

ВСТУП
Проектування складних інформаційно-управляючих систем незалежно від галузі їх застосування - це процес, який вимагає багато часу і ресурсів, а також залучення багатьох висококваліфікованих фахівців. Якість результатів проектування визначається досвідом, знаннями, евристичними припущеннями та перевагами розробників, що призводить до невідтворюваності результатів, відсутності наступності при заміні фахівців, труднощів сприймання концепції розробки із-за унікальності об’єкта проектування. Ці обставини вимагають впровадження стандартизованих методологій проектування. Методологія структурного системного аналізу дозволяє розробникам:
адекватно проаналізувати вимоги до інформаційно-управляючої системи;
обрати стратегію її розробки;
виконати проектування та специфікацію інформаційної системи.
Мета цих методичних вказівок – допомогти студентам поглибити свої теоретичні знання з дисципліни та отримати практичні навички з розробки як деяких елементів, так і проектів систем різного призначення в цілому, а також їх документуванню за допомогою CASE-засобів на прикладі пакета PowerDesigner ProcessAnalist.
Лабораторний практикум з дисципліни складений таким чином, що результати виконання попередньої лабораторної роботи є вхідними даними наступної. Це потребує від студентів чіткого виконання завдань з кожної роботи в повному обсязі.
Звіти з лабораторних робіт готуються за результатами виконання кожної з них у відповідності з вимогами, наведеними до кожної лабораторної роботи у розділі „Зміст звіту”.
1 Вивчення основних прийомів роботи
з CASE-засобом PowerDesigner ProcessAnalyst
1.1 Мета роботи
Метою роботи є вивчення принципів роботи з CASE-засобом PowerDesigner ProcessAnalyst: проведення інсталяції, настроювання пакета, придбання основних навичок роботи з діаграмами потоків даних (DFD).
Організація самостійної роботи
Підготуватися до лабораторної роботи за конспектом лекцій та [1, гл.1] вивчити теоретичний матеріал “Метод моделювання потоків даних”.
Для виконання лабораторної роботи визначити за допомогою викладача об'єкт моделювання та проектування. Розробити контекстну діаграму для об’єкта моделювання, а також опис його головних функцій.
1.3 Склад лабораторного устаткування
Лабораторна робота виконується на обчислювальному комплексі, у складі якого: локальна обчислювальна мережа комп'ютерів типу IBM PC, OC Windows98/2000/NT4.0.
1.4 Порядок виконання роботи
Робота полягає в ознайомленні з CASE-засобом PowerDesigner ProcessAnalist. Програмний пакет PowerDesigner ProcessAnalyst реалізує методологію функціонального моделювання на основі графічних діаграм потоків даних ( Data Flow Diagram - DFD ), що наочно представляють структуровані інформаційні моделі реальних об'єктів предметної області і їхніх взаємозв'язків. У ході роботи проводиться інсталяція пакета, настроювання й установка параметрів відображення моделі, вивчення основних прийомів роботи з нею.
Інсталяція CASE-засобу PowerDesigner ProcessAnalist
Дистрибутив пакета розміщується на 4-х дискетах. Установка пакета на жорсткий диск починається з запуску файлу setup.exe з першої настановної дискети дистрибутива (папка DISK1). Програма установки виконана з використанням стандартного майстра установки InstallShield Wizard. В процесі установки пропонується вказати місце установки програми. Якщо немає особливої необхідності, то програма встановлюється за замовчуванням у папку Program Files->Powersoft->PowerDesigner 6.
Щоб почати роботу, необхідно здійснити запуск середовища розробки моделей потоків даних: меню Пуск -> Програми -> PowerDesigner 6 32-bit -> ProcessAnalyst. Вид головного вікна програми PowerDesigner показаний на рис.1.1.
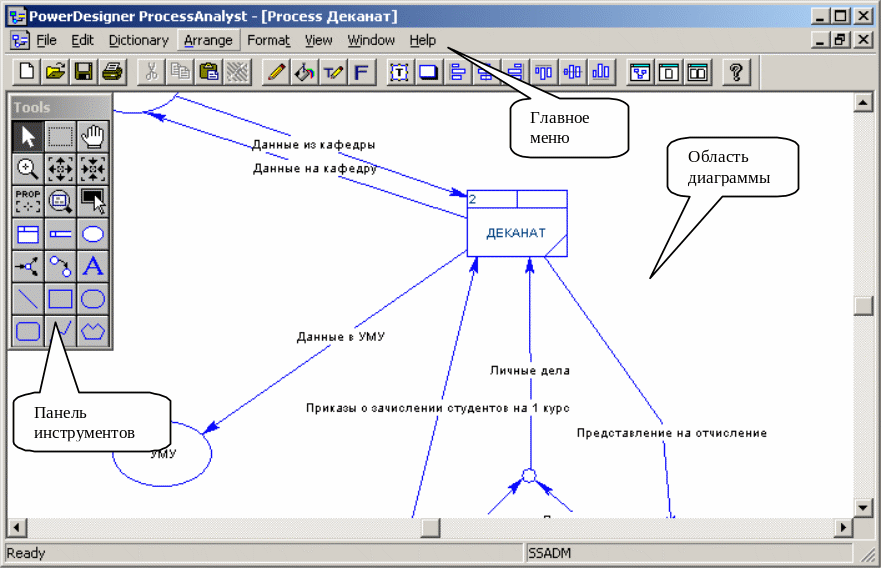
Рисунок 1.1 – Головне вікно ProcessAnalyst
з розробленими елементами моделі
Настроювання параметрів відображення моделі
Для настроювання параметрів відображення моделі використовується вікно File -> Display Preferences.
