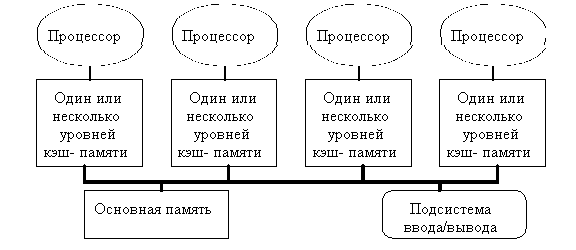
1. SMP-система строится на основе высокоскоростной системной шины, к слотам которой подключаются функциональные блоки трех типов: процессоры (ЦП), оперативная память (ОП), подсистема ввода/вывода (I/O).
2. Память является способом передачи сообщений между процессорами.
3. Все вычислительные устройства при обращении к ОП имеют равные права и одну и ту же адресацию для всех ячеек памяти.
4. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами.
5. SMP используется в cерверах и рабочих станциях на базе процессоров Intel, AMD, Sun, IBM, HP.
6. SMP-система работает под управлением единой ОС (либо UNIX-подобной, либо Windows). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Принципы организации:
SMP система состоит из нескольких однородных процессоров и массива общей памяти.
Один из часто используемых в SMP архитектурах подходов для формирования масштабируемой, общедоступной системы памяти, состоит в однородной организации доступа к памяти посредством организации масштабируемого канала память-процессоры.
Каждая операция доступа к памяти интерпретируется как транзакция по шине процессоры-память.
В SMP каждый процессор имеет по крайней мере одну собственную кэш-память (а возможно, и несколько). Можно сказать, что SMP система - это один компьютер с несколькими равноправными процессорами.
Когерентность кэшей поддерживается аппаратными средствами.
Все остальное - в одном экземпляре: одна память, одна подсистема ввода/вывода, одна операционная система.
Слово "равноправный" означает, что каждый процессор может делать все, что любой другой. Каждый процессор имеет доступ ко всей памяти, может выполнять любую операцию ввода/вывода, прерывать другие процессоры.
Масштабируемость:
В «узком» смысле: возможность подключения аппаратных средств в некоторых пределах (процессоры, память, интерфейсы).
В «широком» смысле: линейный рост показателя производительности при увеличении аппаратных средств.
Достоинства:
простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают абсолютно независимо друг от друга - однако, можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти.
легкость в эксплуатации. Как правило, SMP-системы используют систему охлаждения, основанную на воздушном кондиционировании, что облегчает их техническое обслуживание.
относительно невысокая цена.
преимущество, связанное с параллелизмом. Неявно производимая аппаратурой SMP пересылка данных между кэшами является наиболее быстрым и самым дешевым средством коммуникации в любой параллельной архитектуре общего назначения. Поэтому при наличии большого числа коротких транзакций (свойственных, например, банковским приложениям), когда приходится часто синхронизовать доступ к общим данным, архитектура SMP является наилучшим выбором; любая другая архитектура работает хуже.
архитектура SMP наиболее безопасна. Из этого не следует, что передача данных между кэшами желательна. Параллельная программа всегда будет выполняться тем быстрее, чем меньше взаимодействуют ее части. Но если эти части должны взаимодействовать часто, то программа будет работать быстрее на SMP.
Недостатки:
SMP-cистемы плохо масштабируемы:
1. Системная шина имеет ограниченную (хоть и высокую) пропускную способность и ограниченное число слотов, так называемое «узкое горлышко».
2. В каждый момент времени шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Когда произойдет такой конфликт, зависит от скорости связи и от количества вычислительных элементов.
Все это препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах эффективно можно использовать не более 8-16-32 процессоров.
Область применения: для работы с банковскими приложениями
Пример: Архитектура Sun Fire T2000. Архитектура UltraSPARC T1.
SMP архитектура. Совершенствование и модификация SMP архитектуры. SMP в современных многоядерных процессорах. Когерентность КЭШа.
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
Совершенствование и модификация SMP:
Пример: Архитектура QBB серверных систем серии GS DEC
С
 целью увеличения производительности
шины произведена попытка убрать шину,
но оставить общий доступ к памяти -->
переход и замена общей шины локальным
коммутатором (или системой коммутаторов):
каждый процессор в каждый момент времени
скоммутирован с 4 банками памяти.
целью увеличения производительности
шины произведена попытка убрать шину,
но оставить общий доступ к памяти -->
переход и замена общей шины локальным
коммутатором (или системой коммутаторов):
каждый процессор в каждый момент времени
скоммутирован с 4 банками памяти.
- каждый проц работает с каким-то банком памяти,
- переключается на другой банк памяти
- начинает работу с другим банком памяти.
SMP в современных многоядерных процессорах
Пример: Архитектура сервера Sun SPARC Enterprise T5220
Проблема когерентности КЭШей:
Каждый процессор имеет собственную кэш-память. Наличие кэша необходимо для достижения хорошей производительности, поскольку основная память DRAM работает слишком медленно по сравнению со скоростью процессоров. Кэш работает со скоростью процессора, но эта аппаратура дорогая.
Когерентность – поддержание актуальности инф-ции.
Для процессора кэш исполняет роль "рабочего стола", на котором хранится используемая в текущее время информация. При том, что в SMP имеется несколько устройств памяти, программное обеспечение ожидает видеть только одну общую память. Из этого следует, что если CPU1 сохраняет значение X в ячейке Q, а позже CPU2 загружает значение из ячейки Q, то CPU2 должно получить X. Но если на самом деле значение X было помещено в кэш CPU1, то как его сможет получить CPU2?
Этот пример иллюстрирует одну из сложных проблем SMP, называемую проблемой когерентности кэшей. Если CPU2 обращается к ячейке Q, и содержимое этой ячейки отсутствует в кэше B, то через системную шину для всего компьютера посылается широковещательный запрос "У кого Q?". Все устройства кэш-памяти, ОП и даже подсистема вв/выв определяют, не у них ли находится актуальная копия Q. То устройство, которое находит актуальную копию, посылает ее процессору B.
Поддержка когерентности серьезно влияет на производительность. Программа работает гораздо быстрее, в 10-20 раз, если используются данные, уже содержащиеся в кэше. Программы, которые обращаются к другим устройствам памяти, выполняются очень медленно.
Протоколы для SMP-систем:
Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли они копию соответствующего блока.
Пример: Протокол MESI (Modified/Exclusive/Shared/Invalid) - протокол для поддержки когерентности (согласованности) кэш-памяти процессоров в многопроцессорных системах.
Архитектура NUMA. Принципы. Сравнение SMP и NUMA. Примеры.
NUMA архитектура Non Uniform Memory Access – неоднородный доступ к памяти
К аждый
процессор имеет доступ к своей и к чужой
памяти (для доступа в чужую память
используется коммутационная сеть или
даже проц чужого узла). Доступ к памяти
чужого узла может поддерживаться
аппаратно: спец. контроллеры.
аждый
процессор имеет доступ к своей и к чужой
памяти (для доступа в чужую память
используется коммутационная сеть или
даже проц чужого узла). Доступ к памяти
чужого узла может поддерживаться
аппаратно: спец. контроллеры.
- : дорого, плохая масштабируемость.
Сейчас: NUMA осущ доступ к чужой памяти программно.
Архитектура NUMA - гибридная архитектура воплощает в себе удобства SMP и относительную дешевизну MPP.
Вычислительная система NUMA состоит из набора узлов ( содержит один или несколько процессоров, на нем работает единственная копия ОС), которые соединены между собой коммутатором либо быстродействующей сетью.
Топология связей разбивается на несколько уровней. Каждый из уровней предоставляет соединения в группах с небольшим числом узлов. Такие группы рассматриваются как единые узлы на более высоком уровне. На данный момент созданы ВС с 2-уровневыми схемами связей.
ОП физически распределена, но логически общедоступна.
В зависимости от пути доступа к элементу данных, время, затрачиваемое на эту операцию, может существенно различаться.
Примеры конкретных реализаций: cc-NUMA, СОМА, NUMA-Q и т.п.
Суть этой архитектуры - в особой организации памяти: память является физически распределенной по различным частям системы, но логически разделяемой, так что пользователь видит единое адресное пространство.
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти.
Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей.
При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной.
По существу архитектура NUMA похожа на MPP архитектуру, где в качестве отдельных вычислительных элементов берутся SMP узлы.
Пример:HP Integrity SuperDome (Осн эл-т арх Superdome, Межсоединения в Superdome)



