

1.2 Общая классификация вычислительных систем обработки данных – архитектур
Классифицировать системы, в том числе и вычислительные, можно по одному или нескольким характерным признакам. В зависимости от этого классификационная структура может выглядеть совершенно по-разному. Если классифицировать системы обработки данных по способу построения, то есть в том порядке, как они здесь представлены, классификация будет выглядеть как на рисунке 1.6.
Все системы обработки данных можно разделить на два класса. Отдельные ЭВМ, вычислительные комплексы или специализированные системы образуют класс сосредоточенных (централизованных) систем, в которых реализуется вся обработка данных.
Т огда
системы телеобработки и вычислительные
сети следует отнести к классу распределенных
систем,
где обработка данных рассредоточена
по многим составляющим системы. При
этом сис-
огда
системы телеобработки и вычислительные
сети следует отнести к классу распределенных
систем,
где обработка данных рассредоточена
по многим составляющим системы. При
этом сис-
темы телеобработки относят к распределенным до некоторой степени условно, поскольку обработка реализуется централизованно, на одной ЭВМ или вычислительном комплексе.
Вопросы и упражнения для самопроверки
Дайте определение архитектуры вычислительных средств.
Поясните содержание слова «система» в контексте этой книги.
Какие вычислительные средства составляют систему обработки данных?
Какое содержание вкладывают в понятие «косвенная связь» в многомашинном вычислительном комплексе?
Сколько процессоров может включать многопроцессорная система? Какую линию связи называют моноканалом?
Что является ядром вычислительной сети?
Чем отличаются определения вычислительных комплексов и вычислительных систем?
Какие вычислительные системы образуют класс сосредоточенных систем, а какие – распределенных?
Каковы корни слова «телеобработка»?
Общие концепции архитектур

2.1 Состав и функционирование
Системы обработки данных строятся на основе технических и программных средств, существенно различающихся по своей природе. Функционирование систем реализуется через взаимодействие тех и других ее составляющих.
Технические средства. Основой систем обработки данных является оборудование – технические средства, предназначенные для ввода, обработки, сохранения и вывода данных. Состав технических средств и связи между ними, определяют структуру и порядок их взаимодействия, по-другому говоря – конфигурацию системы. Для математического описания структуры и взаимодействия ее элементов используется геометрическое ее описание (представление), называемое графом. Вершины графа соответствуют элементам системы, а линии, соединяющие вершины – дуги, отражают взаимоотношения между элементами системы. Инженерная форма представления структуры называется схемой. Таким образом, граф и схема тождественны по содержанию, но различны по форме. В схеме для изображения элементов используются различные геометрические элементы – условные графические изображения, а для изображения связей – линии многих типов. За счет этого схема приобретает большую, по сравнению с графом наглядность и информативность. К основным элементам технических средств структуры нужно отнести: процессоры, запоминающие устройства – память, устройства ввода-вывода, устройства сопряжения и целый ряд других. Устройства связываются с помощью, так называемых, интерфейсных схем и совокупностей линий связи или каналов передачи данных.
Пример структуры в виде двухмашинного вычислительного комплекса представлен на рисунке 1.1.
Число входящих в систему устройств может оказаться достаточно большим, так что представляемая с их помощью структура будет трудна для понимания – выйдет за рамки возможностей методов исследования, используемых при анализе и синтезе системы.
В таких случаях структуру описывают на укрупненном уровне, ис-пользуя в качестве элементов ЭВМ, вычислительные комплексы или многопроцессорные комплексы, представляемые (изображаемые) одной вершиной графа. Элемент структуры – это понятие, но не физическое свойство объекта. Главное в изображении структу-ры – информативность. В связи с процессами обработки данных (информации) технические средства рассматриваются как совокупность ресурсов двух типов: устройств и памяти. Устройство – ресурс, используемый для преобразования и ввода-вывода данных, разделяемый между процессами (задачами) во времени. Примеры устройств: процессоры, каналы ввода-вывода, периферийные устройства и каналы передачи данных. В каждый момент времени устройство используется одним процессом, реализуя соответствующие операции: обработку (преобразование) или ввод-вывод данных. Основная характеристика устройства – производительность, определяемая числом операций, выполняемых в единицу времени или пропускная способность (скорость), определяемая числом единиц информации (битов), передаваемых в единицу времени, обычно секунду. Память – ресурс, используемый для хранения данных и разделяемый между процессами по объему и времени. Примерами этого типа ресурса являются оперативная память и накопители на магнитных дисках. Основной характеристикой ресурса является емкость, определяемая предельным количеством информации, размещаемой в памяти. В памяти могут одновременно размещаться данные, относящиеся к нескольким процессам. Накопители на магнитных дисках представляют два типа ресурсов, являясь памятью и устройствами, обслуживающими операции ввода-вывода данных.
Таким образом, технические средства и именно их состав, определяют номенклатуру ресурсов, используемых для хранения, ввода-вывода и преобразования данных. Конфигурация связей между устройствами определяет пути передачи данных в системе и порядок доступа процессов к устройствам и данным, хранимым в памяти.
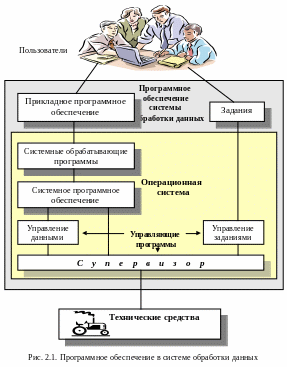
Программное обеспечение. Требуемый набор функций, определяемых назначением системы обработки данных, обеспечивается совокупностью программ, составляющих программное обеспечение системы обработки данных. Схематически «место» программного обеспечения в системе обработки данных можно изобразить в виде некоторой структуры, представленной на рисунке 2.1.
Технические средства системы обработки данных обеспечивают реализацию элементарных функций – операций ввода-вывода, хранения и преобразования данных, которые выполняются с помощью электрических схем и средств микропрограммного управления. Функции, реализуемые техническими средствами, как
это можно увидеть на схеме (рисунок 2.1), относятся к нижнему уровню иерархии. Функции более высоких уровней сложности обеспечиваются программным обеспечением, включающим в себя операционную систему и прикладное программное обеспечение. Рассмотрим подробнее структуру программных средств системы обработки данных.
Операционная система (ОС) – это совокупность программ, предназначенных для управления работой всей системы обработки данных и реализации наиболее массовых процедур взаимодействия с пользователями, операций ввода-вывода, хранения и преобразования данных.
Управление работой системы сводится к управлению процессами и ресурсами, обеспечивающему эффективное использование
оборудования и требуемое качество обслуживания пользователей. Функции управления реализуются управляющими программами ОС, включающими в свой состав супервизор, программы управления заданиями и данными.
Супервизор контролирует состояние всех технических средств и процессов (задач) системы и управляет ими, обеспечивая необходимый режим обработки данных путем распределения процессов в пространстве и времени.
Супервизор выделяет задачам области (разделы) памяти и запрашиваемые устройства ввода-вывода, инициирует выполнение процессором программ, начинает операции ввода-вывода и обрабатывает сигналы прерываний, отмечающие окончание операций ввода-вывода и особые ситуации, возникающие при выполнении программ и работе устройств.
Программы управления заданиями обеспечивают ввод и интерпретацию команд операторов, управляющих работой и заданий (программ), формируемых пользователями системы обработки данных. Операторы с помощью специальных команд воздействуют на порядок функционирования и получают информацию о текущем состоянии системы. Эти программы интерпретируют задания в виде соответствующих последовательностей действий и обеспечивают их необходимыми ресурсами – требуемым объемом оперативной памяти, устройствами ввода-вывода, наборами данных и др. Задания, обеспеченные ресурсами, необходимыми для их выполнения, образуют задачи. Управление задачами реализуется супервизором. Для того, чтобы заставить работать программы управления заданиями, последние описываются с применением специального языка управления заданиями, конкретного для каждого типа системы обработки данных.
Программы управления данными обеспечивают доступ к наборам данных и организацию работы устройств ввода-вывода. Средства управления данными настраивают программы на работу с конкретными наборами данных и устройствами, в которых хранятся наборы, и за счет этого создают возможность при программировании задач манипулировать с данными как с логическими объектами, не связанными с конкретными устройствами. Таким образом, управление данными сводится к сопряжению программ с наборами данных и устройствами, а использование этих устройств контролируется и координируется супервизором.
Функции ОС расширяются за счет включения в нее программных средств телеобработки, управления базами данных, программных средств, обеспечивающих работу в различных сетях и др., образующих в совокупности системное программное обеспечение. Системное программное обеспечение является основой для построения прикладного программного обеспечения и предоставляет пользователю средства, необходимые для работы со специ-
альными устройствами, например, с аппаратурой передачи данных и удаленными терминалами или для специальной обработки дан-ных.
В состав ОС включают, как правило, трансляторы с нескольких языков программирования, редакторы связей, обеспечивающие сборку программных модулей в программы с заданной структурой; средства отладки программ и перемещения наборов данных с одних носителей на другие и т.д. Функции трансляторов обеспечивают взаимодействие вычислительных средств и программ, разработанных с использованием машинно-, процедурно- и проблемно- ориентированных языков программирования.
Прикладное программное обеспечение реализует функции обработки данных, связанных с конкретной областью применения системы. Например, в системах автоматизированного проектирования радиоэлектронной аппаратуры прикладные программы обеспечивают анализ и расчет электронных схем, размещение электронных компонентов по конструктивным единицам, разводку соединений на печатных платах и другие работы; в автоматизированных системах управления предприятиями и производствами – стратегическое, тактическое и оперативное планирование, учет и анализ производственной деятельности и т.д.
Состав прикладного программного обеспечения определяется назначением системы.
К программным средствам систем обработки данных примыкают наборы данных, рассматриваемые как особая составляющая – информационное обеспечение систем. Наборы данных представляют собой совокупности логически связанных элементов данных, организованных соответствующим образом (по определенным правилам), снабженных описаниями, доступными системам программирования (средствам управления данными). Наборы данных могут быть именованы, что позволяет обращаться к ним и их элементам по именам. Одни и те же наборы данных могут использоваться многими прикладными программами, что достигается организацией их в виде специальных структур, независимых от программ – баз или банков данных.
Работа с такими данными реализуется с помощью систем управления базами данных, позволяющих производить их выборку, модификацию, добавление новых данных. При этом, изменения в программах не влекут за собой изменение и реорганизацию базы данных, не требуют внесения изменений в программы, оперирующие с ними.
Процессы. Процессы отображают динамику работы - функционирование систем обработки данных. Процесс определяют как динамический объект, реализующий целенаправленный акт обработки данных, то есть некоторое действие, приводящее к изменению текущего состояния системы или ее элементов. Основные
функции систем обработки данных реализуются через прикладные процессы, заданные прикладными программами или обрабатывающими программами ОС, и инициируются заданиями пользователей или сигналами, поступающими в систему из внешней среды. В качестве примеров прикладных процессов можно назвать: решение прикладной задачи; редактирование, трансляция или сборка прикладной программы; сортировка набора данных и др. Системные процессы реализуют вспомогательные функции, обеспечивающие работу системы обработки данных, например, системные ввод или вывод, перемещение страниц в виртуальной памяти, работа супервизора и т.д. Системные процессы работают от момента включения до момента выключения системы обработки данных.
Процесс
Pi
описывается тройкой параметров
![]() Pi
= <ti,
Ai,
Ti>,
где ti
–
момент
инициирования процесса, Ai
-
атрибуты процесса, определяющие имена
источника, инициирующего процесс,
пользователя, задания, режим обработки
данных, приоритет процесса и др., и Ti
– трасса
процесса. Трасса процесса – это
последовательность событий, связанных
с изменением состояния процесса. Трасса
процесса представляется в виде
упорядоченного множества событий Ti
= {s,,
s2,
…, sM},
имевших
место в моменты времени t1,
t2,
…, tM,
причем,
t1
t2…
tM.