Перш ніж конструювати елементи моделі, необхідно настроїти шрифти моделі для коректного відображення кириличних символів. Установки на закладці Symbols (рис.1.2) використовуються для заміни шрифтів кожного елементу діаграми.
1.4.3 Установка параметрів моделі
Для визначення параметрів моделі необхідно зайти в меню File -> Model Options, закладка General (рис. 1.4), де:
Enforce DataType – примушувати вказувати типи даних;
Enforce Check – нав'язувати перевірку моделі;
Enforce Rules – примушувати вказувати бізнес-правила;
Model Type – тип моделі: контекстна/не контекстна;
Method - вказати метод, що використовується при створенні моделі;
Data Stores – вибір режиму заповнення сховищ даних: автозаповнення/індивідуальне заповнення.
На закладці Name того ж вікна (рис. 1.5) задаються припустимі (Valid characters) і неприпустимі (Invalid characters) символи у моделі, а також максимальна довжина символьного рядку (Maximum length).
У вікні Model Options Code задаються максимальна довжина коду і символи припустимі/неприпустимі (Valid/Invalid characters) для створення кодів (рис.1.6).
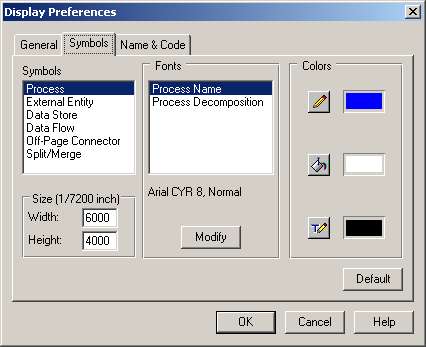
Рисунок 1.2 – Вікно Display Preferences - настроювання шрифтів
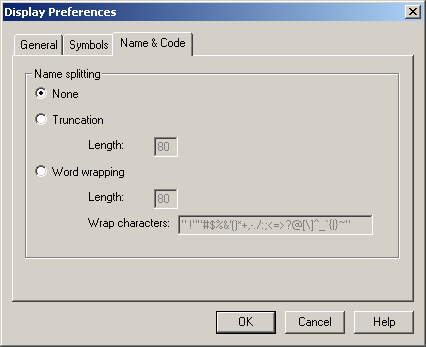
Рисунок 1.3 – Вікно Display Preferences Name & Code
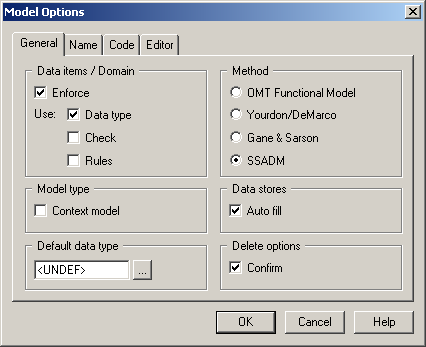
Рисунок 1.4 – Вікно Model Options General
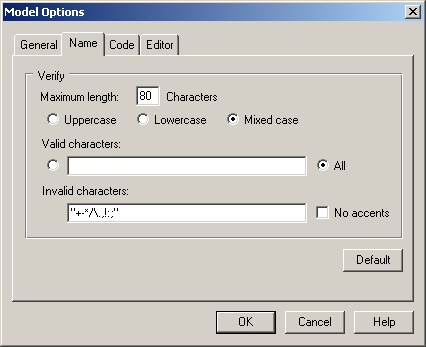
Рисунок 1.5 – Вікно Model Options Name – визначення
допустимих символів у моделі
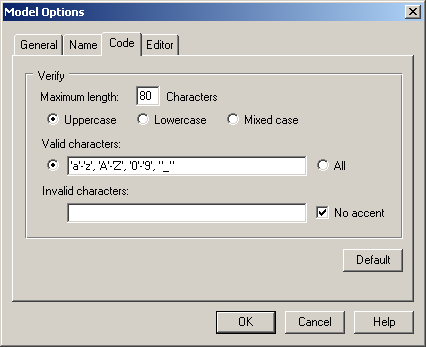
Рисунок 1.6 - Вікно Model Options Code –
визначення припустимих символів для створення кодів
Для визначення редакторів описів, анотацій і специфікації використовується вікно Model Options Editor (рис. 1.7). В ньому треба вказати тип редактора – зовнішній/внутрішній (External/internal editor).