M
 PP
архитектура. История развития,
транспьютерная технология. Основные
принципы МРР. Примеры.
PP
архитектура. История развития,
транспьютерная технология. Основные
принципы МРР. Примеры.
MPP - Система с массовым параллелизмом.
Архитектура: множество узлов, каждый узел – ОП+ЦП



Классическая МРР-архитектура: каждый узел соединен с 4 узлами по каналу «точка-точка».
В основе лежал транспьютер – мощный универсальный процессор, особенностью которого было наличие 4 линков (коммуникационные каналы связи). Каждый линк состоит из двух частей, служащих для передачи информации в противоположных направлениях, и используется как для соединения транспьютеров между собой, так и для подключения внешних устройств.
Проц-ры обмен-ся между собой данными. После передачи байта данных пославший его транспьютер ожидает получения подтверждающего сигнала, указывающего на то, что принимающий транспьютер готов к дальнейшему приему информации. Большая прикладная задача разбивается на процессы (на отдельный проц-р).
MPP система нач-ся со 128 проц-в. Если число проц-в < 64 то это точно не MPP, хотя тоже оборудование, тот же компилятор. Сообщения пересылаются через ряд проц-в. Нет узкого горлышка как у SMP.
Транспьютерная технология:
IMS T414 – 1984г.
IMS T800 – 1986г. (сопроцессор с плавающей точкой):
- RISC-процессор
- память 4Кб
- интерфейс с внешней памятью
- линии связи: 4 последовательных порта, двунаправленных: позволяют размещать несколько транспьютеров
- сопроцессор с плавающей точкой.

