

3.3.1 Групування процесів. Властивості crud-матриці
Бажано, щоб процеси, що працюють з тими ж самими даними, були згруповані разом. Для того, щоб полегшити групування процесів, корисно сформувати робочий документ – «CRUD (Create, Read, Update, Delete)-матриця». Використання процесами сховищ даних відображене на СПД (Схемі Потоків Даних). Матриця зображується у вигляді перерахування процесів останнього рівня в рядку і об'єктів у колонку. В ячейках матриці записуються:
C – створення нових даних;
R – просте читання даних;
U – процес обробки даних, що надходять в об'єкт;
D – видалення існуючих даних.
Це дає можливість виділити ті процеси, що будуть обробляти однакові набори даних.
Якщо процес використовує кілька різних об'єктів, то для групування необхідно виділити пріоритети. Як правило, перетворені об’єкти важливіші за тих, що тільки зчитуються. Якщо процес перетворює кілька об'єктів з різних сховищ даних, то для того, щоб вирішити, яке перетворення має найвищий пріоритет, необхідно розглянути головну мету процесу. Це правило допоможе в тому випадку, коли логічне групування неочевидне. Однак бажано, щоб групування виконувалося з урахуванням функціональних особливостей предметної області системи і типової подоби процесів.
3.3.1.1 Засоби імпорту/експорту
При розробці моделі потоків даних і логічної моделі паралельно, найчастіше для полегшення праці розроблювачів використовують засоби імпорту/експорту з одного середовища моделювання в іншу. Так, щоб уникнути дублювання дій, розроблювачу досить один раз описати атрибути даних для того, щоб вони були відображені в ERD і DFD.
3.3.1.2 Імпорт
Для того, щоб одержати сутності в середовищі розробки ERD, досить зробити імпорт із середовища розробки DFD. Перед початком імпорту необхідно переконатися в наступному:
у вікні властивостей сховища даних (Data Store Properties) позначка Is Entity позначена;
атрибути сховища даних не повинні бути порожні, інакше буде зроблена невірна операція імпорту.
Після того, як умови будуть виконані, можна переходити до імпорту.
Відкрити пакет PowerDesigner DataArchitect->File->Import-> PowerDesigner ProcessAnalyst. Після виконання цієї операції необхідно у вікні Import File вказати ім'я файла, з якого проводиться імпорт. У результаті імпорту із середовища розробки діаграм потоків даних у середовище розробки діаграм «сутність-зв'язок» розроблювач одержує готові сутності (рис. 3.1), цілком відповідні існуючим сховищам даних.




Рисунок 3.1 – Вид сутностей, отриманих у результаті імпорту
Отримані сутності ще не є діаграмою «Сутність-Зв'язок», яка вимагає подальшої трудоємкої доробки.
3.3.1.3 Засоби документування
Для створення документації в процесі розробки ІС використовуються різноманітні засоби формування звітів, а також компоненти видавничих систем. Звичайно, засоби документування убудовані в конкретні CASE-засоби.
PowerDesigner ProcessAnalyst дозволяє формувати кілька форм звітів:
Full PAM Report;
List PAM Report;
Standard PAM Report.
Для того, щоб сформувати звіт, необхідно викликати вікно Report, виконавши команду File->Create Report чи Ctrl+E (рис. 3.2). У рядку Report Name увести тип звіту. Звіт перед друком можна переглянути (Preview) і зберегти (Save RTF):
Full PAM Report;
List PAM Report;
Standard PAM Report.