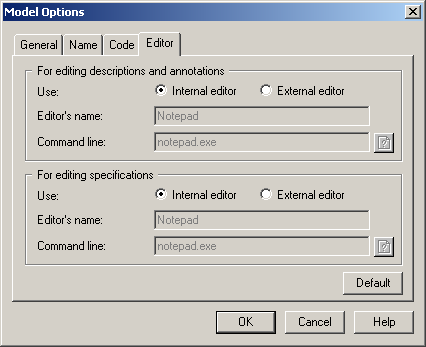
Рисунок 1.7 – Вікно Model Options Editor
Вивчення основних прийомів роботи з моделлю
1.4.4.1 Завантаження прикладу моделі
Для вивчення основних прийомів роботи з моделлю необхідно завантажити модель, представлену як базовий приклад, що знаходиться в папці Examples у кореневій папці встановленого пакету ProcessAnalyst (Меню File->Open).
1.4.4.2 Словник системи (Dictionary)
Будь-яка модель системи має свій набір базових елементів, і їхній опис являє собою словник системи. Підсистема має наступні складові.
Ведення інформації про розроблювача
Кожна система має загальну інформацію про модель і розроблювача цієї моделі. У цьому пакеті таку інформацію можна занести у вікні Process Model Properties, що знаходиться в меню Dictionary (рис. 1.8). В нього заноситься ім'я проекту, код проекту, ім'я розроблювача, мова розробки, версія пакету.
Закладки вікна Description і Annotation використовуються відповідно для складання опису і анотації проекту.
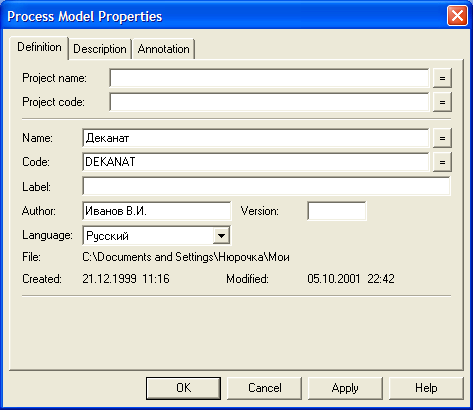
Рисунок 1.8 – Вікно Process Model Properties – властивості моделі процесу
Засіб навігації по дереву процесів
Для зручності користування моделлю і швидкого пошуку об'єктів моделі використовується дерево процесу – Process Tree (рис. 1.9), де зазначені всі процеси моделі, їхні рівні і нумерація. При використанні дерева процесів можна швидко знайти будь-який процес моделі і перейти на його рівень. Вікно Process Tree знаходиться в меню Dictionary -> Subprocesses.
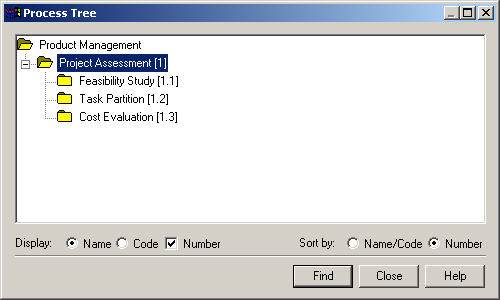
Рисунок 1.9 – Вікно дерева процесу
Список об'єктів системи
У меню Dictionary міститься список об'єктів системи - List of Objects: процесів, сховищ даних, зовнішніх сутностей, потоків, зв’язуючих вузлів між потоками. Вікно List of Objects представлене на рис. 1.10. Кожна закладка вікна містить у собі список елементів визначеного типу, їхні коди, тип даних.
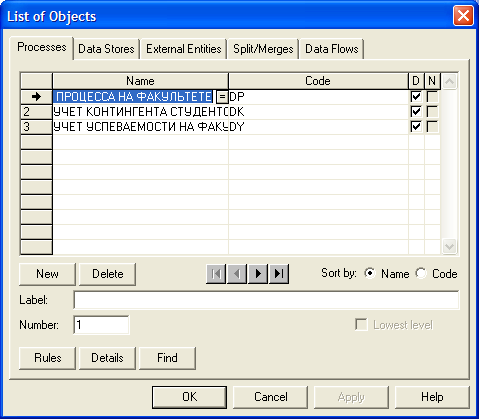
Рисунок 1.10 – List of Objects - список об'єктів системи
Список елементів даних, їхні коди, типи даних
Список елементів даних (List of Data Items) містить у собі словник по всіх атрибутах сутностей, які переміщуються потоками в межах моделі (рис. 1.11).
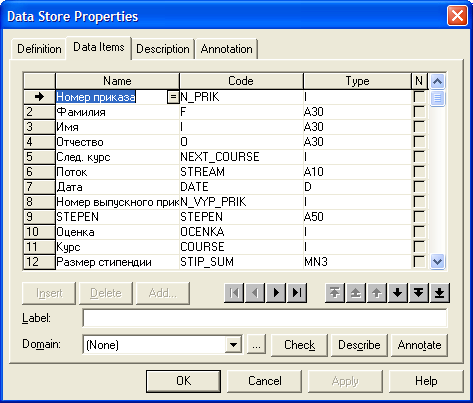
Рисунок 1.11 – List of Data items - список елементів даних
CRUD - матриця
CRUD-матриця (Create, Read, Update, Delete) відображає зв'язок між процесом і елементом даних, процесом і сховищем даних. Існує чотири типи зв'язку, тобто процес може здійснювати чотири типи операцій: створювати дані, читати, обновляти, видаляти. Якщо зв'язок існує - матриця її відображає (рис. 1.12).