Основные параметры транспьютера:
Язык Occam – метаязык (осн. понятие: процесс – некая параллельная программа), язык обеспечивает описание простых операций пересылки данных м/д 2 точками, а также позволяет явно указывать на параллелелизм при выполнении программы несколькими транспьютерами.
INMOS – фирма, выпустившая первый транспьютер – RISC-процессор в 1984 - 1990 г.г.
Взаимодействие между процессами в языке Оккам является двухточечным, синхронным и небуферизованным. Вследствие этого для канала нет необходимости в очереди процессов и сообщений, а также не нужны буферы сообщений.
Сравнительные характеристики Intel 386 и T414:

Транспьютерные топологии
Физические топологии 2D — шина (bus), звезда (star), кольцо (ring), дерево (tree), сетка (mesh)
Классическая МРР - 3D-решетка
Масштабируемость MPP-систем – бесконечна.
Лидер МРР сегодня – кол-во процессоров 200000шт.
Пример: Архитектура TMS320C40
Концепция, архитектура и характеристики суперкомпьютера Intel Paragon.
MPP (Система с массовым параллелизмом): множество узлов, каждый узел – ОП+ЦП.
Paragon (Intel) – разработка Калифорнийского технологического института, 1992г.
Основан на МП Intel i860 (1989г, RISC).
Структура: до 2048 (позже до 4000) i860 были связаны в 2D сетки.
Node – процессные узлы. 3 типа:
1)вычислительные (процессные)
2) сервисные (UNIX-вые возможности для разработки программ).
3)узлы в/в (могут подкл либо к общим ресурсам (дисковым), либо через них реализуется интерфейс с др. сетями).
MRC (маршрутизатор) – набор портов, которые могут связываться между собой и к каждому маршрутизатору может подкл компьютер.
Каждый узел содержал от 1 до 3 МП i860.
Архитектура Intel Paragon XP/S


Процессный узел Paragon:
Схема процессорного ядра:
1) Исполнительный монитор (позволяет отлаживать, контролировать, записывать работу узла).
2) Процессор приложений
3) ОП (32-64Mb)
4) Машины передачи данных (2 шт): одна на прием, др.на передачу.
5) Процессор сообщений (i860)
6) Контроллер сетевого интерфейса (порты кот-ые выходят на MRC)
7) порт расширения, к кот через интерфейсные карты могли подключатьсяся (8) и (9)
8) Интерфейс в/в
9) К кот подкл: либо ЛВС, либо ЖД.
Выводы разработки Intel Paragon:
1. Для реализации MPP не нужно разрабатывать спец. процессор (проц+дешевая сеть=МРР-решетка 2D, 3D)
2. Нужно брать существующие процессоры, не самые новые, немного устаревшие (дешевле), т.к. важнее кол-во процессоров, а не производительность.
Иерархия памяти. Архитектурные способы увеличения быстродействия памяти: конвейерная и пакетная обработка, кэширование.
Возможный состав систем памяти:



В выполняемой программе адреса команд и адреса данных, как правило, находятся в компактной области адресного пространства. Благодаря такой локальности, размещая данные в верхней части иерархии памяти можно существенно улучшить характеристики доступа.
Пересылка данных с уровня на уровень осуществляется блоками, их величина определяется характеристиками памяти нижнего уровня.
На пересылку блока уходит меньше времени, чем на пересылку отдельных данных блока.
При произвольном доступе к данным, время доступа лимитируется самым медленным устройством.
Память с расслоением:
Наличие в системе множества микросхем памяти позволяет использовать потенциальный параллелизм, заложенный в такой организации. Для этого микросхемы памяти часто объединяются в банки или модули, содержащие фиксированное число слов, причем только к одному из этих слов банка возможно обращение в каждый момент времени.
Чтобы получить большую скорость доступа, нужно осуществлять одновременный доступ ко многим банкам памяти. Одна из общих методик, используемых для этого, называется расслоением памяти.
При расслоении банки памяти обычно упорядочиваются так, чтобы N последовательных адресов памяти i, i+1, i+2, ..., i+ N-1 приходились на N различных банков. В i-том банке памяти находятся только слова, адреса которых имеют вид kN + i. Можно достичь в N раз большей скорости доступа к памяти в целом, чем у отдельного ее банка, если обеспечить при каждом доступе обращение к данным в каждом из банков. Имеются разные способы реализации таких расслоенных структур.
Степень или коэффициент расслоения определяют распределение адресов по банкам памяти.
Такие системы оптимизируют обращения по последовательным адресам памяти, что является характерным при подкачке информации в кэш-память при чтении, а также при записи, в случае использования кэш-памятью механизмов обратного копирования.
Однако, если требуется доступ к непоследовательно расположенным словам памяти, производительность расслоенной памяти может значительно снижаться.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контроллеров памяти позволяют банкам памяти (или группам расслоенных банков памяти) работать независимо.
Пакетная обработка Конвейерная обработка


