

9.1.Вопросы к разделу 3.2
1. Какие типы отказоустойчивости существуют в сложных систем?
2. Назовите критерии отказоустойчивости сложных систем.
3. Чем отличается абсолютная отказоустойчивость от негарантированной?
4. Чем отличается гарантированная отказоустойчивость I от гарантированной отказоустойчивости II?
5. Дайте определение активной отказоустойчивости сложных систем.
6. Дайте определение пассивной отказоустойчивости сложных систем.
7. Что такое параметрическая избыточность?
8. Чем отличается параметрическая избыточность от временной?
9. В чем сущность алгоритмической избыточности?
10.Способы обеспечения отказоустойчивого функционирования вс
Ниже обзорно рассмотрены средства устранения последствий отказов и сбоев, а также основные способы восстановления процесса обработки данных. В общем же случае процесс функционирования отказоустойчивой ВС может быть представлен схемой на рисунке 3.3.1.
Важным с точки зрения функционирования ВС является повышение показателей надежности отдельного узла (вычислительного модуля (ВМ)) ВС, это достигается блокированием воздействий отказавших компонентов и их оперативной заменой:
отказ процессора – использование многопроцессорных конфигураций;
отказ памяти – использование кодов с обнаружением и исправлением ошибок;
отказ дисков – применение RAID технологий, а также горячей замены (без прерывания функционирования компьютера) отказавших дисков и контроллеров;
отказ питания и охлаждения – использование резервных блоков питания и блоков вентиляторов, источников бесперебойного питания, а также горячей их замены.
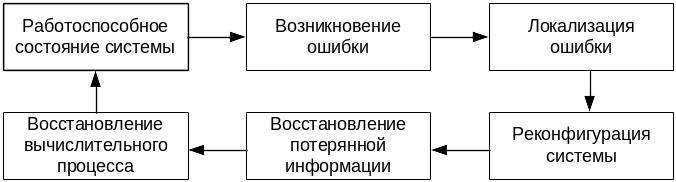
Рисунок 3.3.1. Последовательность функционирования отказоустойчивой ВС
Объединение таких элементов в ВС создает следующий уровень обеспечения надежности – взаимное контролирование узлами друг друга с целью парирования ошибочных действий персонала, адекватной реакции на изменение внешней среды и т.д.
Коэффициент готовности отдельного ВМ без применения средств блокирования последствия отказов обычно 0,99. Это составляет около 4 дней в году. Объединение ВМ в систему и применение вышеперечисленных мер позволяет довести коэффициент готовности до 0,9999, что сводит простой ВС к нескольким минутам в год.
Основные подходы к обеспечению отказоустойчивости
Обеспечение отказоустойчивости ВС включает решение следующих проблем:
1) обнаружение сбоя или отказа программно-аппаратных средств;
2) диагностирование сбоя или отказа и устранение влияния отказа;
3) восстановление работоспособности путем использования для продолжения функционирования признанных работоспособными процессоров и протекающих на них прикладных программ либо путем перезапуска общесистемных и прикладных программ на реконфигурированной ВС.
Каждая из вышеперечисленных проблем может решаться разными методами, причем программно-аппаратные затраты на ее решение зависят от интервала времени, допустимого по условиям эксплуатации ВС, от момента сбоя или отказа до момента восстановления работоспособности.
3.3.1. Диагностическое тестирование вс
Тестирование ВС может строиться как на основе тестов самопроверки ВМ, так и на базе тестовой взаимной проверки ВМ друг друга или использования комбинации этих подходов. Рассмотрим подход к тестированию на основе взаимной проверки ВМ друг друга.
Итак, будем полагать, что каждый ВМ может запустить по линку диагностический тест в соседним с ним ВМ путем передачи в него теста и удаленного запуска тестирования с возвращением результата тестирования. Если ВМ, производящий тестирование, исправен, то он делает правильное заключение о работоспособности подвергшегося тестированию ВМ. Если неисправный ВМ тестирует соседний ВМ, то результат тестирования – произвольный. Соседний ВМ может быть признан как исправным, так и неисправным.