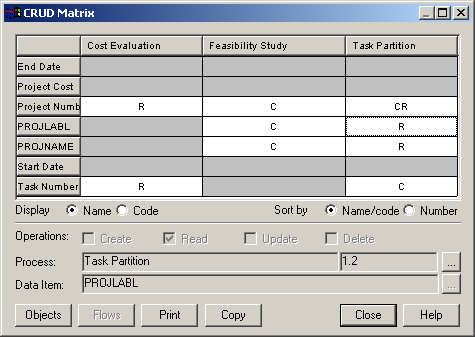
Рисунок 1.12 – CRUD-матриця
1.4.4.2.6 Перевірка моделі
Для здійснення орфографічної перевірки процесів, потоків, сховищ даних, зовнішніх сутностей необхідно в меню Dictionary викликати вікно Check Model чи натиснути гарячу клавішу F4. Звіт про перевірку надає розробнику інформацію про вид помилки і місце її перебування. Вікно зі звітом представлено на рис. 1.13.
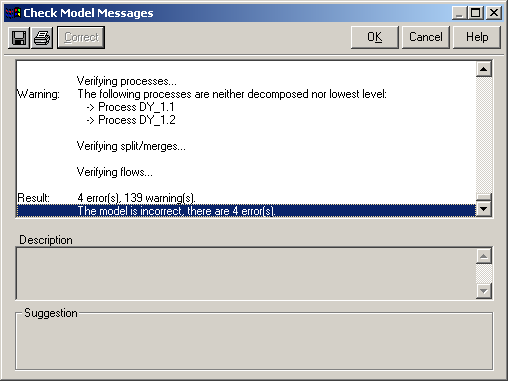
Рисунок 1.13 – Вікно зі звітом перевірки моделі
1.5 Зміст звіту
Звіт повинний містити:
Мету лабораторної роботи.
2. Порядок виконання лабораторної роботи.
Роздруківку отриманих результатів.
Висновки по роботі.
1.6 Контрольні запитання і завдання
Для чого призначений пакет PowerDesigner ProcessAnalyst?
Для чого потрібно настроїти шрифти пакета?
Що таке CRUD-матриця?
Що таке діаграма потоків даних?
На якому етапі методології SSADM використовується моделювання потоків даних?
Моделювання потоків даних при проектуванні ІКС організаційного типу
2.1 Мета роботи
Набуття практичних навичок проектування діаграм потоків даних реальних об'єктів і систем.
2.2 Організація самостійної роботи
У процесі підготовки до лабораторної роботи з даної теми необхідно вивчити теоретичний матеріал, використовуючи конспект лекцій і літературні джерела [1]. Підготувати матеріали для створення моделі потоків даних на 1-му, 2-му, 3-му рівнях.
2.3 Склад лабораторного устаткування
Лабораторна робота виконується на обчислювальному комплексі, у складі якого: локальна обчислювальна мережа комп'ютерів типу IBM PC, OC Windows98/2000/NT4.0.
2.4 Порядок виконання роботи
Більшість робіт, виконуваних у рамках SSADM-проекту, являють собою збір, обробку, перевизначення й опитування по найбільш важливих наборах даних. Тому важливо забезпечити простий і зручний доступ розроблювачів до цих матеріалів і їхнє спілкування між собою в процесі проектування.
Метод моделювання потоків даних використовується на стадіях аналізу вимог (модуль RA) і складання специфікацій вимог (модуль RS). За допомогою цього методу здійснюється моделювання й аналіз інформаційних потоків між процедурами обробки даних на структурно-функціональному рівні опису процесу функціонування існуючої чи проектованої систем.
В основі даної методології лежить побудова моделі аналізованої ІКС. Відповідно до методології модель системи визначається як ієрархія діаграм потоків даних (ДПД чи DFD), що описують асинхронний процес перетворення інформації від її введення в систему до видачі користувачу.
Діаграми верхніх рівнів ієрархії (контекстні діаграми) визначають основні процеси чи підсистеми ІКС із зовнішніми входами та виходами. Вони деталізуються за допомогою діаграм нижчого рівня. Така декомпозиція продовжується, створюючи багаторівневу ієрархію діаграм, доти не буде досягнутий такий рівень декомпозиції, на якому процеси стають елементарними і деталізувати їх далі неможливо.
Джерела інформації (зовнішні сутності) породжують інформаційні потоки (потоки даних), що переносять інформацію до підсистем чи процесів. Ті, у свою чергу, перетворюють інформацію і породжують нові потоки, які переносять інформацію до інших процесів чи підсистем, передаючі її накопичувачам даних чи зовнішнім сутностям-споживачам інформації. Таким чином, основними компонентами діаграм потоків даних є:
зовнішні сутності;
системи або підсистеми;
процеси;
накопичувачі даних;
потоки даних.
Програмний пакет PowerDesigner ProcessAnalyst забезпечує зручність рішення задач аналізу і проектування системи.
2.4.1 Зовнішні сутності (External Entity)
Зовнішня сутність являє собою матеріальний предмет чи фізичну особу, який є джерелом чи приймачем інформації. Наприклад, це можуть бути замовники, персонал, постачальники, клієнти, склад. Визначення деякого об'єкта чи системи як зовнішній сутності вказує на те, що вона перебуває за межами границь аналізованої ІС. В процесі аналізу деякі зовнішні сутності можуть бути перенесені усередину діаграми аналізованої ІС, якщо це необхідно, чи, навпаки, частина процесів ІС може бути винесена за межі діаграми і представлена як зовнішня сутність.
Зображується зовнішня сутність у виді еліпса (рис. 2.1), в який вписується ім'я цього об'єкта.
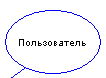
Рисунок 2.1 – Зовнішня сутність
Процес (Process)
Процес – це перетворення вхідних потоків даних у вихідні відповідно до визначеного алгоритму. Фізично процес може бути реалізований різними способами, це може бути підрозділ організації (відділ), що виконує обробку вхідних документів і випуск звітів, програма, апаратно реалізований логічний пристрій і т.д.
Представляється у виді прямокутника (рис. 2.2).

Рисунок 2.2 - Процес
Номер процесу служить для його ідентифікації. У поле імені вводиться найменування процесу як речення з активним недвозначним дієсловом у невизначеній формі (обчислити, розрахувати, перевірити, визначити, створити, одержати), за яким йдуть іменники в знахідному відмінку, наприклад:
"Ввести зведення про клієнтів";
"Видати інформацію про поточні витрати";
"Перевірити кредитоспроможність клієнта".
Використання таких дієслів, як "обробити", "модернізувати" чи "відредагувати" означає, як правило, недостатньо глибоке розуміння даного процесу і вимагає подальшого аналізу.
Інформація у полі фізичної реалізації показує, який підрозділ організації, програма чи апаратний пристрій виконує даний процес.
2.4.3 Сховища даних (Data Store)
Сховище даних - це абстрактний пристрій для збереження інформації, яку можна в будь-який момент помістити у сховище і через деякий час витягти, причому способи вміщення і витягу можуть бути різними.
Сховище даних може бути реалізовано фізично у виді мікрофіши, шухляди в картотеці, таблиці в оперативній пам'яті, файлу на магнітному носії і т.і. Сховище даних на діаграмі потоків даних зображується, як показано на рис. 2.3.

Рисунок 2.3 – Сховище даних
Сховище даних у загальному випадку є прообразом майбутньої бази даних і опис даних, що зберігаються в ньому, повинний бути ув'язаним з інформаційною моделлю.
2.4.4 Потоки даних (Data Flow)
Поток даних визначає інформацію, передану через деяке з'єднання від джерела до приймача. Реальний поток даних може бути інформацією, що передається кабелем між двома пристроями, пересилається поштою як листи, магнітними стрічками чи дискетами, що переносяться з одного комп'ютера на інший і т.д.
Поток даних на діаграмі зображується лінією зі стрілкою, що показує напрямок потоку (рис.2.4). Кожен поток даних має ім'я, що відображує його зміст.

Рисунок 2.4 – Поток даних
2.4.5 Сток або джерело інформації (Split/Merge)
Сполучний вузол між потоками показаний на рис. 2.5.
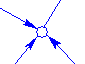
Рисунок 2.5 – (Split/Merge) сполучний вузол між потоками
Опис редактора
Головне вікно пакета призначене для відображення DFD і сервісних діалогових вікон.
У верхній частині екрана нижче назви пакета розташована лінійка головного меню. Під нею знаходиться основна інструментальна панель (Toolbar).
У лівому верхньому куті основної частини екрана розташовується вікно інструментів (Tools), що містить піктограми всіх базових елементів DFD і визначення можливих дій по їхній побудові.
2.4.6.1 Створення графічного об'єкта діаграми
Для створення графічного елемента діаграми потоків даних необхідно клацнути мишею на бажаний об'єкт, зображений на панелі Tools, і перенести його в головне вікно.
Як правило, створення ДПД починається зі створення процесу.
Для поміщеного у головне вікно об'єкта необхідно задати його властивості. Для цього потрібно подвійним щигликом миші викликати вікно Process Properties і вказати ім'я об'єкта і його код. У закладках Description і Annotation складається опис і анотація об'єкта відповідно.
2.4.6.2 Вилучення графічного об'єкта
Вилучення об'єкта відбувається шляхом виділення об'єкта і натискання клавіші Delete або по правій клавіші миші Edit -> Delete. При видаленні зовнішньої сутності і сховища (накопичувача) даних спливає вікно питання (рис. 2.5), де необхідно вказати - вилучається об'єкт з поточного рівня чи з моделі.
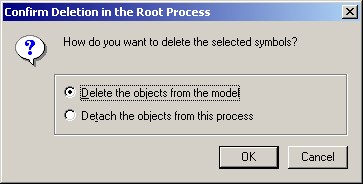
Рисунок 2.5 – Вікно питання
Якщо графічний об'єкт вилучений тільки з поточної ДПД, а не з МПД у цілому, то його можна відновити.
Редагування властивостей елементів діаграми
2.4.7.1 Властивості процесів. На рис. 2.6 представлене вікно заповнення властивостей процесу. У полі Name необхідно задати ім'я процесу, у полі Code - його код (латинськими буквами). Якщо цей процес не декомпозується, тоді необхідно позначити галочкою поле Lowest Level. На закладках Specification, Description і Annotation заповнюються специфікація процесу, його словесний опис і анотація, що згодом використовуються для полегшення розуміння моделі замовником, а також на інших стадіях проектування ІС.
2.4.7.2 Властивості потоків.
На рис. 2.7 наведене вікно властивостей потоку. Зміст полів Name, Code, закладок Description і Annotation аналогічний таким же полям у властивостях процесів. У полі Direction вибирається напрямок потоку. Якщо натиснути на кнопки, розташовані безпосередньо під об'єктами, з якими з'єднаний потік, ми викличемо властивості цих об'єктів. Вид закладки Data Items представлений на рис. 2.8.
Тут заповнюються елементи даних (Data Items). Це необхідно для того, щоб визначити ту інформацію, що передається в потоці. У наступному ця інформація буде використовуватиметься при створенні сховищ даних.
Якщо вже створено досить потоків, то можна використовувати вже створені елементи даних. Для цього служить кнопка “Add…”... На рис. 2.9 представлене вікно вибору готових елементів даних Data Items зі списку.
Для створення домена (домен – набір значень, для яких елементи даних дійсні) потрібно скористатися вікном Data Flow Properties, як показано на рис. 2.8. Потім увести список доменів у вікно List of Domains (рис. 2.10).
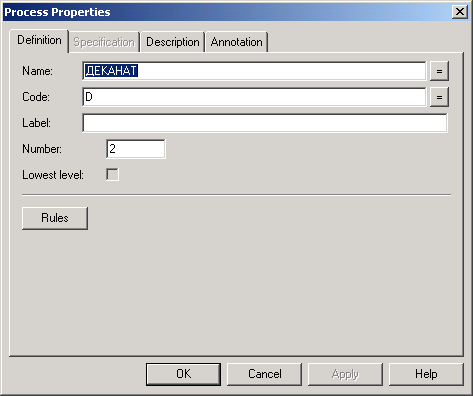
Рисунок 2.6 – Властивості процесу
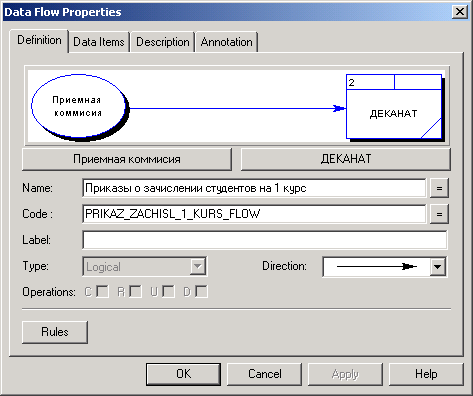
Рисунок 2.7 – Властивості потоку
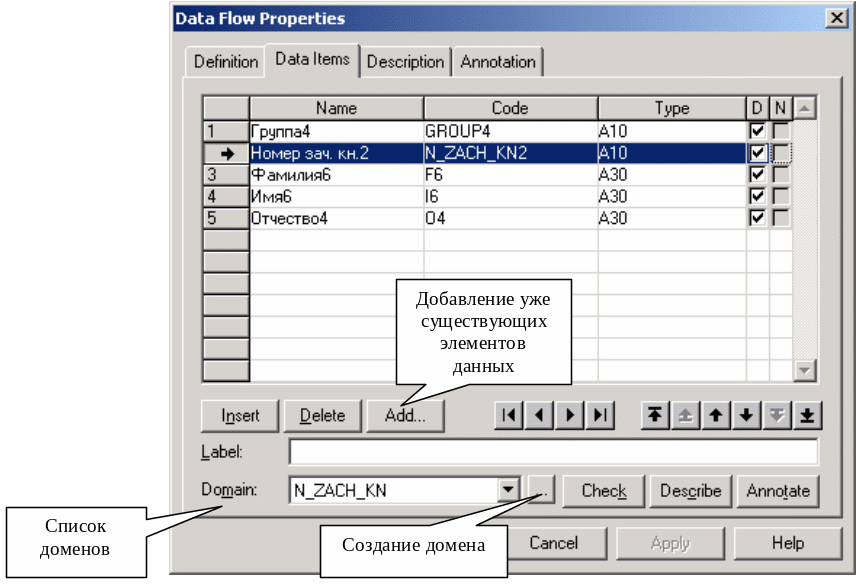
Рисунок 2.8 – Елементи даних інформаційного потоку
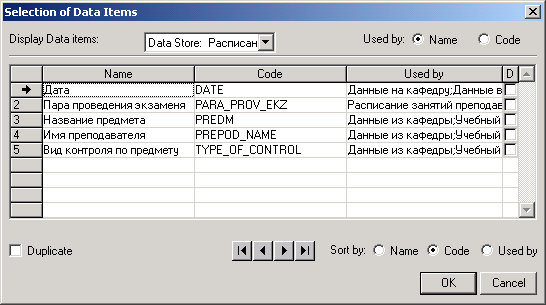
Рисунок 2.9 – Вікно Selection of Data items
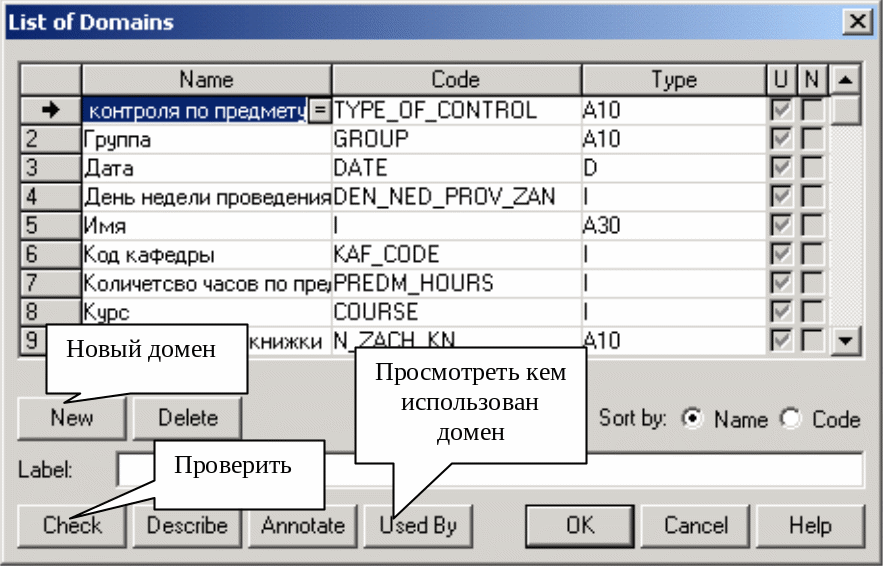
Рисунок 2.10 – Список доменів
У деяких випадках доцільно розділяти потоки. Це використовується як для зручності розуміння діаграми, так і для поділу інформації по потоках. Для цих цілей служить графічний елемент Split/Merge (рис. 2.5). При цьому у вікні властивостей (рис. 2.11) потрібно вказати - розділити інформацію по потоках (Partially Branching) чи пустити однакову інформацію за всіма потоками (Fully Branching).
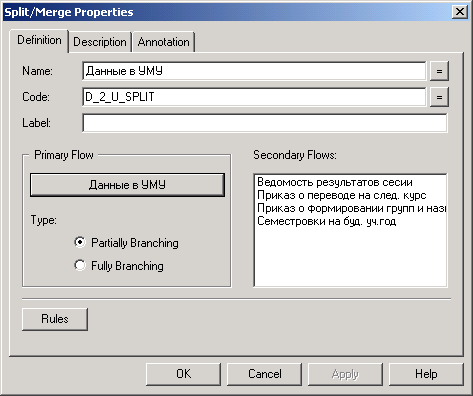
Рисунок 2.11 – Властивості Split/Merge
2.4.7.3 Властивості сховищ даних Data Stores.
На рис. 2.12 представлене вікно властивостей сховища даних. В ньому необхідно задати ім'я сховища, його код. Прапорець Is Entity (“Є сутністю”) необхідно зазначити, якщо це сховище даних використовуватиметься при проектуванні логічної моделі даних, тобто є сутністю ERD-діаграми, у протилежному випадку його відзначати не треба, і тоді сховище являє собою будь-який інший документ (аркуш паперу, книгу та ін.). Закладка Data Items відображає елементи даних, які є в цьому сховищі. Вони вносяться сюди автоматично на основі тих елементів даних, що присутні в потоках, з'єднаних з цим сховищем.
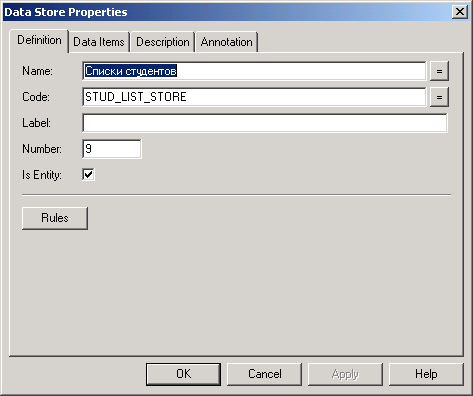
Рисунок 2.12 – Властивості сховища даних
Побудова ієрархії діаграм потоків даних
Для виконання лабораторної роботи необхідно одержати індивідуальне завдання відповідно до порядкового номеру в журналі групи.
Провести аналіз поставленої функціональної задачі.
Приступити до виконання лабораторної роботи.
Алгоритм побудови ієрархії діаграм потоків даних
Проектування моделі потоків даних починається з розробки контекстної діаграми. Цю діаграму зручно використовувати на початкових етапах як вихідні дані при дослідженні великих і складних систем. Контекстна діаграма, як правило, має топологію зірки, у центрі якої знаходиться головний процес, що з'єднується з приймачами і джерелами інформації, за допомогою яких із системою взаємодіють користувачі й інші зовнішні системи.