Рисунок 3.2 – Вікно вказівки звіту
Крім шаблонових, пакет дозволяє створення індивідуальних форм звітів чи модифікування існуючих. Для модифікації звіту треба скористатися Modify (рис. 3.2) і відкрити вікно PowerDesigner ProcessAnalyst, що зображене на рис. 3.3.
Рисунок 3.3 – вікно формування нестандартного звіту
Для створення індивідуальної форми звіту у рядку Report Name увести слово New і відкрити вікно, зображене на рис. 3.3. Після цього з вікна Available Items додати необхідні компоненти у вікно Contents.
3.5 Зміст звіту
Звіт повинний містити:
1. Мету роботи.
Опис етапів виконання роботи.
Короткий опис отриманих результатів.
Роздруківку CRUD-матриць.
Роздруківку отриманих сутностей.
Роздруківку звіту, складеного за індивідуальними вимогами.
Висновки по роботі.
3.6 Контрольні запитання
1. Для чого потрібна CRUD-матриця, і яких типів вона буває?
Як формується CRUD-матриця?
Для чого використовується імпорт?
Що потрібно врахувати, перш ніж переходити до імпорту?
Для чого потрібна документація, розроблювальна в процесі проектування ІС?
Які види документації використовуються в SSADM?
Яка послідовність розробки МПД і ЛМД припустима в SSADM?
4 Проектування логічної структури даних
4.1 Мета роботи
Вивчення принципів та надбання практичних навичок роботи з CASE-засобом PowerDesigner Data Architect: проведення інсталяції, настроювання пакета, використання для створення ER-діаграм для логічного та фізичного рівня моделювання і генерації структур баз даних.
4.2 Організація самостійної роботи
У процесі підготовки до лабораторної роботи з даної теми необхідно вивчити теоретичний матеріал, використовуючи конспект лекцій і літературні джерела [1, 3], а також підготувати матеріали щодо внутрішньої структури сутностей, включаючи визначення їх атрибутів, унікальних ідентифікаторів та ключів.
4.3 Склад лабораторного устаткування
Лабораторна робота виконується на обчислювальному комплексі, у складі якого: локальна обчислювальна мережа комп'ютерів типу IBM PC, OC Windows98/2000/NT4.0.
4.4 Порядок виконання роботи
Логічне моделювання даних призначене для побудови точної інформаційної моделі вимог до всієї проектованої системи в цілому чи до окремих її частин. Логічне моделювання даних пронизує всю технологію проектування SSADM, і при цьому відбувається поступова трансформація виду вимог - від представлення в категоріях предметної області системи до представлення в термінах системного функціонування.
Логічна модель даних:
допомагає аналітику зрозуміти предметну область системи за допомогою формалізації представлення про неї;
забезпечує ясність, точність і простоту представлення вимог за рахунок використання стандартних схематичних позначень;
забезпечує досягнення взаєморозуміння між розроблювачами на ранніх стадіях проектування;
є основою для проектування баз даних;
визначає термінологію, використовувану згодом при складанні різних посібників для користувачів проектованої системи.
При логічному моделюванні даних об'єктами розгляду для аналітика є найбільш важливі предмети і поняття відповідної предметної області чи проектованої системи. При цьому аналітик повинний ідентифікувати головні атрибути (описувачі властивостей) цих об'єктів, як частини їхнього визначення.
Логічне моделювання даних у SSADM орієнтоване на проектування комп'ютерних систем. Разом з цим можливість зміни рівня деталізації розгляду дозволяє використовувати даний метод для задоволення інших потреб, включаючи створення моделей для підтримки стратегічних досліджень, моделювання вимог до інформаційного обміну в системах, що не включають у свій склад комп'ютери і бази даних, а також як засіб спілкування при аналізі складних структур. Логічна модель даних (ERD – Entity Relationship Diagram) є також важливим елементом адміністрування даних, тому що за своєю суттю вона забезпечує посилання між значеннєвим змістом і значеннями даних, що у ній описані, та зрозуміла всім зацікавленим особам.
За допомогою діаграм «Сутність-зв'язок» (ERD) визначаються важливі для предметної області об'єкти (сутності), їхні властивості (атрибути) і відносини один з одним (зв'язки). ERD безпосередньо використовуються для проектування реляційних баз даних. Таким чином, основними компонентами діаграм «Сутність-зв'язок» є:
1) сутність;
2) зв'язок;
3) атрибут.
4.4.1 Сутність (Entity)
Сутність – це реальний або уявлюваний об'єкт, що має істотне значення для розглянутої предметної області, інформація про який підлягає збереженню (рис. 4.1).
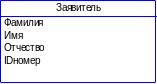

Рисунок 4.1 – Графічне представлення сутності
Кожна сутність повинна мати унікальний ідентифікатор. Кожен екземпляр сутності повинний однозначно ідентифікуватися і відрізнятися від всіх інших екземплярів даного типу сутності. Кожна сутність повинна мати деякі властивості:
кожна сутність повинна мати унікальне ім'я, і до того ж самого імені повинна завжди застосовуватися та ж сама інтерпретація. Та ж сама інтерпретація не може застосовуватися до різних імен, якщо тільки вони не є псевдонімами;
сутність володіє одним чи декількома атрибутами, що або належать сутності, або успадковуються через зв'язок;
сутність володіє одним чи декількома атрибутами, що однозначно ідентифікують кожен екземпляр сутності;
кожна сутність може мати будь-яку кількість зв'язків з іншими сутностями моделі.
4.4.2 Зв'язок (Relationship)
Зв'язок - це пойменована асоціація між двома сутностями, значима для розглянутої предметної області, причому, як правило, кожен екземпляр однієї сутності, що називається батьківською сутністю, асоціюється з довільною (у тому числі нульовою) кількістю екземплярів другої сутності, яка називається сутністю-нащадком, а кожен екземпляр сутності-нащадка асоціюється у точності з одним екземпляром сутності-батька. Таким чином, екземпляр сутності-нащадка може існувати тільки при існуванні сутності-батька.
Зв'язку може надаватися ім'я, що виражається граматичним оборотом дієслова і поміщається біля лінії зв'язку. Ім'я кожного зв'язку між двома даними сутностями повинне бути унікальним, але для імен зв'язків у моделі це не обов'язково. Ім'я зв'язку завжди формується з боку батька, так що вираз може бути утворений з'єднанням імені сутності-батька, імені зв'язку, вираження ступеня й імені сутності-нащадка. Зв'язок представляється на схемах або у вигляді лінії, що з'єднує два об'єкти, або у вигляді петлі, що з'єднує об'єкт із самим собою (рис. 4.2).


Рисунок 4.2 – Позначення зв'язку між об'єктами
Ступінь зв'язку визначається таким чином:
один до одного (1:1), при якому з одним екземпляром об'єкта асоціюється один екземпляр іншого об'єкта (рис. 4.2);
один до багатьох (1:m), при якому з одним екземпляром об'єкта асоціюється один чи більш екземплярів іншого об'єкта (рис. 4.3);


Рисунок 4.3 – Графічне представлення зв'язку m:1
багато до багатьох (m:m), при якому з одним чи більш екземплярів об'єкта асоціюється один чи більш екземплярів іншого об'єкта (рис. 4.4).


Рисунок 4.4 – Графічне представлення зв'язку m:m
Ступінь обов'язковості визначається, виходячи з таких міркувань:
обов'язковий зв'язок (mandatory), якщо участь об'єкта в зв'язку обов'язкова, тобто екземпляр об'єкта не може існувати без наявності елементів зв'язку;
підлеглий зв'язок (dependent);
Взаємно виключні зв'язки – це такі зв'язки, коли кожен екземпляр сутності бере участь тільки в одному зв'язку з групи взаємно виключних зв'язків.
Якщо участь екземпляру об'єкта в одному зв'язку забороняє його участь в одному чи більш інших зв'язках, то це означає наявність у схемі групи виключних зв'язків. Усі зв'язки, що входять у таку групу, повинні мати загальний предметний об'єкт і однакову характеристику потужності. На момент розгляду для будь-якого екземпляру загального об'єкта може існувати тільки один зв'язок із групи.
4.4.3 Атрибут
Атрибут - будь-яка характеристика сутності, значуща для розглянутої предметної області і призначена для кваліфікації, ідентифікації, класифікації, кількісної характеристики чи вираження стану сутності. Атрибут представляє тип характеристик чи властивостей, асоційованих з множиною реальних чи абстрактних об'єктів (людей, місць, подій, станів, ідей, пар предметів і т.і.). Екземпляр атрибута - це визначена характеристика окремого елемента множини. Екземпляр атрибута визначається типом характеристики і її значенням, що називається значенням атрибута. У ER-моделі атрибути асоціюються з конкретними сутностями. Таким чином, екземпляр сутності повинний володіти єдиним визначеним значенням для асоційованого атрибута.
Атрибут може бути або обов'язковим, або необов'язковим. Обов'язковість означає, що атрибут не може приймати невизначених значень (null values). Атрибут може бути або описовим (тобто звичайним дескриптором сутності), або входити до складу унікального ідентифікатора (первинного ключа).
Унікальний ідентифікатор - це атрибут чи сукупність атрибутів або зв'язків, призначена для унікальної ідентифікації кожного екземпляра даного типу сутності. У випадку повної ідентифікації кожен екземпляр даного типу сутності цілком ідентифікується своїми власними ключовими атрибутами. У протилежному випадку в його ідентифікації беруть участь також атрибути іншої сутності-батька.
Кожен атрибут ідентифікується унікальним ім'ям, що виражається граматичним оборотом іменника, який описує характеристику, представлену атрибутом. Атрибути зображуються у вигляді списка імен усередині блока асоційованої сутності, причому кожен атрибут займає окремий рядок. Атрибути, що визначають первинний ключ, розміщуються нагорі списку і виділяються підкресленням.
Кожна сутність повинна володіти хоча б одним можливим ключем. Можливий ключ сутності - це один чи кілька атрибутів, чиї значення однозначно визначають кожен екземпляр сутності. При існуванні декількох можливих ключів один з них позначається як первинний ключ, а інші - як альтернативні ключі.
4.4.4 Опис редактора
Головне вікно пакета призначене для відображення ERD і сервісних діалогових вікон.
У верхній частині екрана нижче назви пакета розташована лінійка головного меню. Під нею знаходиться основна інструментальна панель (Toolbar).
У лівому верхньому куті основної частини екрана розташовується вікно інструментів (Tools), що містить піктограми всіх базових елементів ERD і визначає можливі дії по їхній побудові. Вид головного вікна програми показаний на рис.4.5.
Рисунок 4.5 – Головне вікно DataArchitect
Основні найчастіше використовувані елементи вікна інструментів (Toos):
Entity - сутності;
Relationship - зв'язок між сутностями;
Inheritance link - спеціальний зв'язок між сутностями (Special relationship that defines an entity as a special case of a more general entity).
4.4.5 Алгоритм побудови логічної моделі даних
4.4.5.1 Отримання інформації і виділення сутностей
До початку створення Логічної Моделі Даних необхідно провести дослідження об'єкта, отримавши інформацію з інтерв'ю. Виділити сутності і визначити їхні імена. Наступним кроком виділення інформації є визначення атрибутів і первинних ключів, а також визначення наявності і типів зв'язків між сутностями.