При взаимном тестировании ВМ может образовывать подсистемы ВМ, имеющих одно и то же заключение об исправности друг друга. Тестирование инициируется в одном или нескольких ВМ независимо друг от друга по собственному таймеру или каким-либо иным способом. Пусть ВМi тестирует соседний ВМk и признает его исправным, затем ВМk тестирует ВМi. Если ВМk признает ВМi исправным, то они образуют подсистему из двух ВМ, имеющих одинаковое представление об исправности друг друга. Далее каждый из включённых в подсистему ВМ пытается включить в нее все соседние с ним ВМ. При этом несколько независимо строящихся подсистем могут объединяться в одну, если ВМ, входящие в них, имеют одинаковое представление об исправности друг друга. При этом в ходе тестирования ВМ подсистемы обмениваются сообщениями, на основании которых подсчитывается число ВМ, включенных в подсистему. В предположении одновременного существования в ВС не более чем m неисправных ВМ, все ВМ, имеющие заключение друг о друге как об исправном ВМ, при числе ВМ подсистемы, превышающем m признаются исправными. Эта подсистема образует диагностическое ядро, используемое для тестирования остальных ВМ системы.
Выделение диагностического ядра ускоряет и упрощает тестирование ВС. ВМ диагностического ядра уже не нуждаются во взаимопроверке, а просто делают заключение об исправности остальных ВМ.
3.3.2. Способы и средства устранения последствий ошибок и отказов в ВС
Как известно, простейшим способом устранения ошибок является повторение вычислений. Однако он позволяет устранить только ошибки, вызванные сбоями, и требует значительных затрат машинного времени. Поэтому в практике используют два основных способа устранения последствий отказов и ошибок в работе ВС:
маскирование ошибочных действий;
реконфигурация системы.
Классификация способов устранения последствий отказов и ошибок приведены на рисунке 3.3.2.
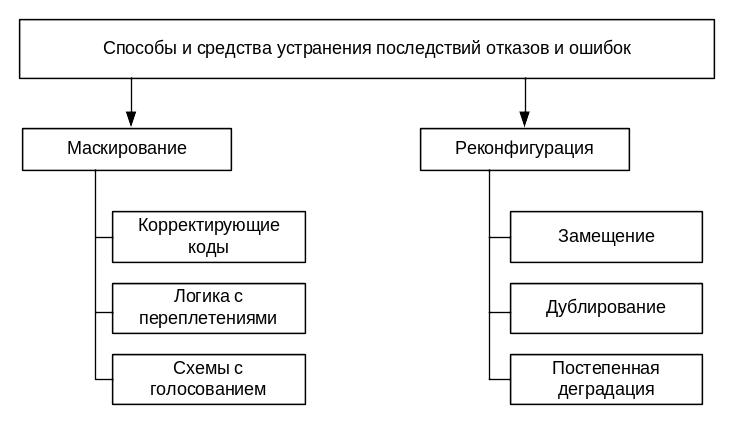
Рисунок 3.3.2. Классификация способов и средств устранения последствий ошибок и отказов
Суть первого способа состоит в том, что избыточная информация скрывает действие ошибочной информации за счет особенностей схемных решений и организации процесса обработки данных. При этом используются средства устранения последствий ошибок – средства маскирования, которые делятся по принципу действия на следующие группы:
корректирующие коды (коды Хэмминга, итеративные коды, AN-коды);
логика с переплетениями;
схемы с голосованием (используется нечетное число блоков, выполняющих одни и те же вычислительные операции, и большинством «голосов» определяется правильный набор выходных данных).
Соответственно возможные альтернативы использования этих методов определяются тем, что предпочтительнее:
1) затратить больше ресурсов и медленнее, чем максимально возможно, выполнять программу, выявляя сбои и отказы,
2) выполнять программу с максимально возможной скоростью (без избыточных обменов и ВМ) и проводить через некоторые промежутки времени тестирование на предмет выявления отказов.
Выбор между этими альтернативами следует производить с учетом того, что ресурсы, затрачиваемые на обнаружение сбоев и отказов, могут быть использованы для ускорения параллельного выполнения программы, что, в свою очередь, ведет к образованию временной избыточности. Последняя может быть также использована для повышения отказоустойчивости. Например, временная избыточность позволяет повторять вычисления и сравнивать результаты, что выявляет сбои при исполнении программы.
Реконфигурация системы заключается в изменении состава средств обработки информации или способа их взаимодействия. Реконфигурация производится после выявления отказа. Этот способ устранения последствий ошибок и отказов включает:
статическую реконфигурацию;
динамическую реконфигурацию.
Статическая реконфигурация системы осуществляется путем отключения отказавших компонентов. При этом система делится на две части: активную, участвующую в работе, и пассивную, охватывающую неработоспособные компоненты системы и отключенные в ходе реконфигурации.
Динамическая реконфигурация по принципу проведения делится на следующие виды:
замещение (поддержка запасом);
дублирование;
постепенная деградация системы (снижение функциональных способностей).