

Постройте доверительный интервал для оценки математического ожидания объединенной выборки. Сравнить со значениями, вычисленными в лабораторной работе № 1.
5. Контрольные вопросы
Какие выборки называются однородными?
Какие значения основных статистических параметров должны иметь однородные выборки?
Как выполняется проверка гипотезы о равенстве дисперсий?
Как выполняется проверка гипотезы о равенстве математических ожиданий?
В каком случае можно объединять две выборки?
ЛАБОРАТОРНАЯ РАБОТА № 5 ОБЪЕДИНЕНИЕ СЕРИЙ НЕРАВНОТОЧНЫХ ИЗМЕРЕНИЙ /двухвыборочный t-тест для средних/
1. Цель работы
Изучить основные особенности и методы объединения результатов разных серий измерений в общий массив значений.
2. Задание
Выполнить объединение двух выборок разного объема из разных нормальных совокупностей с одинаковым математическим ожиданием и разной дисперсией, используя приближенный двухвыборочный t-критерий.
3. Краткая теория
В предыдущей работе была рассмотрена процедура проверки гипотезы о равенстве средних (математических ожиданий) двух нормальных распределений с неизвестными дисперсиями. При этом делалось предположение о равенстве дисперсий между собой.
Если при анализе результатов измерений была обнаружена неравноточность серий (условие (4.3) работы № 4 не выполнено), то гипотезу о равенстве математических ожиданий можно проверить по приближенному критерию:
 , (5.1)
, (5.1)
где
 .
(5.2)
.
(5.2)
Статистика t в выражении (5.1) подчиняется распределению Беренса-Фишера, пользование которым весьма затруднительно из-за отсутствия нужных таблиц и сложности процедуры пользования имеющимися. Приближенное выражение (5.2) позволяет пользоваться таблицами t-распределения.
Если обнаружена неравноточность
измерений в сериях, но серии однородны
по условию (5.1), при совместной их обработке
неравноточность учитывается при расчете
среднего арифметического введением
весов
![]() ,
а вычисления выполняются по формулам:
,
а вычисления выполняются по формулам:
 (5.3)
(5.3)
где
![]() выборочные средние,
выборочные средние,
![]() общее среднее (среднее арифметическое
объединенных серий),
общее среднее (среднее арифметическое
объединенных серий),
![]() выборочные оценки дисперсии.
выборочные оценки дисперсии.
Из курса теории вероятностей известно, что случайная величина в виде суммы двух случайных нормальных величин имеет также нормальное распределение. Однако в данном случае нельзя говорить о сумме случайных величин. Мы имеем дело со смесью двух распределений, нормальных, но с разными параметрами. Закон распределения такой смеси идентифицировать нельзя – он зависит от объемов выборок и от параметров обоих распределений. Чтобы убедиться в этом, можно построить гистограмму для объединенного массива для заметно различающихся объемов выборок, дисперсий или математических ожиданий (последнее наиболее наглядно покажет правильность нашего утверждения).
По этой причине
оценивание математического ожидания
доверительным интервалом Стьюдента
будет весьма приближенным. По этой же
причине мы не рекомендуем вычислять
оценку СКО для объединенного массива
как не имеющую смысла при неизвестном
законе распределения. Наконец, по этой
же причине в метрологии при объединении
неравноточных результатов обычно
ограничиваются указанием значения
![]() .
Можно воспользоваться интервалом
Чебышева, хотя скорее всего он будет
излишне широким.
.
Можно воспользоваться интервалом
Чебышева, хотя скорее всего он будет
излишне широким.
Интервал Чебышева – интервал вероятности для случайной величины, распределенной по любому закону, но с конечными математическим ожиданием и дисперсией, имеет вид (в качестве случайной величины используем общее среднее):
![]()
Поскольку
![]() неизвестна, воспользуемся ее оценкой
по последней формуле из (5.3). Задавшись
вероятностью, например, 0.90, мы приближенно
получим
неизвестна, воспользуемся ее оценкой
по последней формуле из (5.3). Задавшись
вероятностью, например, 0.90, мы приближенно
получим
![]() откуда приближенный доверительный
интервал Чебышева примет вид:
откуда приближенный доверительный
интервал Чебышева примет вид:
![]() (5.4)
(5.4)
при доверительной вероятности 0.90 (напомним, что для конкретного численного доверительного интервала следует говорить «при надежности 0.90»).
4. Ход работы
Получите n1i~N(5;4) и n2i~N(5;1), – две серии случайных чисел, распределенных по нормальному закону, с математическим ожиданием равным 5, и дисперсиями равными 4 и 1 соответственно (для этого выполните шаги п.2, лабораторной работы № 1). Размерность серий может быть произвольной, необязательно одинаковой.
Выполните расчет двухвыборочного F-теста для дисперсий, используя одноименный инструмент надстройки Анализ данных (см. рис. 4.1 лаб. работы № 4).
Таблица результатов работы надстройки «Двухвыборочный F-тест для дисперсий» для данной работы представлена на рис. 5.1.
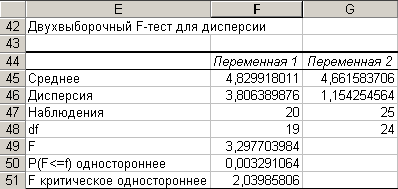
Рис. 5.1. Таблица результатов расчета F-теста
Обратите внимание, что в качестве Интервала переменной1 выбрана серия с большим значением оценки дисперсии, а в качестве Интервала переменной2 – с меньшей.
Проверьте гипотезу
 о равенстве дисперсий в сериях n1
и n2 по таблице значений
параметров надстройки «Двухвыборочный
F-тест для дисперсий»
(рис. 5.1).
о равенстве дисперсий в сериях n1
и n2 по таблице значений
параметров надстройки «Двухвыборочный
F-тест для дисперсий»
(рис. 5.1).
Основное описание работы F-теста приведено в лаб. работе № 4.
По формулам, описанным в предыдущей лаб. работе, получены следующие двусторонние критические значения (см. рис. 5.1) = = 0,407776923 и = 2,345153405. Таким образом, при двусторонней оценке получим критическую область как объединение двух интервалов
 .
.
Однако и в случае двусторонних оценок значение критерия F принадлежит правому критическому интервалу, следовательно, гипотеза
 не принимается.
не принимается.
Сравните расчетное значение F с параметром F критическое одностороннее по формуле (4.3), если F Fкр., гипотеза также не принимается.
В случае, если в качестве Интервала переменной1 указана серия с меньшим значением оценки дисперсии, то тогда для расчетного значения F и F критического одностороннего необходимо найти их обратные значения, которые и необходимо сравнивать по формуле (4.3). Для вычисления F критического одностороннего также подходит формула =FРАСПОБР(0,05;G48;F48), где ячейки F48 и G48 содержат значения соответствующего числа степеней свободы выборок.
Выполните проверку однородности (гипотезу
 о равенстве математических ожиданий)
серий измерений по таблице значений
параметров надстройки «Двухвыборочный
t-тест с различными дисперсиями»
(рис. 5.2). Значения Среднего (ячейки
F60 и G60),
Дисперсии (ячейки F61 и G61)
рассчитываются с помощью соответствующих
функций, описанных в лаб. работе №
1.
о равенстве математических ожиданий)
серий измерений по таблице значений
параметров надстройки «Двухвыборочный
t-тест с различными дисперсиями»
(рис. 5.2). Значения Среднего (ячейки
F60 и G60),
Дисперсии (ячейки F61 и G61)
рассчитываются с помощью соответствующих
функций, описанных в лаб. работе №
1.
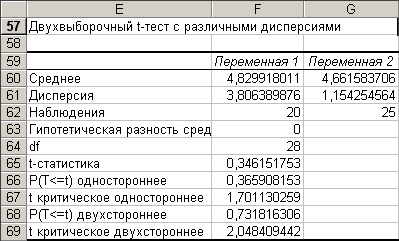
Рис. 5.2. Таблица результатов расчета t-теста
Число степеней свободы (показатель df) рассчитывается в ячейке F64 по формуле (5.2). В синтаксисе Excel это выражение запишется так:
=((F61/F62+G61/G62)^2/((F61/F62)^2/(F62+1)+(G61/G62)^2/(G62+1))-2)
После этого полученное значение округляется в меньшую сторону функцией ОКРУГЛВНИЗ до целого, для чего вторым аргументом записывается нуль.
Основной показатель данной надстройки t-статистика вычисляется согласно формуле (5.1). В синтаксисе Excel формула примет следующий вид:
=ABS(F60-G60)/КОРЕНЬ(F61/F62+G61/G62)
Здесь значения функций, применяемых в формуле интуитивно понятны. В случае сомнений см. Справочную систему Excel.
Модуль значения t критического двустороннего вычисляется в ячейке F69 по формуле =СТЬЮДРАСПОБР(0,05;F64). Сведения по функции СТЬЮДРАСПОБР можно найти в лаб. работе № 2.
Для расчета значения одностороннего (ячейка F66) и двустороннего (ячейка F68) -значения t-теста можно использовать функцию ТТЕСТ, родственную режиму «Двухвыборочный t-тест с одинаковыми дисперсиями» (рис. 5.2). Сведения по функции ТТЕСТ приведены в лаб. работе № 4.
Для случая различных дисперсий P(T<=t) одностороннее (ячейка F66 рис. 5.2) вычисляется по формуле
=СТЬЮДРАСП(F65;F64;1).
Сравните полученное значение с вычисленным по формуле
=ТТЕСТ(A43:A62;C43:C67;1;3),
для неокругленного числа степеней свободы.
Значение P(T<=t) двустороннего (ячейка F68 рис. 5.2) вычисляется по формуле
=СТЬЮДРАСП(F65;F64;2).
Сравните полученное значение с вычисленным по формуле
=ТТЕСТ(A43:A62;C43:C67;2;3),
для неокругленного числа степеней свободы.
Сравните значение t-статистики с t критическим односторонним или двусторонним. Для принятия гипотезы значение t-статистики не должно попадать ни в один из критических интервалов
 .
Так как условие
(5.1) выполняется, а также значение
t-статистики
не попадает ни в один критический
интервал, то гипотезу
о равенстве математических ожиданий
принимаем.
.
Так как условие
(5.1) выполняется, а также значение
t-статистики
не попадает ни в один критический
интервал, то гипотезу
о равенстве математических ожиданий
принимаем.
Для объединения однородных неравноточных серий результатов измерений выполните расчет основных статистически параметров, используя формулы (5.3).
Постройте доверительный интервал для оценки математического ожидания объединенной выборки по формуле (5.4). Сравните со значениями, вычисленными в лабораторной работе № 1.
Постройте гистограмму частот с равным шагом, как описано в работе 2. Сравните свою гистограмму с гистограммами других студентов, сделайте вывод.
5. Контрольные вопросы
В каком случае нельзя объединять две выборки данных?
Почему закон распределения объединенного массива неравноточных выборок оказывается отличным от нормального?
Какой доверительный интервал для математического ожидания шире – Стьюдента или Чебышева и по какой причине?
Предположим, Вы по объединенному массиву проверили гипотезу о нормальности распределения и не отвергли ее. Каким доверительным интервалом для математического ожидания Вы воспользуетесь?
ЛАБОРАТОРНАЯ РАБОТА № 6 ПОСТРОЕНИЕ ЛИНЕЙНОЙ ЭМПИРИЧЕСКОЙ ЗАВИСИМОСТИ ПО ОПЫТНЫМ ДАННЫМ /метод наименьших квадратов/
1. Цель работы
Изучить основные особенности и методы построения линейного приближения экспериментальных данных.
2. Задание
Методом наименьших квадратов построить линейную эмпирическую зависимость по опытным данным. Выполнить проверку адекватности математической модели опытным данным с помощью статистических критериев. Оценить погрешность эмпирической зависимости совместными доверительными F-интервалами.
3. Краткая теория
Метод наименьших квадратов
Одновременные измерения двух или более
разнородных физических величин с целью
нахождения зависимости между ними
называются совместными измерениями
[2]. Обычно выполняется
измерений, при которых в заданных или
точно измеренных значениях аргумента
![]() определены значения функции
определены значения функции
![]() .
Задача состоит в том, чтобы по
парам (
.
Задача состоит в том, чтобы по
парам (![]() ,
,![]() )
построить зависимость (эмпирическую),
которая была бы несмещенной и эффективной
оценкой истинной зависимости, общий
вид которой считают известным. Например,
известно, что истинная зависимость есть
прямая линия, представленная в виде
)
построить зависимость (эмпирическую),
которая была бы несмещенной и эффективной
оценкой истинной зависимости, общий
вид которой считают известным. Например,
известно, что истинная зависимость есть
прямая линия, представленная в виде
![]() .
(6.1)
.
(6.1)
Параметры
![]() ,
,
![]() неизвестны, их следует оценить по опытным
данным. Будем считать ошибки измерений
неизвестны, их следует оценить по опытным
данным. Будем считать ошибки измерений
![]() случайными с нулевым математическим
ожиданием и дисперсией
случайными с нулевым математическим
ожиданием и дисперсией
![]() при любом
,
а также некоррелированными для разных
.
При этих условиях найти несмещенные и
эффективные оценки
при любом
,
а также некоррелированными для разных
.
При этих условиях найти несмещенные и
эффективные оценки
![]() ,
,
![]() параметров
,
(а следовательно и зависимости (6.1) в
целом) можно с помощью метода наименьших
квадратов (МНК).
параметров
,
(а следовательно и зависимости (6.1) в
целом) можно с помощью метода наименьших
квадратов (МНК).
Будем определять оценку
![]() функции
функции
![]() в виде
в виде
![]() ,
(6.2)
,
(6.2)
а оценки , искать таким способом, чтобы сумма квадратов отклонений от по всем узлам была минимальной (этот подход называют также принципом Лежандра):
![]() .
(6.3)
.
(6.3)
Это эквивалентно условию
![]() ,
что приводит к уравнениям вида:
,
что приводит к уравнениям вида:
 (6.4)
(6.4)
Учитывая, что
,
– некоторые числа, при этом
![]() ,
получаем
,
получаем
 (6.5)
(6.5)
Отметим, что если бы мы записали выражение
(6.1) в обычном виде
![]() ,
мы вынуждены были бы решать систему
уравнений, выражая параметры один через
другой и проводя более сложные вычисления.
Использование линейной зависимости в
виде (6.1) позволило упростить вычисления
(что очень важно для более сложных
зависимостей) и получить статистически
независимые оценки
,
мы вынуждены были бы решать систему
уравнений, выражая параметры один через
другой и проводя более сложные вычисления.
Использование линейной зависимости в
виде (6.1) позволило упростить вычисления
(что очень важно для более сложных
зависимостей) и получить статистически
независимые оценки
![]() и
и
![]() .
.
Учитывая это свойство, можно записать:

Переходя к оценкам, получаем:
 (6.6)
(6.6)
При любом законе распределения (если удовлетворяются указанные выше условия) несмещенной оценкой (а при нормальном законе распределения и эффективной) является остаточная дисперсия
 , (6.7)
, (6.7)
где
![]() – число коэффициентов регрессии (для
прямой линии
=2).
– число коэффициентов регрессии (для
прямой линии
=2).
Окончательно получаем
 , (6.8)
, (6.8)
то есть оценка СКО
является функцией от
.
Значение
![]() минимально при
минимально при
![]() и увеличивается к началу и к концу
интервала значений аргумента.
и увеличивается к началу и к концу
интервала значений аргумента.
Статистическая проверка адекватности модели
Все приведенные выше выражения справедливы
при выполнении предположения о том, что
истинный вид зависимости заранее
известен, причем эта зависимость линейна
по искомым параметрам. Если же это не
так, что обычно и имеет место, то
утверждение о несмещенности оценок
,
параметров
![]() ,
,
![]() оценки
оценки
![]() дисперсии
и оценки
(эмпирической зависимости) неизвестной
истинной зависимости
становится необоснованным, и правильнее
исходить из предположения об их
смещенности. Для того, чтобы проверить
гипотезу о несмещенности модели (говорят
об адекватности модели опытным данным),
пользуются статистическими критериями.
дисперсии
и оценки
(эмпирической зависимости) неизвестной
истинной зависимости
становится необоснованным, и правильнее
исходить из предположения об их
смещенности. Для того, чтобы проверить
гипотезу о несмещенности модели (говорят
об адекватности модели опытным данным),
пользуются статистическими критериями.
Известный F-критерий
проверки адекватности модели опытным
данным использует статистику в виде
отношения остаточной дисперсии
(6.7) к независимой несмещенной оценке
дисперсии опытных данных
![]() ,
где
,
где
![]() – число степеней свободы этой оценки:
– число степеней свободы этой оценки:
 . (6.9)
. (6.9)
На практике исследователь часто не имеет в своем распоряжении независимой несмещенной оценки дисперсии опытных данных и не может воспользоваться критерием (6.9). В этом случае можно воспользоваться следующим критерием:
 . (6.10)
. (6.10)
Этот критерий использует статистику в
виде отношения двух последовательных
по числу параметров модели остаточных
дисперсий; здесь, как обычно, число
степеней свободы
![]() .
В нашем конкретном случае, когда модель
имеет вид прямой линии, остаточная
дисперсия (6.7) соответствует
.
В нашем конкретном случае, когда модель
имеет вид прямой линии, остаточная
дисперсия (6.7) соответствует
![]() (числитель статистики). Для нахождения
знаменателя следует перейти к более
сложной модели, содержащей не 2, а 3
параметра (параболе второй степени), и
найти для нее остаточную дисперсию.
Однако этот вопрос выходит за рамки
изучаемого курса, поэтому в данной
работе предполагается, что имеется
независимая несмещенная оценка дисперсии,
либо известна сама дисперсия
.
(числитель статистики). Для нахождения
знаменателя следует перейти к более
сложной модели, содержащей не 2, а 3
параметра (параболе второй степени), и
найти для нее остаточную дисперсию.
Однако этот вопрос выходит за рамки
изучаемого курса, поэтому в данной
работе предполагается, что имеется
независимая несмещенная оценка дисперсии,
либо известна сама дисперсия
.
Линейному регрессионному анализу посвящено множество работ разной сложности, из которых отметим [6, 12, 13, 14]. Наиболее доступно он изложен в [5, 6].
Оценивание погрешности эмпирической зависимости
Погрешность – это некий интервал, построенный в обе стороны от результата измерений и включающий в себя ("накрывающий") неизвестное истинное значение измеряемой физической величины с высокой вероятностью (с заданной или оцененной). Имея оценку СКО эмпирической зависимости (6.8), можно при каждом значении аргумента вычислить доверительные границы для истинного значения при данном значении аргумента, т.е. построить доверительный t-интервал для истинного значения при данном значении аргумента. Такие доверительные t-интервалы называются индивидуальными t-интервалами. Если повторять опыты (каждый раз с новыми опытными данными в тех же узлах) и следить за любым выбранным узлом, то доля индивидуальных t-интервалов, накрывающих истинное значение в этом узле (любом) будет в точности равна заданной доверительной вероятности. Однако, если мы будем следить за несколькими узлами (например, за всеми), то мы заметим, что доля узлов, в которых накрытие не имеет место в данном опыте, совсем не соответствует этой доверительной вероятности. Доля узлов, в которых накрытие не имеет места, может оказаться весьма значительной. От этого недостатка свободны так называемые совместные доверительные интервалы, которые обеспечивают одновременное накрытие истинных значений во всех узлах с вероятностью не меньше заданной.
Погрешность эмпирической зависимости будем выражать совместными доверительными интервалами [12, 5], например, F-интервалами Шеффе, которые проще всего вычислить (они имеют и более серьезные преимущества по сравнению с другими совместными интервалами). Интервалы Шеффе имеют вид:
![]() ,
(6.11)
,
(6.11)
где
![]() – критическое значение статистики f
для выбранного уровня значимости
– критическое значение статистики f
для выбранного уровня значимости
![]() и с числами степеней свободы
(числитель) и
и с числами степеней свободы
(числитель) и
![]() (знаменатель).
(знаменатель).
4. Ход работы
Для построения регрессионной прямой по методу наименьших квадратов можно воспользоваться двумя подходами: 1) решить систему линейных алгебраических уравнений, корнями которой будут коэффициенты и уравнения прямой регрессии (6.2); 2) воспользоваться встроенными функциями Microsoft Excel. Опишем оба подхода к решению задачи.
Вычислите вспомогательные суммы xi, yi, xi^2, yi*xi (функция СУММ(диапазон_значений) или кнопка на палитре инструментов со знаком 'сигма'), а также подсчитайте количество точек данных (функция СЧЕТ(диапазон_значений)). Составьте матрицу из полученных значений согласно формулам метода наименьших квадратов.
Для вычисления корней системы можно 1) найти обратную матрицу (функция МОБР(массив), при том надо помнить следующее, для того чтобы получить матрицу необходимо сначала выделить тот диапазон ячеек, в которых предполагается получить значения элементов обратной матрицы, затем ввести функцию в строке формул, и, наконец, нажать комбинацию клавиш CTRL+SHIFT+ENTER. Если нажать одну клавишу ENTER, то Excel вычислит только первый элемент матрицы. Это относится ко всем функциям массива Excel). Умножить обратную матрицу на столбец свободных членов (функция МУМНОЖ(массив1; массив2). Это также функция массива). В результате получаются коэффициенты прямой. 2) по методу Крамера вычислить определители системы и вспомогательные определители переменных (функция МОПРЕД(матрица) – для получения результата достаточно нажать ENTER). Затем вычислить корни системы – коэффициенты прямой.
Для реализации второго подхода нужно применить функцию ЛИНЕЙН, которая рассчитывает статистику для ряда с применением метода наименьших квадратов, для вычисления прямой линии, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Кроме того, нужно использовать функцию ИНДЕКС, с помощью которой можно выделить нужное значение.
Функция ЛИНЕЙН
Синтаксис:
ЛИНЕЙН(извест_значения_y;извест_значения_x;конст; статист)
Извест_значения_y – это множество значений y, которые уже известны для соотношения (6.2).
Замечания:
Если массив извест_значения_y имеет один столбец, то каждый столбец массива извест_значения_x интерпретируется как отдельная переменная.
Если массив извест_значения_y имеет одну строку, то каждая строка массива извест_значения_x интерпретируется как отдельная переменная. Извест_значения_x – это необязательное множество значений x, которые уже известны для соотношения (6.2). Массив извест_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то извест_значения_y и извест_значения_x могут быть массивами любой формы при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то извест_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец).
Если извест_значения_x опущены, то предполагается, что это массив {1;2;3;...} такого же размера как и извест_значения_y.
Конст
– это логическое значение, которое
указывает, требуется ли, чтобы константа
![]() была равна 0.
была равна 0.
Если конст имеет значение ИСТИНА или опущено, то вычисляется обычным образом. Если конст имеет значение ЛОЖЬ, то полагается равным 0.
Статистика – это логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если статистика имеет значение ИСТИНА, то функция ЛИНЕЙН возвращает дополнительную регрессионную статистику, так что возвращаемый массив будет иметь вид: {mn;mn-1;...;m1;b:sen;sen1;...;se1; seb:r2;sey:F;df:ssreg; ssresid}. Если статистика имеет значение ЛОЖЬ или опущена, то функция ЛИНЕЙН возвращает только коэффициенты и постоянную .
Функция ИНДЕКС
Синтаксис:
ИНДЕКС(массив;номер_строки;номер_столбца)
Массив – это интервал ячеек или массив констант. Номер_строки – это номер строки в массиве, из которой нужно возвращать значение. Если номер_строки опущен, то аргумент номер_столбца нужно задавать обязательно. Номер_столбца – это номер столбца в массиве, из которого нужно возвращать значение.
Замечания:
Если номер_столбца опущен, то аргумент номер_строки нужно задавать обязательно. Если используются оба аргумента номер_строки и номер_столбца, то функция ИНДЕКС возвращает значение, находящееся в ячейке на пересечении номер_строки и номер_столбца.
Если массив содержит только одну строку или один столбец, то соответствующий аргумент номер_строки или номер_столбца не является обязательным.
Если массив занимает больше, чем одну строку и больше, чем один столбец, а задан только один аргумент номер_строки или номер_столбца, то функция ИНДЕКС возвращает массив из целой строки или целого столбца аргумента массив.
Если задать номер_строки или номер_столбца равным 0 (нулю), то функция ИНДЕКС вернет массив значений для целого столбца или целой строки, соответственно. Для того, чтобы использовать значения, возвращаемые как массив, функцию ИНДЕКС нужно ввести как формулу массива в горизонтальный интервал ячеек. Для ввода формулы массива нажмите клавиши CTRL+SHIFT+ENTER.
Таким образом, для вычисления коэффициента
![]() в строке формул запишем:
в строке формул запишем:
=ИНДЕКС(ЛИНЕЙН(B2: B20;A2:A20);1).
Для вычисления коэффициента –
=ИНДЕКС(ЛИНЕЙН(B2:B20;A2:A20);2).
Полученные по обоим способам значения коэффициентов прямой будут идентичны.
Постройте столбец значений регрессионной прямой, вычисленных по формуле (6.2), где х – известные значения аргумента, и – коэффициенты, вычисленные одним из описанных способов.
Постройте графики исходной зависимости и МНК-прямой в одних осях (мастер диаграмм).
Вычислите значения оценки СКО для МНК-прямой и погрешности х по формуле
 в точках
.
в точках
.
Нанесите полученные значения погрешности на тот же график. Для точек МНК-прямой в диалоговом окне Формат рядов данных показать обе планки погрешностей по Х. Сравнить с вычисленными значениями погрешностей.
Выполните построение МНК-прямой и вычисление различных статистических параметров с помощью категорией «Регрессия» Пакета анализа Excel. Сравните полученные результаты с результатами предыдущих пунктов работы.
5. Контрольные вопросы
В чем суть метода наименьших квадратов построения линейной эмпирической зависимости? Сформулируйте принцип Лежандра.
Что такое остаточная дисперсия? Каковы статистические характеристики остаточной дисперсии при нормальном законе распределения?
Какие статистические критерии используются для проверки адекватности модели опытным данным при наличии и отсутствии независимой несмещенной оценки дисперсии?
Что такое погрешность? Как определить погрешность эмпирической зависимости?
ЛАБОРАТОРНАЯ РАБОТА № 7 ОЦЕНКА СВЯЗИ НОМИНАЛЬНЫХ ПРИЗНАКОВ /таблицы сопряженности/
1. Цель работы
Освоить элементарные приемы анализа таблиц сопряженности 22, в которых представлены результаты наблюдений в номинальных шкалах, с целью оценки связи номинальных признаков.
2. Задание
Создать с помощью генератора случайных
чисел 4 случайных двухзначных числа из
равномерной совокупности и представить
их в виде таблицы 22
для некоторых условных признаков
![]() Проверить гипотезу о независимости
признаков, вычислить коэффициент связи
Проверить гипотезу о независимости
признаков, вычислить коэффициент связи
![]()
3. Краткая теория
Начнем с примера. В приведенной ниже табл. 1 представлены сведения о числе людей, заболевших и не заболевших холерой с указанием, была ли им сделана противохолерная прививка (пример взят из [11]).
Таблица 1
-
Незаболевшие
Заболевшие
Всего
Привитые
1625
5
1630
Непривитые
1022
11
1033
Всего
2647
16
2663
Задача состоит в том, чтобы выяснить,
эффективна ли прививка, значимо ли ее
влияние на вероятность заболевания.
Видно, что доля заболевших среди
непривитых больше, чем среди привитых,
но не объясняется ли это случайными
факторами? Аналогичных примеров можно
привести множество – это и обработка
анкет разного рода, исследований
социологического, медицинского,
экономического характера, иначе говоря
– данных, представленных в номинальных
шкалах (вместо числового значения
указывается то или иное имя). Если
градация признаков и групп (будем
называть признаками «имена», указанные
в крайнем левом столбце, а группами –
указанные в верхней стоке) осуществлена
по принципу «да – нет», причем суммы по
нижней строке и правому столбцу совпадают,
то такая таблица называется таблицей
сопряженности (признаков) 22.
Отметим, что существуют таблицы
сопряженности размером
![]() ,
если группы и признаки разбиты на
подгруппы и уровни. Мы ограничимся
статистическим анализом таблицы
сопряженности 22.
Ознакомиться подробнее с таблицами
сопряженности и их обработкой можно по
[11].
,
если группы и признаки разбиты на
подгруппы и уровни. Мы ограничимся
статистическим анализом таблицы
сопряженности 22.
Ознакомиться подробнее с таблицами
сопряженности и их обработкой можно по
[11].
В качестве нулевой гипотезы примем
утверждение: прививка не оказывает
заметного влияния на вероятность
заболевания, а видимый эффект есть
следствие случайных вариаций числа
заболевших. На языке математической
статистики это звучит так: вероятность
заболевания для привитых и непривитых
равна одному и тому же значению
![]() Иначе можно записать так:
Иначе можно записать так:
![]()
Замечание: Мы сильно осложнили бы свою задачу, если бы в качестве нулевой гипотезы выдвинули противоположное утверждение о значимости влияния прививки, т.к. такая гипотеза оказывается множественной (нам пришлось бы указывать, насколько сильно влияние прививки, во сколько раз или на сколько она снижает вероятность заболевания).
Но вероятность
остается нам неизвестной, значит надо
воспользоваться ее оценкой. По теореме
о сходимости (по вероятности) относительной
частоты события к его вероятности такой
оценкой является средняя относительная
частота заболевания по всей исследуемой
выборке (по обеим группам):
![]() Соответственно, вероятность не заболеть
приблизительно равна
Соответственно, вероятность не заболеть
приблизительно равна
![]() Таким образом, нам следует сравнить
полученные в опыте частоты (
Таким образом, нам следует сравнить
полученные в опыте частоты (![]() )
с теоретическими, вычисленными в
предположении, что гипотеза
)
с теоретическими, вычисленными в
предположении, что гипотеза
![]() справедлива. Это проще всего сделать с
помощью известного из курса теории
вероятностей и математической статистики
критерия
справедлива. Это проще всего сделать с
помощью известного из курса теории
вероятностей и математической статистики
критерия
![]() .
Отметим, что это приближенный критерий,
существуют и другие, более точные
критерии, но они более сложны. Составим
новую таблицу, в которой наряду с
наблюдаемыми частотами (верхнее число
в каждой ячейке) укажем также ожидаемые
в предположении справедливости нулевой
гипотезы частоты, равные произведению
общего числа наблюдений
.
Отметим, что это приближенный критерий,
существуют и другие, более точные
критерии, но они более сложны. Составим
новую таблицу, в которой наряду с
наблюдаемыми частотами (верхнее число
в каждой ячейке) укажем также ожидаемые
в предположении справедливости нулевой
гипотезы частоты, равные произведению
общего числа наблюдений
![]() на соответствующие вероятности
или
на соответствующие вероятности
или
![]() (они указаны во второй строке ячеек в
круглых скобках).
В третьей строке
каждой ячейки укажем разность между
наблюдаемыми и теоретическими частотами
(в квадратных скобках).
(они указаны во второй строке ячеек в
круглых скобках).
В третьей строке
каждой ячейки укажем разность между
наблюдаемыми и теоретическими частотами
(в квадратных скобках).
Таблица 2
-
Привитые
1625
(1620.21)
[4.79]
5
(9.79)
[-4.79]
Непривитые
1022
(1026.79)
[-4.79]
11
(6.21)
[4.79]
Критерий согласия имеет вид:
![]() , (7.1)
, (7.1)
где
![]() – верхний
-предел
статистики
,
а число степеней свободы, как обычно,
равно общему числу слагаемых минус 1 и
минус число уравнений связи
– верхний
-предел
статистики
,
а число степеней свободы, как обычно,
равно общему числу слагаемых минус 1 и
минус число уравнений связи
![]() (7.2)
(7.2)
Общее число слагаемых (мы имеем двойную
сумму) равно 4, а число уравнений связи
равно 2 (сумма по строкам равна сумме по
столбцам и равна
),
т.е.
![]() Обратите внимание на то, что разности
между частотами в каждой ячейке равны
по модулю, т.е. чтобы найти их нужно
сделать лишь одно вычисление.
Обратите внимание на то, что разности
между частотами в каждой ячейке равны
по модулю, т.е. чтобы найти их нужно
сделать лишь одно вычисление.
Найдем наблюденное значение статистики критерия:
![]()
По таблице процентных точек распределения путем интерполяции найдем приближенное значение :
уровню значимости 2.5 % соответствует предел
 ;
;уровню значимости 1 % соответствует предел
 .
.
Следовательно, значение 6.07 соответствует
уровню значимости
![]()
Это и есть «уровень значимости нулевой гипотезы», он слишком мал, чтобы считать гипотезу верной. Опыт вынуждает нас отклонить гипотезу о том, что прививка не оказывает влияния на вероятность заболевания, и мы приходим к выводу, что прививка заметно уменьшает эту вероятность.
4. Ход работы
Создайте таблицу сопряженности размерностью 22. Для этого вспомните ситуацию из личного опыта о наличии (отсутствии) некоторого признака у двух групп людей (социологическое исследование). Ситуация должны быть типа «да-нет», т.е. в первой строке предполагается наличие признака, во второй – его отсутствие (см. табл. 1).
Укажите названия признаков в первом столбце таблицы и названия групп в верхней строке (если затрудняетесь, то в качестве имен укажите числительные «первая», «вторая»).
Выполните генерацию случайных чисел, распределенных по равномерному закону (см. лаб. работу № 1). Каждое полученное число умножьте на 1000 и округлите до целого (подумайте почему?)
Найдите суммы полученных значений по строкам, столбцам и общую сумму.
В отдельной таблице рассчитайте теоретические частоты для выбранной гипотезы
 по формуле
по формуле
 ,
где
,
где
 – сумма значений по строке;
– сумма значений по строке;
 – сумма значений по столбцу;
– общая сумма (общее число наблюдений).
Пользуйтесь абсолютными ссылками!
– сумма значений по столбцу;
– общая сумма (общее число наблюдений).
Пользуйтесь абсолютными ссылками!Для контроля значений теоретических частот вычислите суммы. Они должны совпадать с вычисленными в исходной таблице.
Вычислите значение статистики
 по формуле (7.1). При необходимости
сформируйте вспомогательную таблицу
значений выражения под знаком суммы.
по формуле (7.1). При необходимости
сформируйте вспомогательную таблицу
значений выражения под знаком суммы.По таблице процентных точек распределения определите уровень значимости . Вычислите критическое значение с помощью функции Excel ХИ2РАСП(х;Степени_свободы) (см. лаб. раб. № 3 «Проверка нормальности…»). Сделайте вывод о принятии гипотезы .
5. Контрольные вопросы
Какие признаки называются номинальными?
В каких случаях используются таблицы сопряженности признаков?
Какую гипотезу и почему выдвигают при обработке таблиц сопряженности?
На основании чего делается вывод о зависимости признаков?
Заключение
В пособии рассмотрены лишь 7 задач по обработке данных, но эти задачи являются основными и на их базе строится дальнейший, более глубокий анализ результатов измерений и наблюдений. Приведенные в них теоретические сведения довольно кратки, но их достаточно для понимания того, какие именно операции выполняет или должен выполнить компьютер. В любом случае студенту на этапе освоения пакета электронных таблиц MS Excel в части применения его к решению описанных задач, рекомендуется внимательно ознакомиться с прил. 1–3, в которых отмечены как тонкости процедур диалога с компьютером, так и типичные ошибки операторов. Полезно также контролировать правильность действий и получаемые результаты с помощью отдельных контрольных операций с использованием статистических таблиц, приведенных в прил. 4.
Отметим в заключение, что хотя пакет Excel не является наилучшим статистическим пакетом, его широкое распространение в различных сферах человеческой деятельности послужили толчком к составлению данного сборника.
«Цель вычислений – понимание, а не числа» (Р. Хэмминг).
Приложение 1 Установка надстройки "Пакет анализа"
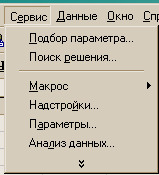
Для того, чтобы отыскать команду вызова надстройки Пакет анализа в Microsoft Excel, необходимо воспользоваться меню Сервис (рис. 1).
Здесь возможны следующие ситуации:
1. В меню Сервис присутствует команда Анализ данных… (рис. 1). Это самый простой и идеальный случай, так как достаточно щелкнуть указателем мыши, чтобы воспользоваться окном надстройки.
2. В меню Сервис отсутствует команда Анализ данных… В этом случае необходимо в том же меню выполнить команду Надстройки… В результате раскроется одноименное диалоговое окно со списком доступных надстроек (рис. 2). Среди доступных надстроек выберите элемент Пакет анализа. После этого в меню Сервис появится соответствующая команда. Эта ситуация наиболее типична, так как надстройка Пакет анализа инсталлируется при стандартной установке.
|
|
Рис. 1. Меню Сервис |
Рис. 2. Диалоговое окно Надстройки |
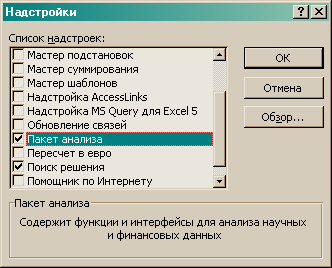
3. В меню Сервис отсутствует команда Анализ данных…, а в списке окна Надстройки нет элемента Пакет анализа. Это самая сложная ситуация, так как без установочного комплекта MS Office не обойтись. После установки дистрибутивного компакт-диска Microsoft Office, перейдите в папку Панель управления (главное меню Пуск) – Установка и удаление программ (рис. 3). Выберите кнопку Заменить, затем следуйте инструкциям Мастера установки, выбирая те пункты и опции, которые вам необходимы. При установки надстройки Пакет анализа установите и все другие надстройки Microsoft Excel. Они значительно расширят возможности программы, а при этом займут на винчестере совсем немного места. Вид диалогового окна Установка и удаление программ может отличаться в разных операционных системах.
Окончание прил. 1
Рис. 3. Диалоговое окно Установка и удаление программ
Если все сделано правильно и названия папок были оставлены по умолчанию, то в папке C:\ Program Files\ Microsoft Office\ Office\ Library\ Analysis появится файл надстройки analysis32.xll.
Приложение 2 Виды ошибок при задании формул
Формула представляет собой синтаксическую
конструкцию со знаком “=” в первой
позиции, набирается с клавиатуры или
кнопкой ![]() Изменить
формулу. По этому признаку Excel
запускает Палитру формул, которая
проверяет синтаксис, автоматически
исправляет распространенные ошибки и
обеспечивает справочными сведениями.
Изменить
формулу. По этому признаку Excel
запускает Палитру формул, которая
проверяет синтаксис, автоматически
исправляет распространенные ошибки и
обеспечивает справочными сведениями.
Формула может содержать следующие элементы:
Выражение – это операнды, соединенные знаками операций. Используемые в формулах Excel операции приведены в таблице 1. Порядок вычисления выражений слева направо с учетом приоритетов операций и может быть изменен скобками ( ).
Таблица 1
Операции в формулах Excel
Группа |
Операции |
Операции над ссылками |
: ссылка на диапазон ; объединение ссылок (операция пробел) пересечение диапазонов |
Арифметические операции (по приоритету) |
унарный – % ^ * и / + и - |
Операции сравнения |
>, <, =, >=, <=, <> |
Текстовая операция |
& объединение текста |
Операнд – это константа, ссылка на ячейку или диапазон ячеек, заголовок, имя или функция.
Константа – это число или текст, введенные с клавиатуры, в отличие от формулы или возвращаемого ею значения.
Ссылка на ячейку – это адрес ячейки, однозначно определяющий ее месторасположение, в Excel по умолчанию используется стиль адресации А1 по букве столбца и номеру строки, на пересечении которых расположена ячейка. При помощи ссылок можно использовать в одной формуле данные из разных частей листа, а также использовать в нескольких формулах значение одной ячейки.
При создании формул используются следующие типы ссылок.
Абсолютная ссылка – фиксированный адрес ячейки на листе, например, $А$3. Абсолютные адреса предваряются знаком $.
Относительная ссылка – относительно ячейки с формулой, содержащей эту ссылку, например, A3.
Продолжение прил. 2
Смешанная ссылка. Например, А$1 – абсолютная ссылка на первую строку, $A1 – абсолютная ссылка на первый столбец.
Ссылки на ячейки других листов той же книги, Лист2!А1.
Внешние ссылки на другие книги, [Книга2]Лист1!A1 на открытую книгу, иначе с полным путем к книге на локальном диске, ‘С:\Мои документы\[Книга2]Лист1’!$A$1.
Удаленные ссылки на данные других приложений; сетевые адреса и URL (Uniform Resource Locator, унифицированный указатель ресурса, адреса интернета).
Трехмерные ссылки на несколько листов, Лист2:Лист13!A1.
Циклические ссылки – это последовательность ссылок, при которой формула ссылается на себя напрямую или через другие ссылки. Вычисление следующих значений по предыдущим в таких замкнутых последовательностях называется итерацией. Excel прекращает итерационный процесс по заранее установленным ограничениям на количество итераций, по умолчанию 100, или на невязку (разность значений с двух соседних итераций), по умолчанию 0,001.
Ячейки, на которые есть ссылки в указанной ячейке, называются влияющими. Ячейки, в которых есть ссылки на указанную ячейку, называются зависимыми.
При перемещении ячейки, ее формула не изменяется. При этом во всех зависимых ячейках ссылки всех типов выправляются на новое местоположение перемещенной ячейки.
При копировании формулы абсолютные ссылки не обновляются. Относительные ссылки при копировании формулы в другую ячейку обновляются автоматически так, что взаимное расположение влияющих ячеек и формулы сохраняется. Например, формула в ячейке A3 =$A$1+A2 после копирования в ячейку В3 =$A$1+B2. Копирование формулы в примыкающий диапазон можно быстро осуществить протаскиванием маркера заполнения.
Диапазон – это несколько ячеек листа. Ссылка на непрерывный прямоугольный диапазон задается как адрес левой верхней ячейки : адрес правой нижней ячейки. В ссылке на несмежный диапазон поддиапазоны перечисляются через ; и выделяются на листе с нажатым Ctrl.
Формула может содержать одну или
несколько функций, связанных между
собой арифметическими операторами или
вложенных друг в друга. Функции – это
встроенные в программу Excel формулы,
которые выполняют вычисления по своим
аргументам. Обращение к функции идет
по имени функции и в скобках списку
аргументов через запятую. Вставку
функции можно выполнить, используя меню
Вставка –
![]() Функция… либо одноименную кнопку
на панели инструментов Стандартная. В
результате будет запущен двухшаговый
Мастер функций, содержащий всю коллекцию
функций Excel в более чем
10 различных категорий.
Функция… либо одноименную кнопку
на панели инструментов Стандартная. В
результате будет запущен двухшаговый
Мастер функций, содержащий всю коллекцию
функций Excel в более чем
10 различных категорий.
Продолжение прил. 2
Аргумент функции – это число, текст, логическая величина, массив, значение ошибки, ссылка, формула или функция. Тип аргумента должен соответствовать типу в описании функции.
Если при задании формулы были допущены ошибки, результатом ее вычисления будет так называемое значение ошибки.
Ошибка #####
Причины возникновения ошибки
Введенное числовое значение или результат работы функции не умещается в ячейке.
Меры
по устранению ошибки – увеличьте
ширину столбца путем перемещения
границы, расположенной между заголовками
столбцов. Кроме того, можно изменить
формат числа ячейки (меню Формат –
![]() Ячейки…, вкладка Число).
Ячейки…, вкладка Число).
При работе с датами получается отрицательное значение.
Меры по устранению ошибки – введите правильную формулу.
Ошибка #ЗНАЧ!
Причины возникновения ошибки
Вместо числового или логического значения введен текст.
Меры по устранению ошибки – проверьте в формуле правильность задания типов аргументов.
После ввода или редактирования формулы массива нажимается клавиша Enter.
Меры по устранению ошибки – для редактирования формулы укажите ячейку или диапазон ячеек, содержащих формулу массива, нажмите клавишу F2, а затем – комбинацию клавиш Ctrl+Shift+Enter.
Использована неправильная размерность матрицы данных в одной из матричных функций.
Меры по устранению ошибки – укажите правильную размерность при работе с матрицами данных.
Ошибка #ДЕЛ/0!
Причины возникновения ошибки
В качестве делителя используется ссылка на ячейку, содержащую нулевое или пустое значение (если аргумент является пустой ячейкой, то ее содержимое интерпретируется как нуль). Такая ситуация чаще всего возникает случайно.
Меры по устранению ошибки – измените ссылку или введите ненулевое значение в ячейку, используемую в качестве делителя.
Продолжение прил. 2
Ошибка #ИМЯ?
Причины возникновения ошибки
Используемое в формуле имя было удалено или не определено.
Меры по устранению ошибки – определите имя. Для этого выполните команду Имя меню Вставка
Имеется ошибка в написании имени функции.
Меры по устранению ошибки – исправьте написание имени функции вручную или вставьте функцию с помощью мастера функций.
В формулу введен текст, не заключенный в двойные кавычки. Excel пытается распознать такой текст как имя, хотя это не предполагается.
Меры по устранению ошибки – заключите текст формулы в двойные кавычки. Например, ессли в ячейке А1 содержится значение 200, я в ячейке В1 – формула = «Итого:»&А1, то в ячейке В1 будет выведен результат Итого:200.
В ссылке на диапазон ячеек пропущен знак двоеточия (:).
Меры по устранению ошибки – исправьте формулу так, чтобы во всех ссылках на диапазон ячеек использовался знак двоеточия, например =СУММА(А1:С10).
Ошибка #Н/Д
Причины возникновения ошибки
В формуле массива используется аргумент, не соответствующий размеру диапазона, определяющегося числом строк и столбцов.
Меры по устранению ошибки – если формула массива введена в несколько ячеек, проверьте диапазон ссылок формулы на соответствие числу строк и столбцов или введите формулу массива в недостающие ячейки.
Не заданы один или несколько аргументов стандартной или пользовательской функции листа.
Меры по устранению ошибки – задайте все необходимые аргументы функции.
Используется пользовательская функция, обращение к которой приводит к ошибке.
Меры по устранению ошибки – проверьте, что книга, использующая функцию листа, открыта, и убедитесь в правильности работы функции (проведите отладку в программной среде VBA).
Ошибка #ССЫЛКА!
Причины возникновения ошибки
Ячейки, на которые ссылаются формулы, были удалены или в эти ячейки было помещено содержимое других скопированных ячеек.
Окончание прил. 2
Меры по устранению ошибки – измените формулы или сразу же после удаления или вставки скопированного восстановите прежнее содержимое ячеек с помощью кнопки Отменить.
Ошибка #ЧИСЛО!
Причины возникновения ошибки
В функции с числовым аргументом используется неприемлемый аргумент.
Меры по устранению ошибки – проверьте правильность использования в функции аргументов.
Задана функция, при вычислении которой используется итерационны процесс. При этом итерационный процесс не сходится и результат не может быть получен.
Меры по устранению ошибки – используйте другое начальное приближение для этой функции.
Введена формула, рассчитывающая числовое значение, которое слишком велико или слишком мало, чтобы его можно было представить в Microsoft Excel.
Меры по устранению ошибки – измените формулу так, чтобы в результате ее вычисления получалось число, попадающее в диапазон от -110307 до 110307.
Ошибка #ПУСТО!
Причины возникновения ошибки
Использован оператор, задающий пересечение диапазонов, не имеющих общих ячеек.
Меры по устранению ошибки – задайте правильно размерность пересекающихся диапазонов или не используйте оператор пересечения, если диапазоны не являются таковыми. В Microsoft Excel оператором пересечения диапазонов является пробел ( ).
Приложение 3 Кратка теория диаграмм
Диаграммы являются средством визуального анализа данных. В любой современной системе программирования есть подобные графические чарты (chart – диаграмма). В табл. 1 приведены основные параметры диаграмм Excel 2000/XP.
Таблица 1
Технические характеристики Excel-диаграмм
Параметры диаграмм |
Технические возможности Excel |
Количество диаграмм, использующих данные листа |
Ограничивается объемом доступной оперативной памяти |
Количество листов, используемых диаграммой |
до 255 |
Рядов данных в диаграмме |
до 255 |
Точек данных в одном ряду данных |
до 32000 для плоских диаграмм до 4000 для объемных диаграмм |
Точек данных во всех рядах данных одной диаграммы |
до 256000 |
Excel предоставляет пользователю 14 стандартных типов диаграмм: гистограмма, линейчатая, график, круговая, точечная, с областями, кольцевая, лепестковая, поверхность, пузырьковая, биржевая и другие. Каждый стандартный тип имеет несколько разновидностей. Постоянно наращивается палитра встроенных нестандартных типов. Коллекция типов диаграмм доступна из меню Диаграмма – Тип диаграммы. Инженерные приложения используют следующие типы диаграмм:
- график
отображает значения однозначной функции
y(х)
с равными промежутками
по аргументу x.
график
отображает значения однозначной функции
y(х)
с равными промежутками
по аргументу x.
- точечный график строит график функции по точкам (x,y) без ограничений на вид функции.
- сглаженные линии на Графике и Точечной диаграмме соединяют точки плавной кривой.
- поверхность – это график трехмерной поверхности z(x,y).
- контурная поверхность, проекция трехмерной поверхности на координатную плоскость XY в виде карты изолиний z(x,y) = Const.
Организация данных в диаграммах описывается следующей терминологией.
Диаграмма – графический объект на листе Excel. Активная диаграмма запускает в верхнем меню пункт Диаграмма, а также меню Вид и Формат настраиваются для работы с конкретной диаграммой.
Продолжение прил. 3
Элементы диаграммы – отдельные объекты, составляющие диаграмму, довольно разнородные и отличаются для разных типов диаграмм. Элементы активной диаграммы собраны в список на панели инструментов Диаграммы. Все элементы диаграмм оснащены всплывающими подсказками.
Область диаграммы – прямоугольная область, охватывающая все элементы диаграммы. Область построения на плоских диаграммах – это ограниченный координатными осями прямоугольник, содержащий ряды данных. На объемных диаграммах – охватывает три координатные оси со всеми подписями.
Заголовок диаграммы – надпись с описательным текстом. По умолчанию располагается по центру над областью построения.
Ряд данных – группа связанных данных диаграммы. Например, ряд данных для графика составляет диапазон значений функции. На одной диаграмме можно изобразить несколько рядов данных, каждый своим цветом. В качестве имен рядов данных Excel использует заголовки столбцов (или строк) диапазона данных. Если автоматическое распознавание имен рядов прошло безуспешно, Excel сгенерирует имена рядов по умолчанию: Ряд1, Ряд2, Ряд3,.. Имена рядов выводятся в легенду. Точка данных обозначается на диаграмме маркером – это точка, маркер, столбик, сегмент или другой графический примитив, например, на гистограмме это цветной столбик, на графике – квадратик в 5 пунктов.
Легенда. Подпись с условными обозначениями цвета/закраски рядов данных. Легенда обычно располагается справа от области построения. Ключ легенды – условное обозначение в легенде слева от имени ряда, назначенное этому ряду.
Категории – это значения независимой переменной, от которой зависят значения рядов данных, обычно откладываются на горизонтальной оси. Например, на графике значения категорий – это значения аргумента функции. Имена категорий используются для подписей делений оси категорий. Excel пытается распознать заголовки строк (или столбцов) данных для использования их в качестве имен категорий по отличающемуся форматированию первого столбца, иначе автоматически нумерует категории 1, 2, 3,.. В противном необходимо вручную указать адреса ячеек с именами категорий.
Оси – это линии, используемые как основа измерений для построения данных на диаграмме. Ось категорий обычно отображается по горизонтальной оси, например, на графике соответствует оси X, оси независимой переменной. Ось значений – это обычно вертикальная ось, ось Y. Например, на графике значение точки данных изображает расстояние от маркера точки по вертикали до оси категорий в выбранных единицах измерения. Деления и подписи делений осей – это короткие насечки на оси через одинаковые расстояния, их подписи показывают откладываемую по оси меру, а также могут обозначать категории или ряды. Линии сетки – параллельные осям линии, облегчающие просмотр данных на диаграмме.
Окончание прил. 3
Подписи значений отображают дополнительные сведения: значения в отдельных точках, названия категорий, рядов или их комбинации.
К элементам диаграмм также относятся заголовки осей, линии проекции, вспомогательные оси, линии рядов, тренды, коридоры колебания, полосы повышения и понижения, планки погрешности и другие.
В табл. 2 приведены способы создания диаграммы в Excel. Рекомендуется использовать последний способ. Четырехшаговый мастер диаграмм выпытает у вас все параметры диаграммы и создаст с первого раза близкий к желаемому результат.
Таблица 2
Способы создания диаграммы
Лого |
Название и где брать |
|
Команда Создать диаграмму текущего типа за один клик. Microsoft предлагает гистограмму |
|
F11 – создание листа диаграммы установленного типа за один клик. Настраивается диаграмма вручную |
|
С панели Диаграммы – Тип диаграммы |
|
Меню Вставка – Диаграмма… запускает мастера диаграмм |
|
Команда Мастер диаграмм на Стандартной панели инструментов |
Размещенная на отдельном листе книги или внедренная в текущий лист диаграмма связана с данными, на основе которых она создана, и обновляется автоматически при их изменении.
Приложение 4 Статистические таблицы
Приведены краткие выдержки из таблиц математической статистики, необходимые и достаточные для выполнения упражнений, приведенных в сборнике. Более точные таблицы см. в [9].
Таблица 1
Интегральная функция нормированного нормального распределения
![]() ;
;
![]() ;
;
![]()
В первом столбце и в верхней строке указаны значения аргумента.
Z |
0,00 |
0,01 |
0,02 |
0,03 |
0,04 |
0,05 |
0,06 |
0,07 |
0,08 |
0,09 |
0,0 |
0,5000 |
,5040 |
,5080 |
,5120 |
,5160 |
,5199 |
,5239 |
,5279 |
,5319 |
,5359 |
0,1 |
0,5398 |
,5438 |
,5478 |
,5517 |
,5557 |
,5596 |
,5636 |
,5675 |
,5714 |
,5753 |
0,2 |
0,5793 |
,5832 |
,5871 |
,5910 |
,5948 |
,5987 |
,6026 |
,6064 |
,6103 |
,6141 |
0,3 |
0,6179 |
,6217 |
,6255 |
,6293 |
,6331 |
,6368 |
,6406 |
,6443 |
,6480 |
,6517 |
0,4 |
0,6554 |
,6591 |
,6628 |
,6664 |
,6700 |
,6736 |
,6772 |
,6808 |
,6844 |
,6879 |
0,5 |
0,6915 |
,6950 |
,6985 |
,7019 |
,7054 |
,7088 |
,7123 |
,7157 |
,7190 |
,7224 |
0,6 |
0,7257 |
,7291 |
,7324 |
,7357 |
,7389 |
,7422 |
,7454 |
,7486 |
,7517 |
,7549 |
0,7 |
0,7580 |
,7611 |
,7642 |
,7673 |
,7704 |
,7734 |
,7764 |
,7794 |
,7823 |
,7852 |
0,8 |
0,7881 |
,7910 |
,7939 |
,7967 |
,7995 |
,8023 |
,8051 |
,8078 |
,8106 |
,8133 |
0,9 |
0,8159 |
,8186 |
,8212 |
,8238 |
,8264 |
,8289 |
,8315 |
,8340 |
,8365 |
,8389 |
1,0 |
,8413 |
,8438 |
,8461 |
,8485 |
,8508 |
,8531 |
,8554 |
,8577 |
,8599 |
,8621 |
1,1 |
0,8643 |
,8665 |
,8686 |
,8708 |
,8729 |
,8749 |
,8770 |
,8790 |
,8810 |
,8830 |
1,2 |
0,8849 |
,8869 |
,8888 |
,8907 |
,8925 |
,8944 |
,8962 |
,8980 |
,8997 |
,9015 |
1,3 |
0,9032 |
,9049 |
,9066 |
,9082 |
,9099 |
,9115 |
,9161 |
,9147 |
,9162 |
,9177 |
1,4 |
0,9192 |
,9207 |
,9222 |
,9236 |
,9251 |
,9265 |
,9279 |
,9292 |
,9306 |
,9319 |
1,5 |
0,9332 |
,9345 |
,9357 |
,9370 |
,9382 |
,9394 |
,9406 |
,9418 |
,9429 |
,9441 |
1,6 |
0,9452 |
,9463 |
,9474 |
,9484 |
,9495 |
,9505 |
,9515 |
,9525 |
,9535 |
,9545 |
1,7 |
0,9554 |
,9564 |
,9573 |
,9582 |
,9591 |
,9599 |
,9608 |
,9616 |
,9625 |
,9633 |
1,8 |
0,9641 |
,9649 |
,9656 |
,9664 |
,9671 |
,9678 |
,9686 |
,9693 |
,9699 |
,9706 |
1,9 |
0,9713 |
,9719 |
,9726 |
,9732 |
,9738 |
,9744 |
,9750 |
,9756 |
,9761 |
,9767 |
2,0 |
0,9772 |
,9778 |
,9783 |
,9788 |
,9793 |
,9798 |
,9803 |
,9808 |
,9812 |
,9817 |
2,1 |
0,9821 |
,9826 |
,9830 |
,9834 |
,9838 |
,9842 |
,9846 |
,9850 |
,9854 |
,9857 |
2,2 |
0,9861 |
,9864 |
,9868 |
,9871 |
,9875 |
,9878 |
,9881 |
,9884 |
,9887 |
,9890 |
2,3 |
0,9893 |
,9896 |
,9898 |
,9901 |
,9904 |
,9906 |
,9909 |
,9911 |
,9913 |
,9916 |
2,4 |
0,9918 |
,9920 |
,9922 |
,9925 |
,9927 |
,9929 |
,9931 |
,9932 |
,9934 |
,9936 |
2,5 |
0,9938 |
,9940 |
,9941 |
,9943 |
,9945 |
,9946 |
,9948 |
,9949 |
,9951 |
,9952 |
2,6 |
0,9953 |
,9955 |
,9956 |
,9957 |
,9959 |
,9960 |
,9961 |
,9962 |
,9963 |
,9964 |
2,7 |
0,9965 |
,9966 |
,9967 |
,9968 |
,9969 |
,9970 |
,9971 |
,9972 |
,9973 |
,9974 |
2,8 |
0,9974 |
,9975 |
,9976 |
,9977 |
,9977 |
,9978 |
,9979 |
,9980 |
,9980 |
,9981 |
2,9 |
0,9981 |
,9982 |
,9983 |
,9983 |
,9984 |
,9984 |
,9985 |
,9985 |
,9986 |
,9986 |
3,0 |
0,9987 |
,9987 |
,9987 |
,9988 |
,9988 |
,9989 |
,9989 |
,9989 |
,9990 |
,9990 |
Продолжение прил. 4
Таблица 2
Дифференциальная функция нормированного нормального распределения (плотность вероятности)
![]() ;
;
![]() ;
;
![]()
Z |
0,00 |
0,01 |
0,02 |
0,03 |
0,04 |
0,05 |
0,06 |
0,07 |
0,08 |
0,09 |
0,0 |
0,3989 |
,3989 |
,3989 |
,3987 |
,3986 |
,3984 |
,3982 |
,3980 |
,3977 |
,3973 |
0,1 |
0,3970 |
,3965 |
,3961 |
,3956 |
,3951 |
,3945 |
,3939 |
,3932 |
,3925 |
,3918 |
0,2 |
0,3910 |
,3902 |
,3894 |
,3885 |
,3876 |
,3867 |
,3857 |
,3847 |
,3836 |
,3825 |
0,3 |
0,3814 |
,3802 |
,3790 |
,3778 |
,3765 |
,3752 |
,3739 |
,3726 |
,3712 |
,3697 |
0,4 |
0,3683 |
,3662 |
,3653 |
,3637 |
,3621 |
,3605 |
,3589 |
,3572 |
,3555 |
,3538 |
0,5 |
0,3521 |
,3503 |
,3485 |
,3467 |
,3448 |
,3429 |
,3410 |
,3391 |
,3372 |
,3352 |
0,6 |
0,3332 |
,3312 |
,3292 |
,3271 |
,3251 |
,3230 |
,3209 |
,3187 |
,3166 |
,3144 |
0,7 |
0,3123 |
,3101 |
,3079 |
,3056 |
,3034 |
,3011 |
,2989 |
,2966 |
,2943 |
,2920 |
0,8 |
0,2897 |
,2874 |
,2850 |
,2827 |
,2803 |
,2780 |
,2756 |
,2732 |
,2709 |
,2685 |
0,9 |
0,2661 |
,2637 |
,2613 |
,2589 |
,2565 |
,2541 |
,2516 |
,2492 |
,2468 |
,2444 |
1,0 |
0,2420 |
,2396 |
,2371 |
,2347 |
,2323 |
,2299 |
,2275 |
,2251 |
,2227 |
,2203 |
1,1 |
0,2179 |
,2155 |
,2131 |
,2107 |
,2083 |
,2059 |
,2036 |
,2012 |
,1989 |
,1965 |
1,2 |
0,1942 |
,1919 |
,1895 |
,1872 |
,1849 |
,1826 |
,1804 |
,1781 |
,1758 |
,1736 |
1,3 |
0,1714 |
,1691 |
,1669 |
,1647 |
,1626 |
,1604 |
,1582 |
,1561 |
,1539 |
,1518 |
1,4 |
0,1497 |
,1476 |
,1456 |
,1435 |
,1415 |
,1394 |
,1374 |
,1354 |
,1334 |
,1315 |
1,5 |
0,1295 |
,1276 |
,1257 |
,1238 |
,1219 |
,1200 |
,1182 |
,1163 |
,1145 |
,1127 |
1,6 |
0,1109 |
,1092 |
,1074 |
,1057 |
,1040 |
,1023 |
,1006 |
,0989 |
,0973 |
,0957 |
1,7 |
0,0940 |
,0925 |
,0909 |
,0893 |
,0878 |
,0863 |
,0848 |
,0833 |
,0818 |
,0804 |
1,8 |
0,0790 |
,0775 |
,0761 |
,0748 |
,0734 |
,0721 |
,0707 |
,0694 |
,0681 |
,0669 |
1,9 |
0,0656 |
,0644 |
,0632 |
,0620 |
,0608 |
,0596 |
,0584 |
,0573 |
,0562 |
,0551 |
2,0 |
0,0540 |
,0529 |
,0519 |
,0508 |
,0498 |
,0488 |
,0478 |
,0468 |
,0459 |
,0449 |
2,1 |
0,0440 |
,0431 |
,0422 |
,0413 |
,0404 |
,0396 |
,0387 |
,0379 |
,0371 |
,0363 |
2,2 |
0,0355 |
,0347 |
,0339 |
,0332 |
,0325 |
,0317 |
,0310 |
,0303 |
,0297 |
,0290 |
2,3 |
0,0283 |
,0277 |
,0270 |
,0264 |
,0258 |
,0252 |
,0246 |
,0241 |
,0235 |
,0229 |
2,4 |
0,0224 |
,0219 |
,0213 |
,0208 |
,0203 |
,0198 |
,0194 |
,0189 |
,0184 |
,0180 |
2,5 |
0,0175 |
,0171 |
,0167 |
,0163 |
,0158 |
,0154 |
,0151 |
,0147 |
,0143 |
,0139 |
2,6 |
0,0136 |
,0132 |
,0129 |
,0126 |
,0122 |
,0119 |
,0116 |
,0113 |
,0110 |
,0107 |
2,7 |
0,0104 |
,0101 |
,0099 |
,0096 |
,0093 |
,0091 |
,0088 |
,0086 |
,0084 |
,0081 |
2,8 |
0,0079 |
,0077 |
,0075 |
,0073 |
,0071 |
,0069 |
,0067 |
,0065 |
,0063 |
,0061 |
2,9 |
0,0060 |
,0058 |
,0056 |
,0055 |
,0053 |
,0051 |
,0050 |
,0048 |
,0047 |
,0046 |
3,0 |
0,0044 |
,0043 |
,0042 |
,0040 |
,0039 |
,0038 |
,0037 |
,0036 |
,0035 |
,0034 |
Продолжение прил. 4
Таблица 3
Коэффициенты Стьюдента (двухсторонние границы t-распределения)
Число степеней
свободы
|
Значения t
при
вероятности
|
|
0,9 |
0,95 |
|
1 |
6,31 |
12,71 |
2 |
2,92 |
4,30 |
3 |
2,35 |
3,18 |
4 |
2,13 |
2,78 |
5 |
2,02 |
2,57 |
6 |
1,94 |
2,45 |
7 |
1,90 |
2,37 |
8 |
1,86 |
2,31 |
9 |
1,83 |
2,26 |
10 |
1,81 |
2,23 |
12 |
1,78 |
2,18 |
15 |
1,75 |
2,13 |
17 |
1,74 |
2,11 |
18 |
1,73 |
2,10 |
19 |
1,73 |
2,09 |
20 |
1,72 |
2,09 |
25 |
1,71 |
2,06 |
30 |
1,70 |
2,04 |
40 |
1,68 |
2,02 |
|
1,64485 |
1,95996 |
Двухсторонний уровень значимости |
0,10 |
0,05 |
Таблица 4
Критические значения для наибольшего отклонения эмпирической функции распределения от теоретической (критерий Колмогорова).
Значения
![]() ,
удовлетворяющие условию
,
удовлетворяющие условию
![]()
Уровень
значимости
|
Объем выборки
|
||||||||
4 |
6 |
8 |
10 |
15 |
20 |
25 |
30 |
40 |
|
0,05 |
0,62 |
0,52 |
0,45 |
0,41 |
0,34 |
0,29 |
0,26 |
0,24 |
0,21 |
0,10 |
0,57 |
0,47 |
0,41 |
0,37 |
0,30 |
0,26 |
0,24 |
0,22 |
0,19 |
Для
![]() используют аппроксимации:
используют аппроксимации:
![]()
![]() .
.
Продолжение прил. 4
Таблица 5
Распределение
(процентные точки).
Значения
![]() ,
удовлетворяющие условию
,
удовлетворяющие условию
![]() или эквивалентному условию
или эквивалентному условию
![]()
Число
степеней свободы
|
Вероятность |
|||||||
0,025 (2,5 %) |
0,05 |
0,40 |
0,50 |
0,60 |
0,90 |
0,95 |
0,975 |
|
1 |
0,001 |
0,004 |
0,275 |
0,455 |
0,708 |
2,706 |
3,841 |
5,024 |
2 |
0,051 |
0,103 |
1,022 |
1,386 |
1,833 |
4,605 |
5,991 |
7,378 |
3 |
0,216 |
0,352 |
1,869 |
2,366 |
2,946 |
6,251 |
7,815 |
9,348 |
4 |
0,484 |
0,711 |
2,753 |
3,357 |
4,045 |
7,779 |
9,488 |
11,143 |
5 |
0,831 |
1,145 |
3,655 |
4,351 |
5,132 |
9,236 |
11,070 |
12,832 |
6 |
1,237 |
1,635 |
4,570 |
5,348 |
6,211 |
10,645 |
12,592 |
14,449 |
7 |
1,690 |
2,167 |
5,493 |
6,346 |
7,283 |
12,017 |
14,067 |
16,013 |
8 |
2,180 |
2,733 |
6,423 |
7,344 |
7,351 |
13,362 |
15,507 |
17,535 |
9 |
2,700 |
3,325 |
7,357 |
8,343 |
9,414 |
14,684 |
16,919 |
19,023 |
10 |
3,247 |
3,940 |
8,295 |
9,342 |
10,473 |
15,987 |
18,307 |
20,483 |
12 |
4,404 |
5,226 |
10,182 |
11,340 |
12,584 |
18,549 |
21,026 |
23,336 |
14 |
5,629 |
6,571 |
12,079 |
13,339 |
14,685 |
21,064 |
23,685 |
26,119 |
16 |
6,908 |
7,962 |
13,983 |
15,338 |
16,780 |
23,542 |
26,296 |
28,845 |
18 |
8,231 |
9,390 |
15,893 |
17,338 |
18,868 |
25,989 |
28,861 |
31,526 |
20 |
9,591 |
10,851 |
17,809 |
19,337 |
20,951 |
28,412 |
31,410 |
34,170 |
25 |
13,120 |
14,611 |
22,616 |
24,337 |
26,143 |
34,382 |
37,652 |
40,646 |
30 |
16,791 |
18,493 |
27,442 |
29,336 |
31,316 |
40,256 |
43,773 |
46,979 |
40 |
24,433 |
26,509 |
37,134 |
37,335 |
41,622 |
51,803 |
55,758 |
59,345 |
|
0,975 |
0,95 |
0,60 |
0,50 |
0,40 |
0,10 |
0,05 |
0,025 |
Для построения двухстороннего интервала
вероятности для случайной величины,
имеющей
![]() ‑распределение,
удовлетворяющего условию
‑распределение,
удовлетворяющего условию
![]() ,
следует учесть, что
,
следует учесть, что
![]()
Верхнюю границу такого интервала находят
по таблице для
![]() ,
а нижнюю – для
,
а нижнюю – для
![]() .
.
Продолжение прил. 4
Таблица 6
Значения
![]() для
для
![]() = 0.05 (верхние 5‑процентные
критические
значения, односторонний критерий)
= 0.05 (верхние 5‑процентные
критические
значения, односторонний критерий)
Число степеней
свободы знаменателя
|
Число степеней
свободы числителя
|
|||||||||
1 |
5 |
8 |
10 |
15 |
20 |
30 |
40 |
60 |
120 |
|
5 |
6,61 |
5,05 |
4,82 |
4,74 |
4,62 |
4,56 |
4,50 |
4,46 |
4,43 |
4,40 |
6 |
5,99 |
4,39 |
4,15 |
4,06 |
3,94 |
3,87 |
3,81 |
3,77 |
3,74 |
3,70 |
8 |
5,59 |
3,69 |
3,44 |
3,35 |
3,22 |
3,15 |
3,08 |
3,04 |
3,01 |
2,97 |
10 |
4,96 |
3,33 |
3,07 |
2,98 |
2,85 |
2,77 |
2,70 |
2,66 |
2,62 |
2,58 |
15 |
4,54 |
2,9 |
2,64 |
2,54 |
2,40 |
2,33 |
2,25 |
2,20 |
2,16 |
2,11 |
20 |
4,35 |
2,71 |
2,45 |
2,35 |
2,20 |
2,12 |
2,04 |
1,99 |
1,95 |
1,90 |
30 |
4,17 |
2,53 |
2,27 |
2,16 |
2,01 |
1,93 |
1,84 |
1,79 |
1,74 |
1,68 |
40 |
4,08 |
2,45 |
2,18 |
2,08 |
1,92 |
1,84 |
1,74 |
1,69 |
1,64 |
1,58 |
60 |
4,00 |
2,37 |
2,10 |
1,99 |
1,84 |
1,75 |
1,65 |
1,59 |
1,53 |
1,47 |
120 |
3,92 |
2,29 |
2,02 |
1,91 |
1,75 |
1,66 |
1,55 |
1,50 |
1,43 |
1,35 |
|
3,84 |
2,21 |
1,94 |
1,83 |
1,67 |
1,57 |
1,46 |
1,39 |
1,32 |
1,22 |
Значения
![]() для
= 0.10 (верхние 10‑процентные
критические
значения, односторонний критерий)
для
= 0.10 (верхние 10‑процентные
критические
значения, односторонний критерий)
Число степеней свободы знаменат. |
Число степеней
свободы числителя
|
|||||||||
1 |
5 |
8 |
10 |
15 |
20 |
30 |
40 |
60 |
120 |
|
5 |
4,06 |
3,45 |
3,34 |
3,30 |
3,24 |
3,21 |
3,17 |
3,16 |
3,14 |
3,12 |
6 |
3,78 |
3,11 |
2,98 |
2,94 |
2,87 |
2,84 |
2,80 |
2,78 |
2,76 |
2,74 |
8 |
3,46 |
2,73 |
2,67 |
2,54 |
2,46 |
2,42 |
2,38 |
2,36 |
2,34 |
2,32 |
10 |
3,28 |
2,52 |
2,38 |
2,32 |
2,24 |
2.20 |
2.16 |
2.13 |
2.11 |
2.08 |
15 |
3.07 |
2.27 |
2.12 |
2.06 |
2.02 |
1.92 |
1.87 |
1/85 |
1/82 |
1/79 |
20 |
2.97 |
2.16 |
2.00 |
1/94 |
1.84 |
1.79 |
1.74 |
1.71 |
1.68 |
1.64 |
30 |
2.88 |
2.05 |
1.88 |
1.82 |
1.72 |
1.67 |
1.61 |
1.57 |
1.54 |
1.50 |
40 |
2.84 |
2.00 |
1.83 |
1.76 |
1.66 |
1.61 |
1.54 |
1.51 |
1.47 |
1.43 |
60 |
2.79 |
1.95 |
1.77 |
1.71 |
1,60 |
1,54 |
1,48 |
1,44 |
1,40 |
1,35 |
120 |
2.75 |
1.90 |
1.72 |
1.65 |
1,54 |
1,48 |
1,41 |
1,37 |
1,32 |
1,26 |
|
2.71 |
1.85 |
1.67 |
1.60 |
1,49 |
1,42 |
1,34 |
1,30 |
1,24 |
1,17 |
Окончание прил. 4
Полезные соотношения:
![]() ;
;
![]() ,
,
где
![]() –
–
![]() -процентная
точка t-распределения, соответствующая
вероятности
-процентная
точка t-распределения, соответствующая
вероятности
![]() или коэффициент Стьюдента (двухсторонняя
граница t-распределения, табл. 3).
или коэффициент Стьюдента (двухсторонняя
граница t-распределения, табл. 3).
Список литературы
Макарова Н.В. Статистика в Excel: Учебное пособие/ Макарова Н.В., Трофимец В.Я. – М.: Финансы и статистика, 2002. – 368 с.
Селиванов М. Н. Качество измерений / Селиванов М.Н., Фридман А.Э., Кудряшева Т.Ф. – Л.: Лениздат, 1987.
Новицкий П. В. Оценка погрешностей результатов измерений / Новицкий П.В., Зограф И.А. – Л.: Энергоатомиздат, 1985.
Гмурман В.Е. Теория вероятностей и математическая статистика/ Гмурман В.Е. – М.: Высшая школа, 1997.
Чашкин Ю.Р. Статистика для инженеров. Основы регрессионного анализа/ Чашкин Ю.Р. – Хабаровск: Изд-во ДВГУПС, 2003. – 162 с.
Худсон Д. Статистика для физиков / Худсон Д. – М.: Мир, 1970.
Гмурман В.Е. Руководство к решению задач по теории вероятностей и математической статистике: Учеб. Пособие для студентов вузов. Изд. 5-е, стер/ Гмурман В.Е. – М.: Высш. шк., 1999.
Чашкин Ю.Р. Математическая статистика. Статистическая обработка результатов измерений. Уч.-метод. пособие для самостоят. работ студентов / Чашкин Ю.Р. – Хабаровск: Изд-во ДВГУПС, 1999.
Большев Л.Н. Таблицы математической статистики / Большев Л.Н., Смирнов Н.В. – М.: Наука, 1983.
Тюрин Ю.Н. Статистический анализ данных на компьютере / Тюрин Ю.Н., Макаров А.А. Под ред. В.Э.Фигурнова – М.: ИНФРА-М, 1998.
Справочник по прикладной статистике. – В 2-ч т. – Т.1: Пер. с англ. / Под ред. Э. Ллойда, У.Ледермана, Ю.Н.Тюрина. – М.: Финансы и статистика, 1989. –370с.
Себер Дж. Линейный регрессионный анализ / Себер Дж. – М.: Мир, 1980.
Вучков И. Прикладной линейный регрессионный анализ / Вучков И., Бояджиева Л., Солаков Е. –М.: Финансы и статистика, 1987.
Дрейдер Н. Прикладной регрессионный анализ. В 2-х кн. Пер. с англ. – 2-е изд., перераб.и доп. / Дрейдер Н., Смит Г. – М.: Финансы и статистика, 1987.
Вихтенко Э. М. Численные методы на ЭВМ/ Вихтенко Э.М., Коломийцева С.В., Комова О.С. – Хабаровск: ДВГУПС, 2003. –71с.
Оглавление
ВВЕДЕНИЕ 3
ЛАБОРАТОРНАЯ РАБОТА № 1 ПЕРВИЧНАЯ ОБРАБОТКА РЕЗУЛЬТАТОВ ПРЯМЫХ МНОГОКРАТНЫХ ИЗМЕРЕНИЙ /вычисление основных статистических параметров/ 4
1. Цель работы 4
2. Задание 4
3. Краткая теория 4
4. Ход работы 7
5. Контрольные вопросы 12
ЛАБОРАТОРНАЯ РАБОТА № 2 ПОСТРОЕНИЕ ГИСТОГРАММЫ ПО РЕЗУЛЬТАТАМ ПРЯМЫХ МНОГОКРАТНЫХ ИЗМЕРЕНИЙ /на примере результатов математического эксперимента/ 13
1. Цель работы 13
2. Задание 13
3. Краткая теория 13
4. Ход работы 16
5. Контрольные вопросы 20
ЛАБОРАТОРНАЯ РАБОТА № 3 ПРОВЕРКА НОРМАЛЬНОСТИ ЗАКОНА РАСПРЕДЕЛЕНИЯ /тремя различными методами/ 20
1. Цель работы 20
2. Задание 20
3. Краткая теория 20
4. Ход работы 24
5. Контрольные вопросы 28
ЛАБОРАТОРНАЯ РАБОТА № 4 ОБЪЕДИНЕНИЕ РАВНОТОЧНЫХ СЕРИЙ ИЗМЕРЕНИЙ /двухвыборочный t-тест для средних/ 28
1. Цель работы 28
2. Задание 28
3. Краткая теория 28
4. Ход работы 30
5. Контрольные вопросы 36
ЛАБОРАТОРНАЯ РАБОТА № 5 ОБЪЕДИНЕНИЕ СЕРИЙ НЕРАВНОТОЧНЫХ ИЗМЕРЕНИЙ /двухвыборочный t-тест для средних/ 37
1. Цель работы 37
2. Задание 37
3. Краткая теория 37
4. Ход работы 39
5. Контрольные вопросы 42
ЛАБОРАТОРНАЯ РАБОТА № 6 ПОСТРОЕНИЕ ЛИНЕЙНОЙ ЭМПИРИЧЕСКОЙ ЗАВИСИМОСТИ ПО ОПЫТНЫМ ДАННЫМ /метод наименьших квадратов/ 42
1. Цель работы 42
2. Задание 42
3. Краткая теория 42
4. Ход работы 46
5. Контрольные вопросы 49
ЛАБОРАТОРНАЯ РАБОТА № 7 ОЦЕНКА СВЯЗИ НОМИНАЛЬНЫХ ПРИЗНАКОВ /таблицы сопряженности/ 49
1. Цель работы 49
2. Задание 49
3. Краткая теория 50
4. Ход работы 52
5. Контрольные вопросы 53
ЗАКЛЮЧЕНИЕ 53
ПРИЛОЖЕНИЕ 1 54
Установка надстройки "Пакет анализа" 54
ПРИЛОЖЕНИЕ 2 56
Виды ошибок при задании формул 56
ПРИЛОЖЕНИЕ 3 61
Кратка теория диаграмм 61
ПРИЛОЖЕНИЕ 4 64
Статистические таблицы 64
СПИСОК ЛИТЕРАТУРЫ 70
Учебное издание
Коломийцева Светлана Валерьевна
Чашкин Юрий Романович
Статистическая обработка данных на эвм
Сборник лабораторных работ
Технический редактор Н.В. Мильштейн
—————–––––––––————————————————————————
План 2004 г. Поз. 3.25.
ИД № 05247 от 2.07.2001 г. ПЛД № 79-19 от 19.01.2000 г.
Сдано в набор 31.03.2004 г. Подписано в печать 03.02.2005 г. Формат 60841/16. Бумага тип. № 2. Гарнитура Arial. Печать плоская.
Усл. печ. л. 4,4. Зак. 15. Тираж 100 экз. Цена 79 р.
————––––––––—————————————————————————
Издательство ДВГУПС
680021, Г. Хабаровск, ул. Серышева, 47.
Министерство транспорта Российской Федерации
Федеральное агентство железнодорожного транспорта
ГОУ ВПО «Дальневосточный государственный университет путей сообщения»
Кафедра «Прикладная математика»
С.В. Коломийцева Ю.Р. Чашкин
Статистическая обработка данных на эвм
Сборник лабораторных работ
Хабаровск
Издательство ДВГУПС
2005
1 Несмотря на широкое распространение, нормальное распределение не универсально. Если нет уверенности в его применимости, следует проверить возможность использования нормального распределения для описания случайной величины с помощью критериев согласия (см. лаб. работу «Проверка нормальности закона распределения»).
1 Это определение является строгим лишь для распределений экспоненциального типа, например, нормального. В этом случае существует так называемая «граница Крамера-Рао» как минимально возможная дисперсия оценки. Оценка, дисперсия которой достигает этой границы, называется эффективной.
Для распределений с плотностью вероятности, имеющей точки разрыва 1-го или 2-го рода (равномерного, арксинусного, двойного экспоненциального и др.) могут быть построены сверхэффективные оценки (их дисперсия существенно меньше дисперсии среднего арифметического).
1 Одинаковые значения в вариационном ряде должны повторяться столько раз, сколько они встречаются в выборке.
2 Функция ОКРУГЛВВЕРХ округляет число по модулю до ближайшего большего целого. Вторым аргументом является количество цифр, до которого округляется число.
Замечание: Если количество цифр больше 0 (нуля), то число округляется с избытком до заданного количества десятичных разрядов после десятичной запятой. Если количество цифр равно 0 или опущено, то число округляется с избытком до ближайшего целого. Если количество цифр меньше 0, то число округляется с избытком, с учетом десятичных разрядов слева от десятичной запятой.
1
Теоретическая
кривая nPj
рассчитывается по результатам лаб.раб.
№3 «Проверка нормальности…» с помощью
критерия согласия
![]() .
В данной работе может служить огибающей
гистограммы. Приводится для наглядности.
.
В данной работе может служить огибающей
гистограммы. Приводится для наглядности.
1
Отметим,
что вопрос о минимальном числе значений
в интервале не имеет строгого решения.
Автор критерия К.Пирсон считает, что
не должно быть пустых интервалов [8]. Мы
можем порекомендовать следующий выход
из положения: примем
![]() .
Если при вычислении статистики критерия
одно из слагаемых окажется существенно
больше остальных, причем
будет мало (< 5), объедините этот интервал
с соседним.
.
Если при вычислении статистики критерия
одно из слагаемых окажется существенно
больше остальных, причем
будет мало (< 5), объедините этот интервал
с соседним.
1 Нужно отметить, что границ интервалов на одно значение больше чем частот, поэтому первому или последнему значению границы интервала будет соответствовать пустая ячейка частоты.
1 функция ФТЕСТ рассчитывает двустороннее -значение F-теста, поэтому для рассматриваемого случая это значение делится на 2.
2
Если
![]() то
-значение
F-теста
рассчитывается с помощью функции FРАСП,
вычтенной из 1.
то
-значение
F-теста
рассчитывается с помощью функции FРАСП,
вычтенной из 1.
1 Сведения о Парном двухвыборочном t-тесте для средних см. в Справочной системе Microsoft Excel.