Розробка контекстних діаграм вирішує проблему строгого визначення функціональної структури ІС на самій ранній стадії її проектування, що особливо важливо для складних багатофункціональних систем, у розробці яких беруть участь різні організації і колективи розроблювачів.
Після побудови контекстної діаграми будується діаграма першого рівня. Як правило на цій діаграмі визначаються головні задачі, розв'язувані проектованою системою. Діаграма першого рівня використовується для визначення масштабу системи. При цьому враховуються зовнішні джерела і споживачі даних, головні системні входи і виходи, головні функціональні ознаки, а також границя між інформаційною системою і зовнішніми об'єктами.
Перевірка на повноту вихідних даних
Після побудови контекстної діаграми отриману модель варто перевірити на повноту вихідних даних про об'єкти системи та ізольованість об'єктів (відсутність інформаційних зв'язків з іншими об'єктами). Ці перевірки полягають у наступному:
1) ім'я кожного процесу повинне містити дієслово, що описує дію і одну мету;
2) усі потоки даних, зв'язані з одним процесом, повинні бути погоджені з іншими потоками;
3) чим менше інформації проходить між двома процесами, тим краще буде їхній поділ;
4) процеси не повинні бути джерелами даних чи їх споживачами;
5) до сховищ даних приєднуються вхідний і наслідуючий його потоки.
Побудова діаграм потоків даних (правило нумерації).
Для кожної із підсистем, що присутні на діаграмі першого рівня, виконується їх деталізація за допомогою ДПД. Кожен процес на ДПД, у свою чергу, може бути так само деталізований.
Розбивка означає уточнення процесу в деталях без порушення його взаємин із процесами, сховищами даних і зовнішніми об'єктами на попередніх рівнях опису. При деталізації повинні виконуватися такі правила:
правило балансування означає, що при деталізації підсистеми чи процесу діаграма, що деталізує, зовнішніми джерелами чи приймачами даних може мати тільки ті компоненти (підсистеми, процеси, зовнішні сутності, накопичувачі даних), з якими має інформаційний зв'язок деталізована підсистема чи процес на батьківській діаграмі;
правило нумерації означає, що при деталізації процесів повинна підтримуватися їхня ієрархічна нумерація. Наприклад, процеси, що деталізують процес із номером 12, одержують номера 12.1, 12.2, 12.3 і т.д
Мініспецифікація (опис логіки процесу) повинна формулювати його основні функції таким чином, щоб надалі фахівець, що виконує реалізацію проекту, зміг виконати чи розробити відповідну їй програму.
Мініспецифікація є кінцевою вершиною ієрархії ДПД.
Після побудови закінченої моделі системи її необхідно перевірити на повноту і погодженість. У повній моделі всі її об'єкти (підсистеми, процеси, потоки даних) повинні бути докладно описані і деталізовані. Виявлені недеталізовані об'єкти варто деталізувати, повернувши на попередні кроки розробки. У погодженій моделі для всіх потоків даних і накопичувачів даних має виконуватися правило збереження інформації: усі дані, що будь-куди надходять – маєть бути зчитані, а всі дані, що зчитуються - записані.
2.5 Зміст звіту
1. Ціль роботи.
2. Опис етапів виконання роботи.
3. Короткий опис результатів виконаної роботи.
4. Роздруківка отриманих результатів.
5. Висновки по роботі.
2.6 Контрольні запитання
1. Що таке контекстна діаграма?
2. Що таке ієрархія діаграм потоків даних?
3. Які основні компоненти присутні в СПД? Охарактеризуйте їх.
4. Що таке елемент даних? Для чого він використовується?
5. Які бувають сховища даних?
3 Реконструювання ієрархії моделі потоків даних
3.1 Мета роботи
Аналіз існуючої моделі потоків даних і групування процесів, що працюють з однаковими даними. Використання засобів імпорту і документування розроблювальної інформаційної системи.
3.2 Організація самостійної роботи
У процесі підготовки до лабораторної роботи з даної теми необхідно вивчити теоретичний матеріал стосовно логічного моделювання даних, використовуючи конспект лекцій і літературні джерела [1,3]. Підготувати матеріали щодо створення логічної структури даних для об’єкту моделювання, враховуючи результати моделювання потоків даних для цього об’єкту.
3.3 Склад лабораторного устаткування
Лабораторна робота виконується на обчислювальному комплексі, у складі якого: локальна обчислювальна мережа комп'ютерів типу IBM PC, OC Windows98/2000/NT4.0.
3.4 Порядок виконання роботи
Створену модель потоків даних необхідно проаналізувати і створити матрицю перехресних посилань з метою групування процесів, що використовують ті ж самі дані. Засіб імпорту/експорту дозволить значно спростити побудову логічної моделі даних. Створення проектної документації - одна з головних задач при проектуванні. При цьому необхідно, щоб контролювалися відповідність документації проекту, взаємозв'язок документів, забезпечувалося їхнє своєчасне відновлення.