К
событиям относятся моменты времени
ввода задания, начала и завершения
обработки шагов задания, начала и
окончания выполнения процессов в
устройствах системы, начала использования
и освобождения памяти, предоставляемой
процессу в запоминающих устройствах и
др. Каждое событие связывается с моментом
его возникновения, программой, реализующей
процесс и ресурсом, обслуживающим
процесс. Таким образом, трасса характеризует
развитие процесса во времени и
пространстве, его динамику. На рисунке
2.2 изображено выполнение программы
процессором и неким внешним устройством
в виде временной диаграммы.
Pi
= <ti,
Ai,
Ti>,
где ti
–
момент
инициирования процесса, Ai
-
атрибуты процесса, определяющие имена
источника, инициирующего процесс,
пользователя, задания, режим обработки
данных, приоритет процесса и др., и Ti
– трасса
процесса. Трасса процесса – это
последовательность событий, связанных
с изменением состояния процесса. Трасса
процесса представляется в виде
упорядоченного множества событий Ti
= {s,,
s2,
…, sM},
имевших
место в моменты времени t1,
t2,
…, tM,
причем,
t1
t2…
tM.
К
событиям относятся моменты времени
ввода задания, начала и завершения
обработки шагов задания, начала и
окончания выполнения процессов в
устройствах системы, начала использования
и освобождения памяти, предоставляемой
процессу в запоминающих устройствах и
др. Каждое событие связывается с моментом
его возникновения, программой, реализующей
процесс и ресурсом, обслуживающим
процесс. Таким образом, трасса характеризует
развитие процесса во времени и
пространстве, его динамику. На рисунке
2.2 изображено выполнение программы
процессором и неким внешним устройством
в виде временной диаграммы.
П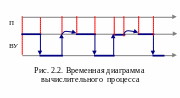 роцесс
функционирования системы обработки
данных существенно зависит от состава
заданий, исходных данных и внешних
сигналов, поступающих на ее входы. Весь
объем входящей информации принято
называть рабочей
нагрузкой
системы, обработка которой требует
определенных ресурсов, таких, например,
как оперативная и внешняя память,
процессорное время, количество и типы
устройств ввода-вывода и др. Поэтому
рабочую нагруз-ку в промежутке времени
Т,
определяют в виде множества характеристик
заданий
роцесс
функционирования системы обработки
данных существенно зависит от состава
заданий, исходных данных и внешних
сигналов, поступающих на ее входы. Весь
объем входящей информации принято
называть рабочей
нагрузкой
системы, обработка которой требует
определенных ресурсов, таких, например,
как оперативная и внешняя память,
процессорное время, количество и типы
устройств ввода-вывода и др. Поэтому
рабочую нагруз-ку в промежутке времени
Т,
определяют в виде множества характеристик
заданий
![]() ,
(2.1)
,
(2.1)
где li – описание i-го задания, устанавливающее его атрибуты Ai и потребность задания в ресурсах от 1 до N. Например, значение может означать емкость области оперативной памяти, необходимой заданию, - требуемое число выполняемых процессором операций, - количество вводимых данных и т.д. Число заданий, обрабатываемых за определенный промежуток времени системой, дающих полное представление о рабочей нагрузке, может быть достаточно большим. В связи с этим, описание рабочей нагрузки в виде зависимости (2.1) оказывается, как правило, громоздким. Для более компактного описания рабочей нагрузки потребность в ресурсах представляется среднестатистическими значениями объема ресурсов, приходящихся на одно задание. Имеет значение и сфера применения, определяющая класс задач (сложность). Например, инженерно-технические, планово-экономические, учетно-статистические задачи представляют для системы обработки данных различные рабочие нагрузки.
2.2 Характеристики и параметры
Главной задачей разработчиков систем обработки данных является обеспечение соответствия системы своему назначению. Степень соответствия системы своему назначению определяет ее качество, называемое так же эффективностью системы. Системы обработки данных являются очень сложными, и для них определение эффективности является также сложной задачей. Одной величиной определить эффективность такой системы просто невозмож-но, поэтому пытаются это сделать с помощью набора величин, каждая из которых связана с определенным свойством или свойствами системы, в совокупности называемых характеристиками системы. Из всего набора характеристик стараются выделить некоторую их совокупность, которая давала бы наиболее полное представление об эффективности системы. В качестве наиболее весомых и информативных характеристик приняты и выделены:
- производительность;
- время ответа системы;
- надежность;
- стоимость.
В дополнение к ним используются: габариты, масса, потребляемая мощность, диапазон рабочих температур, ремонтопригодность и целый ряд других.
Характеристики зависят от организации системы, от структу-ры, состава программного обеспечения, режима функционирования системы и др. Эффективность системы, иначе, ее характеристики, выражаются через некоторые величины, показатели, определенные
как параметры системы. Параметры представляют в виде неких математических объектов, определяющих, например, число и быстродействие устройств, емкость памяти, рабочую нагрузку и др. Математические объекты могут представляться также в виде множеств, графов, алгоритмов и т.д. В число параметров включаются все объекты, характеризующие первичные аспекты организации системы и существенно влияющие на характеристики.
Таким образом, характеристики определяют свойства системы как единого целого, представляемого соответствующим набором параметров. В математическом аспекте характеристики можно рассматривать как наименования функций, реализуемых системой, аргументами которых являются все те же параметры.
Рассмотрим, каким образом, и, с помощью каких параметров можно оценить влияние на основные, перечисленные выше, характеристики систем.
2.2.1 Производительность
Производительность характеризует вычислительную мощность системы, определяемую количеством вычислительной работы, выполненной в единицу времени. Общепринятой методики оценки производительности пока не существует, что связывается с отсутствием единиц измерения количества вычислительной работы, поэтому для оценки производительности используется достаточно большое число показателей, которые ни в отдельности, ни в совокупности не удовлетворяют потребностям теории, практики и эксплуатации систем обработки данных.
Поскольку, с одной стороны, эта характеристика является очень важной для любой отдельной ЭВМ, а тем более для системы, с другой стороны, представляют интерес «исторические» и совре-менные подходы ее количественной оценки. Стоит рассмотреть различные варианты и рассуждения по данной проблеме. Можно, например, оценить производительность через быстродействие устройств, составляющих систему обработки данных. Технические средства любой системы обработки данных, такие как ЭВМ и периферийное оборудование, обладают производительностью вне связи с операционной системой, программным обеспечением и режимом эксплуатации системы. Производительность технических средств оценивается их быстродействием – числом операций, выполняемых в секунду.
Совокупность
значений V=(![]() ),
определяющих быстродействие устройств
1, …, N,
входящих в состав системы, характе-ризует
номинальную
производительность системы.
Номинальная производительность
характеризует только потенциальные
возможности устройств, которые не могут
быть использованы полностью
),
определяющих быстродействие устройств
1, …, N,
входящих в состав системы, характе-ризует
номинальную
производительность системы.
Номинальная производительность
характеризует только потенциальные
возможности устройств, которые не могут
быть использованы полностью
из-за влияния структурных связей и организации взаимодействия между ними, что проявляется в изменении скорости работы одних устройств при работе других. Так, суммарная производительность устройств ввода-вывода, подключенных к мультиплексному каналу, ограничена пропускной способностью канала, а фактическая производительность накопителей на магнитных дисках, подключенных к такому же каналу, меньше их суммарного номинального быстродействия и т.д.
Чтобы оценка номинальной производительности была по возможности простой, стремятся уменьшить число составляющих элементов в наборе ( ). При этом, во-первых, быстродействие устройств, выполняющих одинаковые операции и способных работать параллельно, можно представить суммарным быстродействием, то есть в виде набора значений. Например, быстродействием процессоров 1,2 млн. операций в секунду или быстродействием внешней памяти 2000 обращений в секунду, скоростью ввода - 6 тыс. символов в секунду и т.д. Во-вторых, быстродействие некоторых устройств можно считать несущественным, не влияющим в целом на производительность. Так, быстродействием внешней памяти и устройств ввода-вывода можно пренебречь, и тогда номинальную производительность можно характеризовать только суммарным быстродействием процессоров системы.
Чтобы
оценить влияние структуры системы на
быстродействие устройств, используется
специальная характеристика – комплексная
производительность.
Комплексная производительность
оценивается набором быстродействий
устройств
![]() ,
обеспечиваемых при их совместной работе,
то есть в составе комплекса технических
средств. По описанным выше причинам,
комплексная
,
обеспечиваемых при их совместной работе,
то есть в составе комплекса технических
средств. По описанным выше причинам,
комплексная
производительность ниже номинальной: V1*V1, …, VN*VN. Комплексную производительность можно оценить, например, с помо-
щью искусственно синтезированной программы, порождающей процесс с заданной смесью операций, при прогоне которой измеряется время ее выполнения.
Кроме параметра, характеризующего быстродействие устройства, существует некое понятие, определяющее занятость конкретного устройства по отношению ко времени работы всей системы – называмое загрузкой. Загрузка i-го устройства определяется отношением i= Ti/T, где Ti – время, в течение которого устройство работало, и T – продолжительность работы системы в целом. В течение промежутка времени T-Ti устройство простаивает.
Очевидно, что загрузка i 1. Если загрузка устройств 1, …, N равна 1, …, N соответственно, то количество работы, выполняемой устройствами с быстродействием V1, …, VN за единицу времени, равно 1V1, …, NVN. Совокупность значений 1V1, …, NVN характеризует производительность технических средств с
учетом простоев, возникающих в процессе функционирования системы. Таким образом, оценка фактической производительности системы сводится к оценке загрузки устройств в конкретных условиях работы системы.
На загрузку устройств оказывают влияние управляющие программы операционной системы в связи с необходимостью обслуживания устройств ввода-вывода (участие процессора и запоминающих устройств для промежуточного хранения информации). Такая же ситуация возникает при использовании режима разделения времени и других вспомогательных функций.
Оценку влияния операционной системы на производительность предложили характеризовать системной производительностью. Системную производительность определили также набором 1V1, …, NVN, в котором загрузка 1, …, N определена при работе технических средств под управлением операционной системы. С учетом затрат времени на различные вспомогательные функции, системная производительность оказалась ниже комплексной (1V1V1*, …, NVNVN*) и, следовательно ниже номинальной (1V1V1, …, NVNVN).
Для систем обработки данных, находящихся в эксплуатации или разрабатываемых для конкретного применения, введен еще один вид количественной оценки системной производительности. В данном случае определен класс задач, по крайней мере, статически, то есть, определена рабочая нагрузка, и производительность оценивается числом задач, решаемых в единицу времени - задач/час. Эта оценка ни о чем не свидетельствует, если не опреде-лен класс решаемых задач, по-другому, она не может применяться для сравнения систем, работающих с различными наборами задач.
Тем не менее, пусть за время T система завершила обработку n задач или заданий. Тогда производительность системы за время T составит:
![]() (2.2)
(2.2)
задач в единицу времени, например, в час.
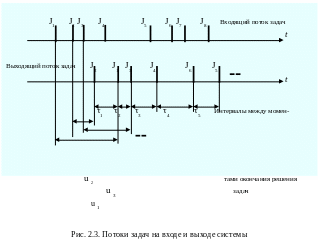
Обычно задачи поступают на обработку в случайные моменты времени, и время их пребывания в системе зависит от состава «смеси» (числа и характеристик) задач, одновременно обрабатываемых системой. В результате этого, число задач n, обработан-ных системой за время T, - величина случайная, и производительность в этом временном интервале оценивается с погрешностью, имеющей статистическую природу и зависящей от случайной величины n и ее дисперсии (рассеяния). С увеличением длительности интервала T значение n возрастает, и погрешность оценки стремится к нулю при T. Другой способ определения производительности через среднее значение интервала между момен-
тами окончания обработки задач (рисунок 2.3). В этом случае в течение времени T регистрируются интервалы 1, …, n между моментами завершения обработки задач. Среднее время этого интервала определяется интенсивностью выходного потока задач.
