

Вопросы и задания (п. 1. – 4.)
1. Очертите класс экономических систем.
2. В чем проявляется системность рынков?
3. Дайте определение понятия "экономическая система".
4. Сделайте постановку задачи многокритериальной оптимизации процесса создания и эксплуатации КИС.
5. Дайте определение понятия "информация".
6. Дайте определение понятия "данные".
7. Дайте определение понятия "знания".
8. Как соотносятся между собой понятия "данные", "информация" и "знания"?
9. Как классифицируются знания по отношению к их носителям?
10. Приведите примеры формализованных и неформализованных знаний.
11. Что составляет методологию экономики, основанной на знаниях?
12. Что изучает эпистемология?
13. Как экономическая теория интерпретирует функционирование экономической системы?
14. В чем заключается ресурсное обеспечение функционирования экономической системы?
15. Как взаимосвязаны понятия "функционирование" и "процессы" в экономических системах?
16. В чем разница между форматированными и неформатированными информационными сообщениями?
17. В чем состоит основная задача начального этапа создания КИС?
18. Что понимают под предметной областью при проектировании КИС?
19. Какие основные требования предъявляют к ИМЭС? Перечислите и дайте их смысловую интерпретацию.
Темы для рефератов и эссе
-
Эпистемология — наука о знаниях.
-
Системные характеристики экономики, основанной на знаниях.
-
Системы управления знаниями.
Техника информационного моделирования
5. Графические средства информационного моделирования
Информационные модели нашли широчайшее применение в экономической сфере. В настоящее время любая компания стремится внедрить систему менеджмента качества и иметь международный сертификат качества. Однако известно, что в основе системы менеджмента качества лежит формализованное описание бизнес-процессов компании, что в совокупности является не чем иным, как одной из модификаций информационной модели. С другой стороны, качественное осуществление функций менеджмента сегодня не мыслится без применения информационных технологий. Последние предназначены для поддержки процедур выработки и реализации управленческих решений на всех стадиях воспроизводственного цикла и, как правило, увязываются в единую компьютерную информационную систему. Проектирование КИС тоже предполагает формирование информационной модели предметной области. В данной главе рассматривается один из наиболее популярных видов информационных моделей экономических систем — диаграммы потоков данных. Они в одинаковой мере используются как при проведении реинжиниринга, который предшествует внедрению системы менеджмента качества и международной сертификации, так и на начальных этапах проектирования информационных систем.
Графические средства построения ИМЭС ныне приобретают все большую популярность. