

3 Баланс Навантаження і толерантність дефекту (Частина 2)
Ця частина відображає роботу, пов'язану з повторним поширенням робочого навантаження для толерантності дефекту системи і визначення і класифікація дефектів.
Важливе питання у багатопроцесорній системі - те, як перерозподілити робоче навантаження у випадку дефекту між одним або більше процессорами. У такому разі завантаження треба перерозподілити
на інші процесори в максимальній рівновазі завантаження.
Проблема балансу наванаження може бути дескриптором динамічних алгоритмів розподілу ресурсів, де передача рішення залежить від фактичного поточного системного стану, або статичних алгоритмів розподілу ресурсів, які є загалом засновані на інформації середньої поведінки системи. Передача рішення є незалежною від фактичного поточного системного стану. Це робить їх менш складними,ніж динамічні алгоритми розподілу ресурсів
Система толерантності дефекту - "якщо незважаючи на програми може належним чином виконуватися подія логічних дефектів". Крішна і Шін визначають толерантність дефекту як "здатність системи, відповісти граціозно на несподіване технічне забезпечення чи програмну помилку". Тому, існує багато відмовостійких обчислювальних систем з дзеркальними операціями: наприклад, кожна операція виконується на двох або більше подвійних системах в тому сенсі, що, якщо один терпить невдачу, інший може прийняти його роботу. У цій техніці також використано кластери Фістер, [54]. У Крістіана, [14] толерантність дефекту для поширюваного обчислення обговорюється з різних точок зору. Окрім апаратних відмов, переривчасті відмови можуть відбуватися із-за програмного забезпечення події. У Вайді, [61] "дворівнева" схема відновлення представлена і оцінена. Схема відовлення була здійснена на групі. Автори оцінюють дію в часі очікування контрольної точки на виконанні схеми відовлення. Для операційно-орієнтованих систем, ГІленб [22] запропонував "підхід багатьох перевірочних точок», подібний до багаторівневої схеми відовлення що був показаний [61]. Математична модель операційно-орієнтованої системи для переривчастих відмов пропонується Чаблідогом і Гілєнбом [24]. Тут система працює по схемі «стандартного відновленя по тестовим очкам». Чаблідога і Гілєнб [9 і 23] пропонують декілька алгоритмів, які можуть виявити відмови завдань і повторний запуск невдалих завдання. Вони аналізують поведінку паралельних програм, представлених випадковим графіком завдань у багатопроцесорному середовищі. Проте, усі ці алгоритми діють динамічно.
Якщо єдиний елемент технічного забезпечення або програмного забезпечення терпить невдачу і система чере це також збоїть, ми називаємо це «єдиний покажчик відмови» (Фістер, 54). У дисертації ми дивимося на більш покращений сценарій, де може відбуватися довільний ряд дефектів, тобто ми розглядаємо систему без єдиного покажчика відмови. (відмовостійку)
3.1 Модель Дефекту
Відмова - "подія, яка відбувається, коли доручена служба відхиляється від правильної
служби". "Відхилення - помилка". "Помилка що з’явилась або про неї було оголошено ми називаємо «дефект»". Події можуть бути представлені, як в Мал. 3.
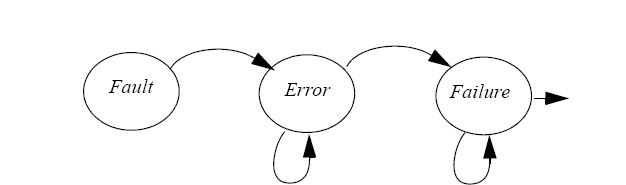
Авізеніс [3] показував елементарні класи дефекту згідно з восьмома основними точками зору : фаза створення або події, системних меж, феноменологічної причини, міра, мета, намір, можливість і постійність, де кожна з точок зору складається з двох додаткових точок зору. Якщо б усі комбінації були можливі тоді це б склало б 256 різних комбінованих класів ([3]) дефекту.
Класифікація поведінки дефекту процесорів або диспетчерів комунікації така:
- збійний дефект - процесор зупиняється при обчисленні доручення передачі;
- дефект викреслювання - пропустивши доручення, процесор втрачає свій вміст;
- Дефект затримки - повідомлення прибуває надто пізно або рано;
- дефект, що застопорюється при помилках, - доручення утримується від виконання, можливо назавжди;
- Візантійський дефект - процесор, можливо, робить що-небудь (Cristian, [14]).
З точки зору появи подій, дефекти можуть бути класифіковані:
- швидкоплинний дефект - дефект починається в специфічний час, залишається в системі для чогось і зникає;
- постійний дефект - дефект починається в специфічний час і залишається в системі, допоки його не відремонтують;
- переривчастий дефект (плаваючий) – то з’являється то зникає.
Основну увагу просимо вас звернути на Статті 3 і 4, що присвячені перманентним збоям.