![]() ,
(2.3)
,
(2.3)
а
производительность системы
![]() (2.4)
(2.4)
Оценки производительности (2.2) и (2.3) совпадают, если
начало и конец промежутка времени T совпадают с моментами начала и окончания обработки задач.
51
Интересна зависимость между средним числом задач, поступающих в единицу времени на вход системы с интенсивностью и средним числом задач, покидающих систему в единицу времени . Зависимость представлена на рисунке 2.4.
В области 0* интенсивность выходного потока полностью определяется интенсивностью входного потока =. При >* система из-за ограниченности ресурсов – числа и быстродействия устройств, а также емкости памяти, не может в течение единицы времени обслужить все поступившие на обработку задания. И интенсивность выходного потока , достигнув предельного значения *, остается постоянной при любых значениях >*, причем *=*. Значение * определяет максимальную производительность системы для заданного класса задач и является характеристикой самой системы, не зависящей от интенсивности входного потока задач. Таким образом, производительность системы является ограниченной сверху величиной: 0*. В области 0* все
ресурсы системы в какой-то степени недоиспользуются. В области, * по крайней мере, один ресурс загружен полностью. Остальные ресурсы могут быть недогружены из-за нехватки одного или одновременно нескольких ресурсов.
В общем, на производительность наиболее
существенно влияют следующие параметры:
общем, на производительность наиболее
существенно влияют следующие параметры:
число и быстродействие устройств, емкость оперативной и внешней памяти, с увеличением которых производительность может возрастать, а также структура системы и пропускная способность связей между элементами системы;
режим обработки задач, определяющий порядок распределения ресурсов системы между задачами, поступающими на обработку;
рабочая нагрузка, - в первую очередь объем вводимых, хранимых в памяти, выводимых данных и число процессорных операций, необходимых для решения задачи.
Оценка
производительности числом задач,
решаемых системой за единицу времени,
годится только для конкретной системы,
работающей с определенным, заданным
множеством задач. Для оценки
производительности различных систем,
обрабатывающих различные классы задач,
производительность на рабочей нагрузке
определяют объемом вычислительной
работы, выполненной в еди-ницу времени.
Такую оценку представляют набором
значений
![]() ,
составляющие которого определяют объем
обработки, параметры ввода и вывода
данных в единицу времени и т.п. Например,
значение
,
составляющие которого определяют объем
обработки, параметры ввода и вывода
данных в единицу времени и т.п. Например,
значение
![]() может определять число процессорных
операций в секунду, а значение
может определять число процессорных
операций в секунду, а значение
![]() – число вводимых символов за секунду
и т.д. Объемы вычислительных работ могут
характеризоваться их предельными
значениями
– число вводимых символов за секунду
и т.д. Объемы вычислительных работ могут
характеризоваться их предельными
значениями
![]() ,
достигаемыми при насыщении системы.
Оценки производительности через
интенсивность выходного потока задач
и объемы вычислительных работ за единицу
времени связаны соотношением:
,
достигаемыми при насыщении системы.
Оценки производительности через
интенсивность выходного потока задач
и объемы вычислительных работ за единицу
времени связаны соотношением:
![]() ,
(2.5)
,
(2.5)
где n = 1,…, N – число типов операций;
![]() -
показатель сложности вычислений,
характеризуемый средним числом операций
типа 1,…, N,
выполняемых при решении одной
-
показатель сложности вычислений,
характеризуемый средним числом операций
типа 1,…, N,
выполняемых при решении одной
задачи.
Причем, сюда включаются и операции,
относящиеся к системным процессам
(выполняемые операционной системой).
Из формулы (2.5) следует зависимость
![]() (2.6)
(2.6)
Для
различных индексов n
различия в оценках λ,
свидетельствуют о погрешностях в
измерении значений
![]() и
.
и
.
Если
известны характеристики задач
![]() и быстродействия устройств
,
реализующих операции типа 1,..., N
соответственно, и, предположительно,
управляющими программами обеспечивается
параллельный режим обработки задач и
параллельная работа устройств, то можно
получить верхнюю оценку максимальной
производительности системы в форме:
и быстродействия устройств
,
реализующих операции типа 1,..., N
соответственно, и, предположительно,
управляющими программами обеспечивается
параллельный режим обработки задач и
параллельная работа устройств, то можно
получить верхнюю оценку максимальной
производительности системы в форме:
![]() ,
(2.7)
,
(2.7)
определяемую
наименее производительным устройством
в этой вычислительной системе. Здесь
отношения
![]() определяют максимальную производительность
устройств типа n
= 1,…, N,
характеризуемую числом задач, которые
способны обслужить устройства за единицу
времени. Оценка (2.7) будет ближе к реальному
значению
определяют максимальную производительность
устройств типа n
= 1,…, N,
характеризуемую числом задач, которые
способны обслужить устройства за единицу
времени. Оценка (2.7) будет ближе к реальному
значению
![]() ,
если вместо
подставить значения
,
характеризующие комплексную
производительность системы.
,
если вместо
подставить значения
,
характеризующие комплексную
производительность системы.
Еще одним из способов оценки производительности является оценка производительности через процессорное время. Напомним, что одним из компонентов общего времени выполнения программ является процессорное время – Т [с]. Как известно, программы обычно пишутся на одном из языков высокого уровня, не завися-щих от конкретной организации процессора и архитектуры ЭВМ. После перевода такой программы на машинный язык – трансляции, объем программы, как правило, увеличивается за счет увеличения количества машинных команд - N, которые будут реально выполнены. Известно также, что каждая команда разбивается на ряд элементарных – базовых шагов. Положим, что среднее количество базовых шагов, необходимых для выполнения одной команды равно – S и что каждый базовый шаг выполняется за один такт про-цессора. Если тактовая частота процессора равна F тактам в секунду, то время выполнения программы составит:
![]() ,
секунд (2.8)
,
секунд (2.8)
Это равенство и определяет производительность компьютера. Некоторые специалисты называют его основной формулой вычисления производительности. Из равенства видно, что разработчик компьютера должен искать пути уменьшения значения T, для чего необходимо предельно уменьшить значения N и S и увеличить зна-
чение F. Значение N уменьшается, когда исходная программа транслируется в машинные коды с меньшим количеством команд.
Значение S уменьшается, когда команда выполняется за меньшееколичество базовых шагов или когда некоторые шаги могут выполняться одновременно. С повышением тактовой частоты F уменьшается время выполнения базового шага команды.
Естественно предположить, что параметры N, S и F являются зависимыми – изменение одного может повлиять на величину другого, поэтому значащей величиной является только значение параметра T.
Несмотря на кажущуюся простоту формулы (2.8), вычислить значение T не так-то просто. Более того, такие параметры как тактовая частота, а также различные архитектурные параметры компьютера не являются достоверными показателями производительности.
Поэтому для определения производительности был разработан еще один метод с помощью тестовых программ. Показателем производительности стало время, в течение которого компьютер выполняет тестовую программу. В настоящее время общепринято использовать для этого наборы специально разработанных реальных программ. Подбором таких программ занимается организация под названием System Performance Evaluation Corporation (SPEC) – акционерное общество по разработке систем определения характеристик производительности компьютеров. Она публикует списки программ для разных прикладных областей и результаты тестирования имеющихся на рынке моделей компьютеров. В список входят самые разнообразные программы: вычислительные программы в области астрофизики и квантовой механики и химии, управление базами данных, редакторы, игры и т.д. Программы компилируются и выполняются на тестируемом компьютере. Никакая эмуляция не допускается. Эти же программы компилируются и выполняются на компьютере, выбранном в качестве эталона. Коэффициент производительности названный SPEC вычисляется по формуле:
![]()
Так SPEC-коэффициент = 50 указывает на то, что тестируемый компьютер в 50 раз работает быстрее, чем эталонный. Для полного тестирования выполняются все программы из списка SPEC. Итоговый SPEC-коэффициент для компьютера рассчитывается по формуле:
![]() ,
,
где n – количество программ в тестовом наборе. Выполнение программ и измерения производятся в реальном времени, поэтому суммарно учтены все факторы, влияющие на производительность тестируемого компьютера, в том числе влияние компилятора, операционной системы, процессора и памяти.
2.2.2 Время ответа
Время ответа, иначе время пребывания заданий (задач) в системе, - длительность промежутка времени от момента поступления задания в систему до момента окончания его выполнения. На рисунке 2.3 указано время ответа u1, u2, … для заданий J1, J2, соответственно.
В общем случае время ответа – случайная величина, что обусловлено следующими факторами:
влиянием исходных данных на число операций ввода, обработки и вывода данных и непредсказуемостью значений исходных данных;
влиянием состава смеси задач, одновременно находящихся в системе, и непредсказуемостью состава смеси из-за случайности момента поступления задач на обработку.
Время ответа как случайная величина наиболее полно характеризуется функцией распределения P(u<x) или функцией плотности вероятностей p(u). Чаще всего время ответа оценивается средним значением, которое определяется как статистическое среднее случайной величины u i, i = 1,…,n, наблюдаемой для Ji задач
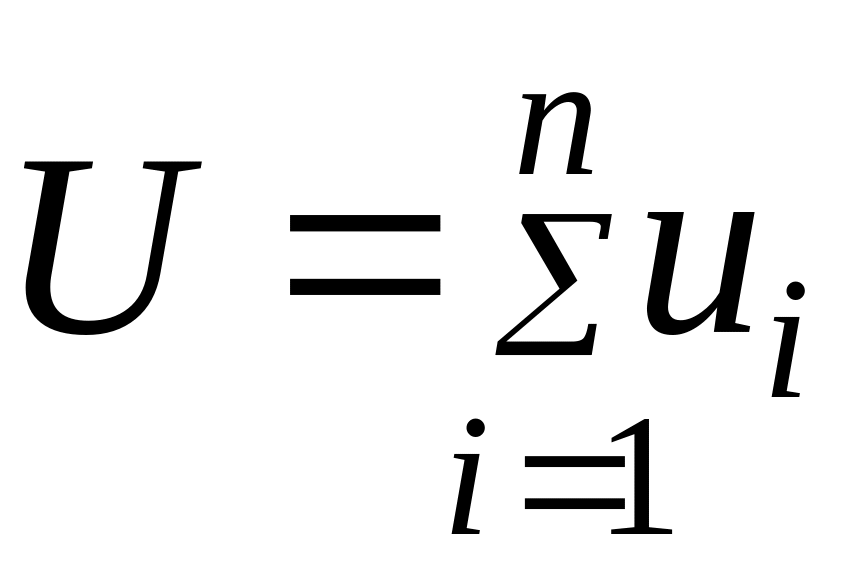 (2.9)
(2.9)
Время ответа слагается из двух составляющих: время выполнения задачи и время ожидания выполнения. Время выполнения задачи при отсутствии параллельных процессов равно суммарной длительности всех этапов процесса – ввода, обращения к внешней
памяти, процессорной обработки и вывода. Это время зависит от сложности вычислений и быстродействия устройств 1,..., N:
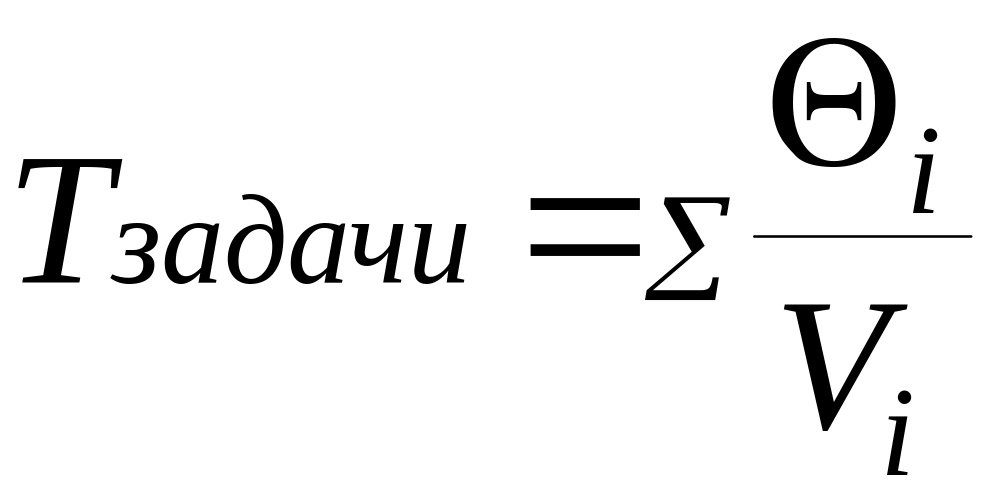 (2.10)
(2.10)
Время ожидания – сумма промежутков времени, в течение которых задача находилась в состоянии ожидания требуемых ресурсов. Ожидание возникает при мультипрограммной обработке, когда ресурс, необходимый задаче, занят другой задачей и первая
задача не выполняется, ожидая освобождение ресурса. Время ожидания зависит от режима обработки задач и интенсивности входного потока задач (заданий).