ОП состоит из банков, в которых хранятся слова. Для доступа (скажем, чтения) к слову необходимо задать его адрес на шине адреса, подождать некоторое время (скажем, 100 нс) и считать данные на шине данных. Если надо считать 4 слова, то можно задать адрес первого слова, подождать, считать слово. Затем задать адрес второго слова... Таким образом, полный цикл займёт более 400 нс. Чтобы ускорить процесс доступа к памяти, придумали расслоение. Для этого данные читаются не из одного банка, а из нескольких. Либо одновременно, либо почти одновременно. Первый метод расслоения - это пакетная обработка. В этом случае адрес (точнее, его части) выдаётся сразу на все банки памяти. И из каждого банка считывается одно слово. Получаем (в нашем примере) время доступа 100 нс. Только вместо одного слова мы получили на шине данных четыре. При этом никаких сложных архитектурных решений не применяли. Но и оставшиеся 3 слова могут быть в данный момент не нужны. Поэтому надо составлять программу так, чтобы все 4 одновременно считываемых слова были нужны одновременно. Второй метод расслоения сложнее. Здесь в каждый банк памяти вводится что-то типа буфера адреса. А на выходе каждого банка что-то типа буфера данных. Адреса выдаются на каждый банк без значительной задержки, один за другим, без ожидания результата. Это выглядит так: А1-А2-А3-А4-Ожидание100нс-ЧтениеДанных1-ЧтениеДанных2-ЧтениеДанных3-ЧтениеДанных4. Таким образом, мы можем считать из ОП 4 произвольных слова. Но затратим всего около 108 нс, время, соизмеримое с чтением одного слова. Это очень эффективной метод, но он требует дополнительных схемотехнических решений - буферов адреса, данных, системы управления всем этим делом (что-то типа арбитра, который будет решать, к какому банку можно обращаться в данный момент на чтение, а к какому - на задание адреса). Также есть вероятность неупорядоченной выдачи данных на шину, этого тоже нельзя допускать. Пример. Первый случай. Мы хотим считать слова 1,2,3,4. В пакетном методе задаём адрес одного слова и считываем цепочку из 4 слов: 1-2-3-4. В конвейерном методе по-очереди задаём все 4 адреса и считываем те же 1-2-3-4. Второй случай. Хотим считать 1,6,11,16 слова. В первом методе мы получим: (1)-2-3-4; 5-(6)-7-8; 9-10-(11)-12; 13-14-15-(16) то есть никакого выигрыша, нужно всё так же 4 обращения. В конвейерном методе мы зададим адреса 1,6,11,16 по очереди во все банки: в первый 1, во второй 6, в третий 11 и в четвёртый 16. И получим эти все 4 слова очень быстро, практически за время доступа к одному слову. Итак, пакетный метод проще в реализации, а конвейерный - эффективнее чем пакетный, но сложнее в реализации. Кэш — это память с большей скоростью доступа, предназначенная для ускорения обращения к данным, содержащимся постоянно в памяти с меньшей скоростью доступа (далее «основная память»).
Кэш состоит из набора записей. Каждая запись ассоциирована с элементом данных или блоком данных (небольшой части данных), которая является копией элемента данных в основной памяти. Каждая запись имеет идентификатор, определяющий соответствие между элементами данных в кэше и их копиями в основной памяти.


Среднее время доступа в системе с кэш:
Т доступа сред кэш = Т обращения + (kпромахов
* Т потерь), где:
доступа сред кэш = Т обращения + (kпромахов
* Т потерь), где:
- Тобращ - время обращения;
- kпромахов- коэффициент промахов, обычно меньше 10% (0<=k<=1);
- Тпотерь - потеря времени при обращении к оперативной памяти.
Параметры КЭШа:
Адресация ОП – 18 бит
Емкость кэш – 2 Кслов = 128 блоков
Размер блока – 16 слов
Емкость ОП – 256 Кслов = 16384 блоков