Т аким
образом, время ответа зависит от тех же
параметров, что и производительность,
то есть от структуры и характеристик
технических средств, режима обработки
и характеристик задач. Зависимость
среднего времени ответа U
от интенсивности входного потока задач
приведена на рис. 2.4. При
0 время ответа
аким
образом, время ответа зависит от тех же
параметров, что и производительность,
то есть от структуры и характеристик
технических средств, режима обработки
и характеристик задач. Зависимость
среднего времени ответа U
от интенсивности входного потока задач
приведена на рис. 2.4. При
0 время ответа
U Тзадачи,
где Тзадачи
определяется
(2.10). С увеличением
среднее время ответа монотонно возрастает
и может принимать сколь угодно большие
значения, если интенсивность входного
потока
превышает производительность системы
λ
*
в
течение сколь угодно большого периода
времени.
Тзадачи,
где Тзадачи
определяется
(2.10). С увеличением
среднее время ответа монотонно возрастает
и может принимать сколь угодно большие
значения, если интенсивность входного
потока
превышает производительность системы
λ
*
в
течение сколь угодно большого периода
времени.
Среднее время ответа характеризует быстроту реакции системы на входные воздействия: задания, запросы абонентов и т.п. Качество системы тем выше, чем меньше среднее время ответа.
2.2.3 Характеристики надежности
Надежность – это свойство системы выполнять возложенные на нее функции в заданных условиях функционирования с заданными показателями качества. По-другому – свойство системы сохранять величины выходных параметров в пределах установленных норм при заданных условиях.
Показателями качества могут служить: достоверность результатов, пропускная способность, время ответа и другие. Под «заданными условиями» подразумеваются различные факторы, которые могут влиять на выходные параметры системы и выводить их за пределы установленных норм.
Известно, что работоспособность системы или отдельных, составляющих ее частей время от времени нарушается. Случаются выходы из строя элементов или соединений, называемые отказами. Отказом называют событие, после которого система не выполняет своих функций в установленном объеме, не обеспечивает нормальной работы. Надежность системы характеризуется степенью ее безотказной работы во времени. Поскольку отказ является случайной функцией времени, то и надежность характеризуется случайной функцией времени, то есть подчиняется вероятностным законам. Важнейшей характеристикой надежности является интенсивность отказов, определяемая средним числом отказов за единицу времени, обычно это один час. Чем больше элементов и соединений, тем больше вероятность отказов. Можно определить интенсивность отказов для каждого элемента или соединения – λ i и интенсивность отказов системы или изделия, состоящего из n элементов:
![]()
Так, если Λ = 10 –2 ч, то в среднем за 100 часов работы происходит один отказ. Средний промежуток времени между двумя смежными отказами называется средней наработкой на отказ и равен T ср. о = 1/Λ. При том же значении Λ = 10 –2 ч наработка на отказ составит 100 ч. Промежутки между отказами являются случайными величинами со средним значением T ср.о распределяются, как правило, по экспоненциальному закону.
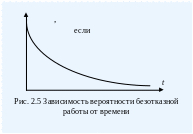 Для
надежной работы элементов необходимо,
чтобы t
<< T
ср.
о
. Так, например, если t/
T
ср.
о
= 0,01, то P(t)
=0,99; если
Для
надежной работы элементов необходимо,
чтобы t
<< T
ср.
о
. Так, например, если t/
T
ср.
о
= 0,01, то P(t)
=0,99; если
t/ T ср. о = 0, 1, то P(t) =0,9.
Таким образом, в качестве количественной меры надежности элементов можно использовать интенсивность отказов. Эта мера не является единственно возможной, но она позволяет легко определить время и вероятность безотказной работы.
Надежность системы можно характеризовать и другой количественной мерой – коэффициентом готовности (availability).
Дело в том, что нарушенную в результате отказа работоспособность системы можно восстановить путем ее ремонта. Ремонт состоит в выявлении причины отказа через диагностику системы и замены неисправного элемента. Промежуток времени, затраченный на восстановление работоспособности системы, называется временем восстановления. Его длительность зависит от сложности системы, совершенства средств диагностики, уровня ремонтопригодности, профессионализма обслуживающего персонала. Время восстановления – случайная величина, характеризуемая средним значением ТВ - средним временем восстановления.
С учетом средней наработки на отказ T ср. о и среднего времени восстановления ТВ, надежность системы оценивается значением коэффициента готовности:
![]() ,
,
определяющим долю времени, в течение которого система находится в работоспособном состоянии.
Значение 1 - К г представляет собой долю времени, в течение которого система не работоспособна – ремонтируется. Например, если К г = 0,95, это значит 95% времени система работоспособна, а 5% времени ремонтируется. Кроме того, коэффициент готовности определяет вероятность того, что в любой произвольный момент времени система работоспособна, а значение 1 - К г - вероятность того, что в этом промежутке времени система восстанавливается.
Надежность системы может быть повышена за счет различных вариантов резервирования ее элементов. Резерв – это избыточность элементов, которые не участвуют в действиях, но которые в определенный момент могут быть действующими. Понятно, что резервирование связано с дополнительными затратами на систему, то есть увеличивают ее конечную стоимость.
2.3 Режимы обработки данных
Режим обработки данных – это способ выполнения заданий (задач), характеризующийся порядком распределения ресурсов системы между заданиями (задачами). Требуемый режим обработки данных обеспечивается управляющими программами операционной системы. Последние выделяют заданиям оперативную и внешнюю память, устройства ввода-вывода, процессорное время и другие ресурсы в требуемом заданием порядке, с учетом приоритетов заданий, сложности задач, вычислений и др.
Режим обработки данных порождает соответствующий режим функционирования системы. Последний проявляется в порядке выполнения задач и предоставлении некоторым из них преимущественного права на использование ресурсов, организации ввода-вывода данных, хранения программ в оперативной памяти и т.д. Порядок распределения ресурсов в конечном итоге влияет: на продолжительность пребывания задач в системе; производительность системы; стоимость обработки данных и другие характеристики системы, а также на процессы обработки задач. В связи с этим, выбор режима обработки обусловлен необходимостью обеспечения тех или иных характеристик системы и процессов обработки. Характеристики системы, в свою очередь, влияют на способы взаимодействия пользователя с системой и, следовательно, на интенсивность взаимодействия, продолжительность взаимодействия и т.д.
2.3.1 Пакетная и оперативная обработка данных
В пору машин второго и третьего поколений основными машинными носителями программ были перфокарты (картонные бланки). Программы набивались на перфокарты, образуя, так на-
зываемую, колоду. Колоды собирались в некоторую их совокупность – пакет (колода). При этом формировалась смесь задач таким обра-зом, чтобы обеспечить наиболее эффективное использование ресурсов системы. Задачи – колоды с программами в выбранном порядке через считывающие устройства компьютеров вводились в память машины. В то время это был основной режим решения задач, при котором пользователь вообще не имел общения с машиной. Программы, как правило, были отлажены и требовали минимального внимания со стороны персонала, следящего за процессом их выполнения. Таким образом, режим пакетной обработки данных оказался наиболее экономичным за счет эффективного использования ресурсов. Правда, время ответа оказывалось значительным – десятки минут или даже десятки часов.
Пакетная обработка характеризуется:
- большим объемом вводимых и выводимых данных и вычислений, приходящихся на одно взаимодействие с машиной (на одну задачу);
- низкой интенсивностью взаимодействия и допустимостью большого времени ответа.
Пакетная обработка была типична для вычислительных центров научно-технического профиля, систем обработки учетно-статистических данных, результатов геофизических измерений, расчетов, связанных с различными областями использования ядерной энергии, расчетами в космонавтике и т.д.
Оперативная обработка возникла тогда, когда пользователь получил тем или иным способом непосредственный доступ к машине. Этот вид обработки характеризуется:
- малым объемом вводимых - выводимых данных и вычислений, приходящихся на одно взаимодействие пользователя с системой (на одну задачу);
- высокой интенсивностью взаимодействия и вытекающим отсюда требованием уменьшения времени ответа.
Необходимость в оперативной обработке имеется в системах банковских расчетов, различного рода справочных систем, в системах резервирования транспортных билетов и многих других областях жизненной деятельности людей.
Выделяют два режима оперативной обработки: запрос-ответ и диалоговый. Типичным примером режима запрос-ответ является справочная служба на базе ЭВМ. Пользователь формирует запрос в виде вопроса, который передается в ЭВМ, и ждет ответа. Ответ может быть получен в течение нескольких секунд или в пределах минут.
Диалоговый режим предполагает очень кратковременный «личный» контакт пользователя с системой, при котором реакция системы на действия пользователя составляет доли секунды или несколько секунд. Например, система практически мгновенно
должна реагировать на нажатие клавиши клавиатуры – время ответа не должно превышать 0,1 секунды. Менее жестким будет ре-жим, когда реакция должна возникать по окончании набора строк. Быстрота реакции системы на действия пользователя является непременным требованием к ней при реализации диалогового режима.
Положительным свойством диалогового режима являются:
- возможность постоянного контроля пользователем за вводом программ и данных;
- возможность оперативного вмешательства в процесс решения задачи, в случае непредвиденного поведения программ;
- возможность оперативного доступа к системе.
Однако за любую услугу приходится расплачиваться. Этого обстоятельства «не избежал» и диалоговый режим. Для его реализации необходима аппаратура достаточно высокой производительности и большая, например, по сравнению с пакетным режимом, усложненность системного программного обеспечения. В итоге удорожается стоимость обработки единицы информации и всей обработки в целом.
2.3.2 Мультипрограммная обработка
Этот
режим обработки стал возможен, когда
появились аппаратное и программное
обеспечения, позволяющие подключение
к ЭВМ многочисленных пользователей. То
есть пользователи смогли инициализировать
(запускать) свои программы со своих
рабочих мест. Этот режим обработки стал
возможен, когда появились аппаратное
и программное обеспечения, позволяющие
подключение к ЭВМ многочисленных
пользователей. То есть, пользователи
смогли инициализировать свои программы
со своих рабочих мест. Известно, что
задача (программа) в каждый конкретный
момент времени обрабатывается одним
устройством машины, другие устройства
простаивают до завершения текущей
о перации
и, следовательно, могут использоваться
для обработки других программ. Создаются
условия, при которых в системе
обрабатывается сразу несколько программ
одновременно, но разные программы
обрабатываются разными устройствами,
работающими параллель-
перации
и, следовательно, могут использоваться
для обработки других программ. Создаются
условия, при которых в системе
обрабатывается сразу несколько программ
одновременно, но разные программы
обрабатываются разными устройствами,
работающими параллель-
но и независимо. Такой вид обработки назвали мультипрограммной обработкой, или, кратко, мультипрограммированием. По-другому, этот режим называют иногда мультизадачным. Цель использования такого режима - увеличение производительности и одновременно повышение эффективности использования ресурсов машины за счет распределения их между многочисленными пользователями.
Число задач, находящихся в вычислительной системе, называется уровнем мультипрограммирования, обозначаемым символом М. На рисунке 2.6 приведены функциональные зависимости: производительности, и времени ответа от уровня мультипрограммирования - λ=f(M) и U = f(M).
На графике, для упрощения представления, кривые зависимостей аппроксимированы ломаными линиями.
В однопрограммном режиме M = 1 и время ответа U = U1 = T отв (см. формулу). При этом производительность равна λ = λ 1 = 1/ U1. С увеличением числа задач, поступающих в систему (M), все большее число устройств становятся занятыми выполнением этих задач. Но в то же время вероятность одновременных обращений задач к одному и тому же ресурсу еще мала, и мало время ответа. Иногда может возникнуть ситуация, когда число задач M станет равным M * (M = M*), - это свидетельствует о том, что теперь, по крайней мере, хотя бы одно устройство оказывается полностью загруженным. Значение M * называется точкой насыщения мультипрограммной смеси или точкой насыщения системы. Дальней-шее увеличение числа задач не приводит к росту производительности λ, которая теперь принимает значение λ *. Значение M * может смещаться по графику вправо, что свидетельствует о большем числе ресурсов - устройств в системе. Но, значение M * может быть смещено и влево, если задачи используют преимущественно одно устройство и может принимать значение, равное единице. Работа системы при уровне мультипрограммирования равном M > M * неэффективна, так как нет выигрыша в производительности и велико время ответа.
Производительность оценивают по формуле Литтла, отражающей фундаментальный закон теории массового обслуживания:
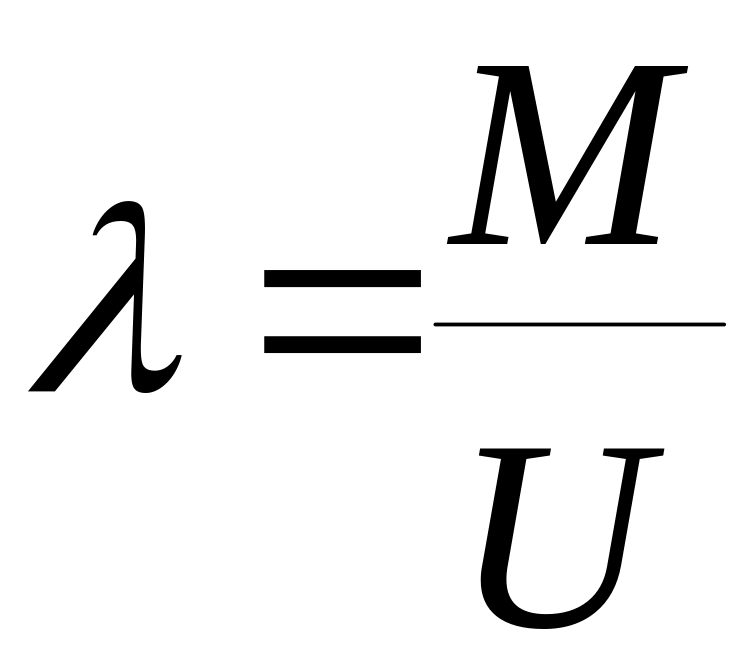 .
(2.11)
.
(2.11)
Существует
зависимость, по которой можно определить
среднее число задач, выполняемых
одновременно в мультипрограммном режиме
через загрузку
![]() каждого из
каждого из
![]() устройств системы:
устройств системы:
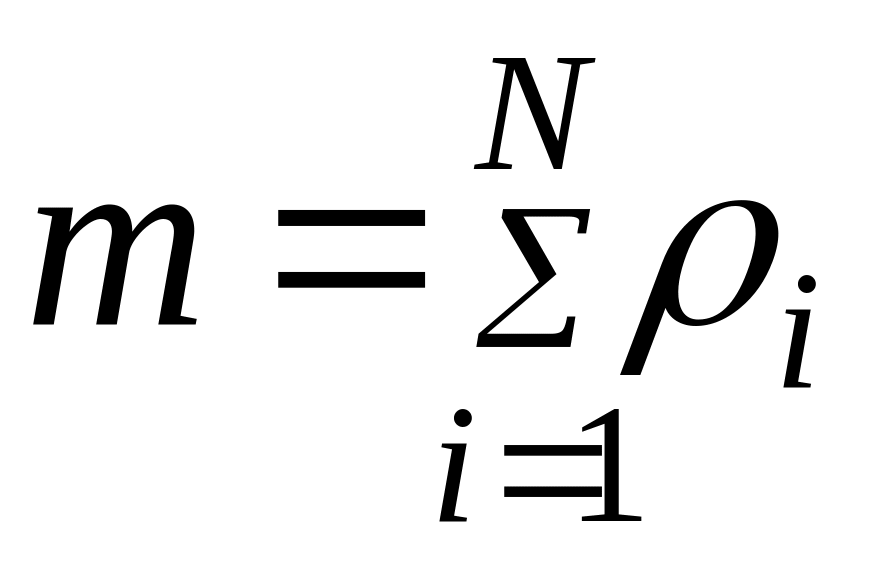 .
(2.12)
.
(2.12)
Величина
m
называется коэффициентом
мультипрограммирования и
характеризуется отношением
производительности системы в
мультипрограммном режиме
![]() к производительности в однопрограммном
режиме
к производительности в однопрограммном
режиме
![]() ,
если затраты ресурсов возрастают
пропорционально числу одновременно
выполняемых задач: m
= λ
/
λ
1.
,
если затраты ресурсов возрастают
пропорционально числу одновременно
выполняемых задач: m
= λ
/
λ
1.
Разность
M
– m
определяет число задач в системе,
находящихся в состоянии ожидания
выполнения. Из формулы (2.12) следует, что
численное значение m
находится
в интервале
![]() ,
где N
- число устройств системы, способных
функционировать с каждым из N
– 1 остальных устройств.
,
где N
- число устройств системы, способных
функционировать с каждым из N
– 1 остальных устройств.
2.3.3 Обработка данных в реальном масштабе времени
Наступило
время, когда ЭВМ начали использовать в
системах управления реально действующих
физических объектов. Процесс управления
такими объектами характеризуется тем,
что в нем используется фиксированный
набор программ. Каждая программ работает
либо периодически, либо по мере
возникновения каких-то определенных
ситуаций в системе. Время начала работы
каждой программы, и получения результатов
определяется технологическим процессом
в устройствах управляемого объекта
(системы), то есть подчиняется темпу вне
системы обработки данных. Такой режим
обработки данных назвали обработкой в
реальном
масштабе времени.
Требования к ЭВМ таких систем сводится
к ограничению времени ответа, которое
не должно превышать некоторого предельно
допустимого значения для данной системы,
то есть
![]() ,
где u
1,
… , u
M
- время ответа, а
,
где u
1,
… , u
M
- время ответа, а
![]() - предельно
допустимое
значение времени ответа для каждой из
А1,
…,
АМ
задач,
соответственно.
- предельно
допустимое
значение времени ответа для каждой из
А1,
…,
АМ
задач,
соответственно.
Обеспечить обработку данных в реальном масштабе времени можно:
- выбором структуры системы обработки данных, обеспечивающей решение задач, связанных с управляющей системой;
- организацией процессов обработки обеспечивающих требуемое время ответа от управляющей ЭВМ.
2.3.4 Режим телеобработки данных
Режим связан с удаленностью пользователей от ЭВМ и взаимодействием их с системой обработки через те или иные виды ли-ний связи. Это, во-первых, требует специальных действий пользо-
вателей при организации доступа к системе и завершению сеанса. Во-вторых, накладывает ограничения на форму и время обмена данными между пользователем и системой обработки данных, приводит к необходимости использования специальных способов организации данных и доступа к ним как со стороны пользователя, так и со стороны системы. Эти специфические особенности отражаются на структуре прикладных программ, эксплуатируемых в этом режиме. Пользователи в системах телеобработки могут работать в пакетном, диалоговом или «запрос-ответ» режимах. Каждый способ имеет свою специфику, не зная которую пользователь просто не сможет работать в такой системе.
2.3.5 Параллельная обработка данных
Обсуждение вопросов увеличения производительности систем обработки данных, непременно связывается с теми или иными способами их параллельной обработки. Параллельная обработка данных, это вероятно «столбовая дорога» к достижению целей, связанных с наивысшими значениями характеристики – производительности.
При этом выбирают одно из трех основных направлений:
- совмещение во времени различных этапов разных задач;
- одновременное решение различных задач или частей одной задачи;
- конвейерную обработку данных.
Совмещение во времени этапов решения различных задач, - это не что иное, как режим мультипрограммной обработки. Одна программа обрабатывается процессором, части других программ обрабатываются другими устройствами машины или внешними устройствами. Мы уже знаем, что такую обработку можно выполнять и на однопроцессорной машине, и это реализуется в наиболее массовом порядке.
Второе направление требует обязательного наличия нескольких обрабатывающих устройств – машин или процессоров. При этом в зависимости от особенностей задач, можно реализовать тот или иной тип (или вид) параллельной обработки. Выделяют несколько типов параллелизма:
- естественный параллелизм независимых задач;
- параллелизм независимых ветвей;
- параллелизм объектов или данных.
Естественный параллелизм заключается в том, что в вычислительный комплекс или в вычислительную систему поступает поток не связанных между собой задач, таких, решение которых не зависит от результатов решения других задач потока. При этом за счет параллельного (одновременного) решения нескольких задач
сразу явно проявляется эффект увеличения производительности обработки информации.
Суть параллелизма независимых ветвей заключается в том, что программу большой задачи можно разработать в виде отдельных независимых частей - ветвей программы. Эти ветви, при наличии нескольких обрабатывающих, допустим процессоров, могут обрабатываться параллельно и независимо друг от друга. Независимыми ветвями (частями программы) считают такие, для которых выполняются следующие условия:
- входные данные для любой ветви, не являются выходными результатами работы другой программы;
- данные различных ветвей не записываются в одни и те же ячейки памяти;
- условия выполнения одной ветви не зависят от результатов, полученных в другой ветви, если ветви находятся на одном уровне.
Рисунок 2.7 иллюстрирует принцип программы, организованной в виде совокупности ветвей, расположенных в нескольких уровнях (ярусах). Прокомментировать этот рисунок – граф можно следующим образом. Программа составлена из четырнадцати «кусков» - ветвей, номера которых указаны в кружках.
Ветви расположены в виде ярусов (уровней). Каждая ветвь – часть программы, выполняется за определенное время - t, представленное здесь цифрами, стоящими около кружков. Стрелками обозначены входные данные и выходные результаты обработки. Входные данные обозначены символом x, выходные результаты символом y. Символы x имеют только нижние индексы, означающие порядок и величины входных данных. Символы y имеют двой-ные индексы, из которых верхний указывает номер ветви, а нижний – порядковый номер результата. Символы y имеют двойные индексы, из которых верхний указывает номер ветви, а нижний – порядковый номер результата. Граф иллюстрирует, каким образом можно «отработать» программу, организовать процесс ее реализации и получить эффект сокращения времени решения, применив параллельную, с помощью двух процессоров обработку.
Нетрудно
подсчитать, что при обычном последовательном
способе решения задачи потребуется
![]() = 375 единиц времени. Если решать ее двумя
независимыми процессорами по указанной
схеме, то видно, что задача разделяется
на два потока, время решения в каждом
потоке будет меньше времени последовательного
решения и наибольшее из них и будет
временем решения всей задачи. Меньшее
время будет «поглощено» большим. В
результате, части задачи, решаемые
процессором 1, займут 135 единиц времени,
а части задачи, решаемые вторым процессором
– 245
= 375 единиц времени. Если решать ее двумя
независимыми процессорами по указанной
схеме, то видно, что задача разделяется
на два потока, время решения в каждом
потоке будет меньше времени последовательного
решения и наибольшее из них и будет
временем решения всей задачи. Меньшее
время будет «поглощено» большим. В
результате, части задачи, решаемые
процессором 1, займут 135 единиц времени,
а части задачи, решаемые вторым процессором
– 245
единиц времени. Следовательно, в итоге будет затрачено времени в 1,5 раза меньше, чем при решении традиционным способом. Выигрыш во времени очевиден. Попробуйте, проверьте сами.
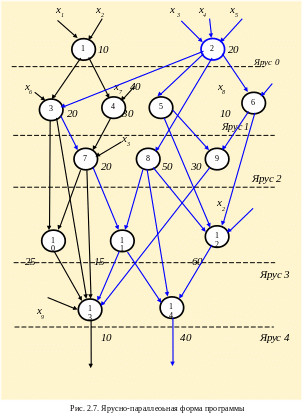
Выигрыш во времени для различных последовательностей ветвей будет отличаться, но тенденция результата останется прежней. Сложность заключается в том, что не всегда известна, тем более точно, длина ветвей, порой трудно выделить параллельные ветви и некоторые другие. Вместе с тем только программирование с выделением параллельных ветвей позволяет существенно сократить время решения задачи. Хорошо поддаются параллельной об-
работке задачи матричной алгебры, спектральной обработке сигналов, преобразования Фурье и др.
Параллелизм объектов или данных. Такой режим реализуется, когда однотипные данные поступают от многочисленных объектов, расположенных в различных местах и обрабатываются по одной и той же программе. Например, данные поступают от температурных датчиков, установленных на однотипных объектах. Это могут быть данные радиолокационных измерений, также обрабатываемые по одной программе. Это могут быть и математические задачи, например, операции над векторами и матрицами. Задача сводится к выполнению одинаковых операций над парами чисел. Все эти операции могут выполняться параллельно, независимо друг от друга несколькими обрабатывающими устройствами.
2.4 Классификация систем параллельной обработки
Процесс решения задачи представляет собой воздействие программы в виде последовательности команд на соответствующую последовательность данных. Последовательность команд программы можно представить в виде потока, аналогично можно интерпретировать и последовательность данных. Получается, что один поток воздействует (обрабатывает) другой поток. При другой организации параллельной обработки информации один поток команд может воздействовать на несколько потоков данных и наобо-рот. В связи с многообразием организаций систем параллельной обработки данных представляется естественным как-то их классифицировать. Что и было сделано.
Классификация вычислительных систем по указанным признакам получила название классификации Флина.
При классифицировании систем параллельной обработки данных оказалось полезным ввести понятие множественности команд и множественности данных. Под множеством надо понимать наличие нескольких последовательностей команд (программ или частей программ), находящихся одновременно в стадии выполнения, или последовательностей данных, подвергающихся обработке. Исходя из выше приведенных условий, все параллельные системы разбили на четыре больших класса:
- системы с одиночным потоком команд и одиночным потоком данных – ОКОД, - английская аббревиатура – SISD – Single Instruction Single Data;
- системы с множественным потоком команд и одиночным потоком данных – МКОД, - английская аббревиатура - MISD – Multiple Instruction Single Data;
- системы с одиночным потоком команд и множественным потоком данных – ОКМД, - английская аббревиатура - SIMD – Single Instruction Multiple Data;
- системы с множественным потоком команд и множественным потоком данных – МКМД, - английская аббревиатура - MIMD – Multiple Instruction Multiple Data;
Рассмотрим кратко особенности каждого класса.
С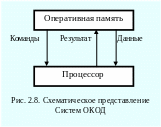 истемы
ОКОД. Схематически
такую систему можно представить так,
как показано на рисунке 2.8. Системы этого
класса – обычные однопроцессорные ЭВМ.
Как мы уже обсуждали, в таких системах
организация параллельной обработки
заключается в совмещении во времени
различных этапов разных задач, при
одновременной обработке их разными
устройствами. Например, одновременно
работают печатающие устройства по
нескольким каналам,
вводятся
данные с накопителей на магнитных
дисках, работает процессор и т.д., и все
это делается по
различным программам.
истемы
ОКОД. Схематически
такую систему можно представить так,
как показано на рисунке 2.8. Системы этого
класса – обычные однопроцессорные ЭВМ.
Как мы уже обсуждали, в таких системах
организация параллельной обработки
заключается в совмещении во времени
различных этапов разных задач, при
одновременной обработке их разными
устройствами. Например, одновременно
работают печатающие устройства по
нескольким каналам,
вводятся
данные с накопителей на магнитных
дисках, работает процессор и т.д., и все
это делается по
различным программам.
Конструирование оперативных запоминающих устройств (ОЗУ) в виде многомодульной структуры обеспечивает каждому модулю независимое функционирование и дает определенный, ощутимый эффект увеличения производительности. При этом уменьшается количество конфликтов при обращении к ОЗУ нескольких устройств ввода-вывода сразу.
Конфликты разрешаются так же путем введения приоритетов устройств, которые определяют очередность их обращений к ОЗУ. При возникновении очередей возможны простои оборудования.
Более всего простои отражаются на работе процессора, который может ожидать в очереди сколь угодно долго, в то время как, например, электромеханические устройства ждать долго не могут, ибо это приведет к недопустимо большим потерям времени, а в конечном итоге - производительности. Если во время не считать данные с магнитного диска, то придется потерять несколько мил-лисекунд (один оборот диска) до следующего момента, когда возможно будет считать информацию.
Конвейер команд также можно рассматривать как совмещение во времени работы нескольких устройств – блоков, выполняющих отдельные части операции.
Е сли
к этому еще добавить использование
многомодульных ОЗУ можно добиться
существенного увеличения производительности
системы. При этом программы и данные
можно разместить в разных модулях и
совмещать во времени выборку команд и
операндов. Кроме того, можно сократить
время доступа к памяти, если применить
способ чередования адресов (расслоение
обращений) памяти – один модуль будет
иметь четные адреса, другой нечетные и
начало цикла памяти смещено на половину
цикла. Если память содержит N
модулей, то среднее время обращения к
ней составит 1/
N-ю
часть цикла памяти.
сли
к этому еще добавить использование
многомодульных ОЗУ можно добиться
существенного увеличения производительности
системы. При этом программы и данные
можно разместить в разных модулях и
совмещать во времени выборку команд и
операндов. Кроме того, можно сократить
время доступа к памяти, если применить
способ чередования адресов (расслоение
обращений) памяти – один модуль будет
иметь четные адреса, другой нечетные и
начало цикла памяти смещено на половину
цикла. Если память содержит N
модулей, то среднее время обращения к
ней составит 1/
N-ю
часть цикла памяти.
Системы класса МКОД. По определению такая система должна была бы выглядеть так, как представлено на рисунке 2.9, однако, не существует таких задач, в которых одна и та же последовательность данных обрабатывалась бы различными программа-ми. По этой причине на практике реализована система, представленная рисунком 2.10.
Ф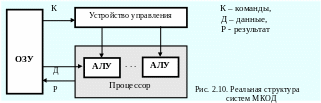 актический,
одиночный поток команд устройством
управления разделяется на несколько
потоков микрокоманд (микроопераций).
Каждая из микроопераций реализуется
специализированным, настроенным на
выполнение именно данной микрооперации
устройством.
актический,
одиночный поток команд устройством
управления разделяется на несколько
потоков микрокоманд (микроопераций).
Каждая из микроопераций реализуется
специализированным, настроенным на
выполнение именно данной микрооперации
устройством.
Поток данных последовательно проходит через все или часть этих специализированных АЛУ. Именно такие системы называют конвейерными или системами с магистральной обработкой информации. Определяющим признаком таких систем является наличие конвейера арифметических или логических операций. Напомним, что такие системы максимально производительны для определенных типов задач, имеющих длинные последовательности (цепочки) однотипных операций при длинной последовательности данных (например, координаты, выдаваемые радиолокационной
станцией), то есть когда имеет место параллелизм объектов и данных.
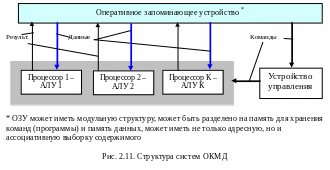
Системы класса ОКМД. Системы, относящиеся к этому классу также как и предыдущие, ориентированы на параллелизм объектов и данных. В таких системах по одной программе обрабатываются сразу несколько потоков данных, каждый из которых обрабатывается своим процессором, но работающим под общим управлением - по одной команде разные процессоры выполняют одну и ту же операцию над различными данными. Схематически такие системы можно иллюстрировать рисунком 2.11. В архитектуре систем, представленных на рисунке управление может быть реализовано и с помощью отдельной ЭВМ, имеющей свою память команд. Используются и другие виды параллельной обработки, например, с помощью матричных или ассоциативных систем.
С истемы
класса МКМД. В
вычислительных системах этого класса,
обработка данных может быть организована
либо
на многомашинных комплексах, либо на
многопроцессорных комплексах.
истемы
класса МКМД. В
вычислительных системах этого класса,
обработка данных может быть организована
либо
на многомашинных комплексах, либо на
многопроцессорных комплексах.
Такие комплексы можно построить и на базе отдельных ЭВМ со своей памятью команд и данных, со своей операционной системой, вообще со всеми особенностями им присущими (рисунок 1.1).
Объединенные в систему с помощью тех или иных видов связи вычислительные машины, наиболее приспособлены для решения потока независимых задач, но при этом существенно увеличивают производительность вычислительных работ за счет большего количества решаемых задач. Многопроцессорные системы (комплексы) повышают производительность при использовании всех видов параллелизма, но, наибольший эффект достигается на задачах, запрограммированных по типу параллелизма независимых ветвей.
Архитектура систем, показанная на рисунке 2.12, является наиболее универсальной в отношении решаемых задач. Программное обеспечение таких систем не ориентируется на решение определенного класса задач, и поэтому они строятся как универсальные вычислительные комплексы, имеющие наиболее широкое распространение.
В 70 – 80-х годах прошлого столетия, вычислительные центры организовывали обработку данных по приведенной архитектрурной схеме, стараясь обеспечить вычислительными мощностями как можно большее число пользователей, работающих в то время в режиме телеобработки данных.
2.5 Конвейерная обработка данных
Конвейерная обработка преследует цель повышения скорости выполнения команд, а точнее увеличение количества операций, выполняемых за секунду.
Конвейер представляет собой цепочку асинхронных процессов, в которой выходные данные одного процесса являются входными данными другого процесса. В ходе совершенствования процессоров машин первыми, естественно, появились конвейеры команд. Конвейер может быть реализован и в однопроцессорной системе, когда выполнение операции разделено на некоторое количество шагов - процессов, выполняемых в строгой последовательности отдельными операционными блоками.

Например, процесс обработки команды разбит на четыре шага:
- выборка (Fetch) – чтение команды из оперативной памяти;
- декодирование (Decode) – декодирование (расшифровка) команды и выборка ее исходных операндов;
- выполнение (Execute) – выполнение заданной в команде операции;
- запись результатов (Write) – сохранение результатов выполнения команды в каком-либо регистре процессора или в оперативной памяти.
Аппаратная организация выполнения команды может быть структурно представлена рисунком 2.13. Процесс выполнения ко-манды управляется тактовым сигналом с такой частотой, при которой каждый шаг выполняется за один такт - представлен следующим рисунком 2.14.
Вкратце поясним, как работает такой конвейер. На первом такте команда I1 (Instruction) извлекается из оперативной памяти устройством выборки (F) и помещается в промежуточный буфер B1, необходимый для того, чтобы блок декодирования, выполнивший декодирование предыдущей команды, мог ее оттуда забрать для обработки.
На втором такте команда извлекается из буфера B1, декодируется и помещается в буфер B2. Информация в буфере B2 заменяется только после того, как будет выполнена последующая опе-рация. На этом же такте 2 устройством выборки извлекается из памяти вторая команда (I2) и помещается в буфер B1.

На третьем такте блоком Е команда извлекается из буфера B2, выполняется и помещается в буфер B3. Одновременно из буфера B1 блок декодирования извлекает команду I2, декодирует ее и помещает в буфер B2, в то же время блок выборки выбирает команду I3 и помещает ее в буфер B1. На очередном четвертом такте блок W извлекает результат обработки первой команды и сохраняет его по целевому адресу, обрабатывающее устройство E выполняет вторую команду и перемещает результаты в буфер B3. Пока выполняется I2, декодируется команда I3 и выбирается команда I4 и т.д. В результате все блоки заняты, а скорость выполнения команд в четыре раза больше, чем при последовательной обработке. Вы видите, что, начиная с четвертого такта, вся команда выполняется за один такт, то есть происходит совмещение во времени выполнения k этапов, на которые разбито выполнение команды.
Следует отметить, что описанный порядок поддерживать не удается, так как возникают конфликты – задержки в работе кон-вейера по причинам промахов при выборке команд из кэш-памяти, при выборке команд из оперативной памяти, при отсутствии данных, над которыми должна выполняться очередная операция и наличия в программах условных переходов. При возникновении условного перехода, программа переходит не к выполнению очередной команды, а совершенно другой, по выработанному в предыдущей команде признаку. В современных ЭВМ применяются различные приемы, позволяющие предсказать возможность перехода как можно раньше, однако совсем исключить влияние условных пере-ходов не удается. Тем не менее, для определенных задач, в программах которых имеются «ощутимые» последовательности без- условных переходов, выигрыш в производительности конвейерного процессора команд получается значительным.
Конвейеры операций или данных представляют собой последовательности операционных блоков, каждый из которых выполняет строго определенную часть операции. Например, операцию сложения элементов матриц, представленных числами с плавающей точкой, можно разделить на четыре последовательно выполняемых этапа:
- сравнение порядков - СП;
- выравнивание порядков – ВП – сдвиг мантиссы с меньшим порядком для выравнивания с мантиссой с большим порядком;
- сложение мантисс – СМ;
- нормализация результата – НР (то есть перенесение в соответствующее место запятой, чтобы первой значащей цифрой мантиссы не оказался ноль).

В соответствии с выбранным порядком выполнения операции в составе процессора предусмотрены четыре операционных блока, соединенных последовательно и реализующих выше перечисленные шаги операции сложения:
![]()
Этап
1
2
3
4
5
6
…
i
…
n
n+1
n+2
n+3
СП
a1
b1
a2
b2
a3
b3
a4
b4
a5
b5
a6
b6
ai
bi
an
bn
ВП
a1
b1
a2
b2
a3
b3
a4
b4
a5
b5
a1-1
b1-1
an-1
bn-1
an
bn
СМ
a1
b1
a2
b2
a3
b3
a4
b4
a1-2
b1-2
an-2
bn-2
an-1
bn-1
an
bn
НР
c
1
c
2
c
3
c
I-3
c
n-3
c
n-2
c
n-1
c
n
Рис.
2.16. Временная диаграмма конвейерной
операции
Надо
понимать, что функции одного операционного
блока могут выполнять несколько «штатных»
устройств процессора, таких, например,
как устройство управления процессора
и несколько регистров, или комбинационная
схема, выполняющая функции АЛУ и т.д.
Без использования конвейера общее время
выполнения операции сложения определилось
бы формулой:
![]() ,
,
где
![]() - время выполнения
- время выполнения
![]() -го
этапа операции. При использовании
конвейера общее время операции определится
из выражения:
-го
этапа операции. При использовании
конвейера общее время операции определится
из выражения:
![]() ,
где m
– число операционных блоков.
,
где m
– число операционных блоков.
В вычислительных системах, разумеется, можно использовать одновременно оба вида конвейеров, и конвейер команд и конвейер операций (данных), и даже несколько конвейеров и команд и опе-раций одновременно. При этом может быть получена очень высокая производительность системы.
Вопросы и задания для самопроверки
2.1. Каково определение «схемы» в контексте данной книги?
2.2. Определите понятие «ресурс» и назовите типы ресурсов.
Основное содержание понятия «операционная система».
Каковы на ваш взгляд различия между понятиями «операционное обеспечение» и «системное программное обеспечение»?
Что такое супервизор?
Дайте определение процесса. Назовите виды процессов.
Дайте определение рабочей нагрузки.
Определите понятие загрузки.
Что такое эффективность системы? «Характеристики» и «параметры», - в чем различие этих понятий?
Дайте общее понятие производительности вычислительной системы.
Напишите формулу производительности через интенсивность выходного потока.
Какие параметры влияют на производительность системы?
Что такое номинальная производительность?
Какая производительность выше, номинальная или системная?
Программа насчитывает 10 000 операторов (команд), каждая команда выполняется за 7 тактов. Частота процессора 2 ГГц. Определите производительность процессора.
Что за величина «время ответа»? Что она характеризует?
Напишите формулу интенсивности отказов системы из n элементов.
Какой характер имеет зависимость вероятности безотказной работы от времени?
Что характеризует коэффициент готовности системы? Напишите его формулу.
Чем характеризуется пакетная обработка данных? Каковы преимущества этого режима обработки?
Что означает оперативная обработка данных, чем характеризуется? Назовите режимы оперативной обработки.
Положительные свойства диалогового режима.
Дайте определение понятия «мультипрограммная обработка».
Прокомментируйте взаимозависимость мультипрограммной обработки и производительности.
Напишите формулу Литтла. Что она отражает?
Охарактеризуйте режим реального времени, в каких случаях его необходимо использовать?
Каковы на ваш взгляд корни слова «телеобработка»?2.29. Какие направления характерны для параллельной обработки данных?
Что такое естественный параллелизм обработки данных?
Суть параллелизма независимых ветвей.
В чем заключается содержание параллелизма объектов и данных?
Назовите классы систем параллельной обработки. Дайте краткую характеристику каждого из них.
Опишите принцип конвейерной обработки.
Как вы представляете себе векторную обработку?
Вычислительные комплексы.
Архитектуры и описания
3.1 Одномашинные архитектуры обработки данных
Классическое построение электронных вычислительных машин
Первыми системами, выполняющими обработку числовой информации, а проще говоря, операции над числами или числовыми данными были одиночные вычислительные машины. Вначале их называли цифровыми вычислительными машинами (ЦВМ). Во-первых, потому, что они обрабатывали цифровую информацию, а, во-вторых, потому, что исполнительными механизмами были механические или электромеханические узлы и устройства (типа реле). Когда появились электронные лампы и их стали использовать в вычислительных машинах, последние получили название электронных вычислительных машин (ЭВМ).
Классическое представление электронных вычислительных машин сложилось в конце 40-х – начале 50-х годов прошлого столетия. Существенное влияние на основу этого представления оказали идеи американских исследователей в области математики и вычислительной техники: Джона фон-Неймана, Джона Эккерта, Джона Моучли, А. Баркса, Х. Голдстина.
В соответствии с этим представлением машина должна состоять из трех основных устройств: арифметического, запоминающего устройства (памяти) и устройства управления. Несколько позже эти устройства в совокупности назвали центральной частью машины. Программа, представляющая собой набор последовательных команд, помещается в запоминающее устройство, названное впоследствии оперативной памятью, выполняющихся одна за другой линейно, одним программным потоком. Кроме центральной части, в машину должны были входить устройства, находящиеся вне ее. Они обеспечивали ввод исходной информации для решения некоторой задачи, а также вывод результатов вычислений. Эти устройства назвали внешними устройствами. Для первоначального пуска машины, контроля хода работы, необходимой остановки, машина
должна была иметь пульт управления. Схематично она должна была выглядеть примерно так, как показано на рисунке 3.1.
Д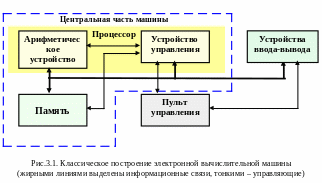 о
начала автоматической работы машины,
по командам с пульта управления через
внешние устройства в память машины
вводятся исходные числа для решения
некоторой задачи и программа вычислений.
Память машины состоит из электронных
устройств, способных хранить элементарную
единицу информации, соединенных в
некоторые совокупности и организованные
в виде строк и столбцов. Строка может
хранить большую, чем элементарная
единица, часть информации, которую
машина может обработать единовременно,
и названа словом.
Слово может представлять собой либо
число, либо команду (называемую также
инструкцией) – мнемоническое указание
о том, что должна сделать машина.
Последовательность команд – инструкций
составляет программу работы машины.
Строки памяти, содержащие слова в обиходе
называют ячейками памяти. Все ячейки
памяти занумерованы по порядку. Номер
ячейки называется ее адресом. Команда
содержит указания о том, что должна
сделать машина – эту ее часть называют
кодом операции, и указания об адресах
чисел, с которыми должны выполняться
операции и адресах для записи результатов
операций. То, над чем выполняется операция
в команде, называют операндами.
о
начала автоматической работы машины,
по командам с пульта управления через
внешние устройства в память машины
вводятся исходные числа для решения
некоторой задачи и программа вычислений.
Память машины состоит из электронных
устройств, способных хранить элементарную
единицу информации, соединенных в
некоторые совокупности и организованные
в виде строк и столбцов. Строка может
хранить большую, чем элементарная
единица, часть информации, которую
машина может обработать единовременно,
и названа словом.
Слово может представлять собой либо
число, либо команду (называемую также
инструкцией) – мнемоническое указание
о том, что должна сделать машина.
Последовательность команд – инструкций
составляет программу работы машины.
Строки памяти, содержащие слова в обиходе
называют ячейками памяти. Все ячейки
памяти занумерованы по порядку. Номер
ячейки называется ее адресом. Команда
содержит указания о том, что должна
сделать машина – эту ее часть называют
кодом операции, и указания об адресах
чисел, с которыми должны выполняться
операции и адресах для записи результатов
операций. То, над чем выполняется операция
в команде, называют операндами.
Разобраться в порядке автоматического выполнения программы поможет рисунок 3.2. На рисунке схематически представлены: процессор, память и интерфейс (системная шина), посредством которого реализуется взаимодействие между ними.
Программа располагается в памяти машины по определенным адресам и для начала ее выполнения оператор (или пользователь) должен указать управляющему устройству машины адрес первой
команды программы. Устройство управления помещает этот адрес в регистр адреса команы PC, и далее, адрес команды, через регистр адреса MAR направляется запоминающему устройству (памяти). Одновременно, устройство управление направляет в память (в виде сигнала управления) указание на чтение команды по данному адресу. Найденная в памяти команда пересылается через регистр данных MDR и регистр команд (IR) в устройство управления, где подвергается расшифровке. В зависимости от результатов расшифровки команды, формируются указания и сигналы о последующих обращениях к памяти по адресам, указанным в команде, для извлечения из нее данных - чисел, над которыми должна быть выполнена операция. Одновременно формируются сигналы функций АЛУ (арифметико-логического устройства) на время выполнения команды. На рисунке 3.2 - это управляющие сигналы типа ADD и CMP (сложить и сравнить).
Общий рег. RN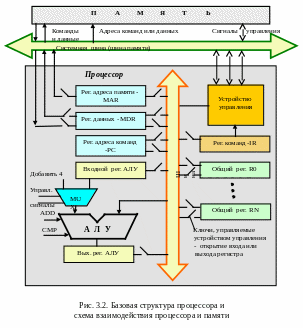
Числа и код операции передаются арифметическому устройству – в нашем примере АЛУ. Последнее выполняет необходимые
действия над операндами, и, с помощью устройства управления, направляет результат операции в место хранения, указанное в команде – это может быть память или один из регистров процессора типа R0 … RN.
Пока выполняется команда, устройство управления готовит адрес следующей команды и операция повторяется с очередной командой. Таким образом, производится автоматическое исполнение программы.
Некоторые из команд обозначают не арифметические или логические операции, а операции, выполняемые самим устройством управления. Это могут быть команды, указывающие об изменении следования их последовательности, так называемые безусловные передачи управления, при выполнении которых вместо очередного по порядку адреса команды, выбирается адрес, указанный в инструкции (команде) передачи управления или определенный каким-либо другим способом. Могут быть и условные передачи управления, при которых формирование адреса следующей команды зависит от выполнения условия - полученного в предыдущем вычислении результата, например, от знака результата предыдущего вычисления.
Операции, связанные с использованием внешних устройств машины заключаются в передаче результатов работы вычислителя из памяти машины на какое–либо устройство вывода (принтер или построитель графиков, например) или в получении от устройств ввода дополнительных команд или исходных данных, необходимых программе, которые записываются в память по адресам, содержащимся в командах.
В показанной на рисунке 3.1 архитектуре вычислительной машины реализованы две фундаментальные идеи, используемые с тех пор и по настоящее время во всех типах и структурах машин.
Первая заключается в том, что управляющая программа, вычислительная программа и исходные данные для нее, хранятся в одной неразделенной памяти машины – такую архитектуру назвали Фон-Неймановской. Это обеспечивает оперативное переключение машины с одной задачи на другую, без внесения каких-либо изменений в схему или структуру машины, делая ее универсальным вычислительным инструментом.
Вторая идея состоит в том, что вся информация в машине закодирована в виде двоичных чисел (сами числа, команды, символы) и в этом смысле ее нельзя различить. Это дает возможность интерпретировать любую информацию в виде чисел и оперировать ею как числами. В результате, одну и ту же преобразованную информацию, можно рассматривать или как число, или как команду. Таким образом, при исполнении некоторой пользовательской программы одновременно может происходить ее преобразование, по-другому – формирование новой программы. Структура вычисли-
тельной машины тесно связана с технологией производства составляющих ее комплектующих элементов, и общими достижениями в области технологий. А так как эти технологии совершенствуются и развиваются, то же происходит и со структурами вычислительных машин. Обновление и того и другого производится с периодичностью, в среднем, десять лет. То есть каждые десять лет появляются новые поколения вычислительных средств.
3.1.2 Развитие структуры вычислительных машин в машинах второго поколения
Рассматривая архитектуру вычислительных машин нельзя пропустить рассмотрение ее развития в машинах следующих поко-лений, так как результаты решения проблем, возникающих при их конструировании, в том или ином виде реализованы и в современных машинах.
Второе поколение ЭВМ строилось на основе полупроводниковой техники (транзисторы, диоды) и магнитных элементов. Если в машинах первого поколения конструкторы стремились использовать минимум оборудования, рассчитывая получить, возможно, большее время безотказной работы (по терминологии специалистов по надежности - время наработки на отказ), чтобы повысить эффективность машины. То теперь, на первый план выдвинулось стремление получить возможно большее быстродействие, или объем памяти или другие характеристики, дающие эффект на каждую единицу оборудования. Структурные особенности машины второго поколения отражены на рисунке. 3.3.
Рисунок отражает структурные особенности машин этого поколения. Введена аппаратура преобразования адресов, отражен начальный этап перехода памяти машины к иерархической структуре, появилось децентрализованное управление процессом ввода и вывода – канал, и в связи с этим в составе устройства управления появилась более или менее развитая система прерывания программ. Теперь устройство управления и арифметическое устройство стали называть центральным процессором машины, а цен-тральный процессор вместе с оперативной памятью – центральной частью машины. Всю остальную аппаратуру машины стали называть периферийной частью машины.
Введение аппаратуры преобразования адресов ориентировалось на типовую ситуацию выполнения программ, имеющих циклически повторяющиеся цепочки команд, адреса которых изменяются от одного прохождения цикла к другому на одинаковую величину от своих первоначальных значений. Эту величину назвали индексом адреса и, добавляя или не добавляя ее к модифицируемому адресу, получали адрес следующей команды. Для хранения индекса в машину (в процессор) ввели дополнительный, так называемый, индексный регистр.
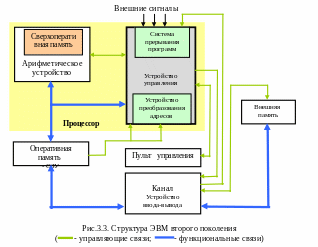
В список операций устройства управления процессора ввели операции занесения в индексный регистр какого-либо числа из памяти, добавления к содержимому индексного регистра числа из памяти или сравнения содержимого индексного регистра с числом из памяти. Это усложнение структурной схемы формирования адресов имело далеко идущие последствия. Конечно, в машинах следующих поколений схемы формирования исполнительных адресов существенно усложнялись, а их функции становились более обширными. Однако в самом начале развития вычислительной техники была решена задача разгрузки процессора от выполнения операций по модификации адресов инструкций.
Другой отмеченной особенностью структуры была названа иерархия памяти. Как известно, все пользователи вычислительной техники обращают внимание на объем памяти машины и ее быстродействие. Известно также, что для работающих программ очень важно быстродействие памяти, а для хранящихся - важнее ее объем. В связи с этим, в современных машинах имеется обычно несколько различных запоминающих устройств, образующих иерархию памяти. В структуре машин второго поколения наряду с оперативной памятью появились устройства сверхоперативной памяти и внешней памяти.
Сверхоперативная память была представлена одним или несколькими регистрами конструктивно и логически относящимися к арифметическому устройству. В качестве внешней памяти использовались магнитные барабаны, магнитные ленты, а позднее – магнитные диски.
Децентрализация управления вводом-выводом обеспечила возможность совмещения выполнения процессором вычислительных операций с операциями ввода или вывода данных. Устройство управления процессором дает указание устройству управления вводом-выводом о том, какие операции требуется выполнить, после чего последнее независимым образом, автономно, осуществляет их выполнение.
Устройства управления вводом-выводом стали снабжать своим специализированным процессором и автономной памятью, что позволило иметь дополнительную возможность обработки (редактирования) входной или выходной информации. Теперь они получили название «канал» - по современной терминологии.
Введенная в структуру процессора система прерывания программ явилась еще одной особенностью машин второго поколения. Эта система обеспечила, как минимум, возможность сообщить центральному процессору об окончании заданной работы устройством ввода-вывода, а также разрешение других, непредвиденных ситуаций. Например, когда массив памяти, отведенный под вводи-мую информацию, заполнен, а информация продолжает поступать. В таком случае в центральном процессоре должно произойти прерывание выполняемой программы, запоминание информации, необходимой в дальнейшем для возобновления ее работы и включение другой программы, которая обеспечит выход из сложившейся ситуации. Система прерываний, обеспечившая взаимодействие центрального процессора и устройств ввода-вывода, оказалась нужной и для других случаев. Например, для синхронизации работы машины и управляемого ею производственного процесса, протекающего в реальном масштабе времени, для программной обработки сигналов аппаратного контроля неисправностей, при взаимодействии нескольких машин и в ряде других случаев.
Первейшей заботой разработчиков вычислительных машин с самого начала и до настоящего времени была и остается увеличение их производительности. В связи с этим основным режимом обработки данных в машинах второго поколения был выбран режим, так называемой, пакетной обработки. Выглядит он в общих чертах следующим образом. Задачи, то есть программы, набивались на перфокартах, которые складывались в колоды. Подготовленные к определенному времени для решения на машине задачи, в виде колод, собираются вместе и вкладываются в приемное считываю-
щее устройство машины одна за другой. Получается единый массив – пакет. Пакет начинает обрабатываться специальной программой, названной супервизором и являющейся частью, так называемой, операционной системы. Программа-супервизор присутствует в оперативной памяти машины постоянно.
Начав работу, супервизор запускает ввод исходной информации первой задачи (программы), а затем одновременно счет по первой программе и ввод исходной информации второй програм-мы. Далее следует вывод информации, полученной при счете первой программы (если таковая уже есть), счет второй программы и ввод исходной информации третьей программы и т.д. циклически. Операции, связанные с вводом задач, набором начального адреса первой программы, выполняются один раз только при запуске пакета сразу на N П задач. Пакетная обработка, увеличила эффек-тивность использования оборудования машины, увеличила скорость прохождения большой совокупности задач. Но при этом увеличилось время получения результата для каждой отдельной задачи.
Развитие архитектуры в машинах третьего
поколения
Естественным оказалось дальнейшее совершенствование архитектуры вычислительных машин, так называемого, третьего по-коления. Прежде всего, усовершенствование коснулось централь-ной части машины. В состав центрального процессора стали включать несколько специализированных устройств, например, для выполнения действий над данными в форме с фиксированной запятой, арифметическое устройство для выполнения операций над данными с плавающей запятой, для операций с десятичными числами, операций деления и т.д.
Устройство управления процессора, прочитав из оперативной памяти очередную инструкцию (команду) программы, расшифровывает ее и определяет, какая операция должна быть выполнена. В зависимости от этого определяется устройство – специализированный процессор, который ее и реализует. Наличие нескольких специализированных устройств в процессоре не только преследует цель повышения быстродействия машины, но и предоставляет заказчику возможность выбрать тот состав устройств, который ему нужен, и не брать те, которые ему не понадобятся.
В машинах этого поколения устройство преобразования адресов заменило устройство формирования адресов, которое наряду с функциями индексации в современных машинах обеспечивает возможности перемещаемости в памяти программ и данных и ряд других.
Усовершенствовалось устройство памяти, позволившее, за счет усложнения ее структуры, размещать данные и инструкции программ в различных ее частях. Появилась, так называемая, виртуальная память, дающая возможность программам обращаться к данным и инструкциям по логическим (виртуальным) адресам, которые устройством управления памятью преобразуются в физические адреса, представляющие собой номера ячеек памяти, где фактически находятся данные и инструкции исполняемых программ.
Расширилась периферийная часть машины. Появилось значительное число периферийных процессоров, выполняющих многочисленные функции, связанные с вводом-выводом информации.
С появлением машин третьего поколения изменились возможности взаимодействия пользователей с машинами. Появились многочисленные терминальные устройства: телетайпы, электрические пишущие машинки, устройства на основе электронно-лучевых трубок и дополнительной клавиатуры. Терминальные устройства или просто терминалы стали интерпретироваться операционной системой машины как пульты управления. Это резко увеличило количество пользователей машин и привело к необходимости изменения режима их взаимодействия с ЭВМ. Возникла и была реализована идея разделения времени, основное содержание которой заключается в следующем.
Программа-супервизор владеет некоторым, никем и ни чем не занимаемым, разделом памяти, в который она помещает сообщения, поступающие от терминалов пользователей, содержащие оп-ределенные указания операционной системе. Получив очередное сообщение от терминала, и расшифровав его, операционная система передает управление программе-супервизору, который, выделив определенное время, запускает требуемую исполняющую программу и, может быть какую-то фоновую программу, исполняемую в автоматическом режиме. После этого проверяет свой раздел памяти на предмет наличия или отсутствия следующих обращений пользователей. По истечении времени, выделенного предыдущему обращению, супервизор, выделив также отрезок времени, запускает в работу программу, на основании обращения следующего пользователя и опять сканирует свою память. Действия повторяются до тех пор, пока не будут обслужены запросы всех обратившихся пользователей. Затем снова наступит очередь первого обратившегося с запросом пользователя и далее по кольцу. Таким образом, обслуживаются последовательно все пользователи в пределах выделенного для каждого времени. Но, поскольку эти действия выполняются с огромной скоростью, пользователи не замечают тех промежутков времени, в которые они не обслуживаются супервизором. У них создается иллюзия единоличного пользования машиной.
Еще одна новинка появилась в машинах этого поколения – таймер. Таймер подключается к устройству управления (см. рис. 3.2) и является специальным устройством в составе машины, счетчиком времени или электронными часами. Запуская на исполнение какую-либо программу пользователя, супервизор засылает в таймер некоторую величину интервала времени, который он отвел для работы пользователя. По прошествии указанного интервала таймер прерывает исполнение программы пользователя и вновь передает управление супервизору.
Машины третьего поколения далеко продвинули как возможности самих ЭВМ, так и возможности пользователей. За ними, естественно последовали следующие поколения машин, но теперь последние стали различать не поколениями архитектуры, а системами форм представления, по-современному говорят – парадигмой.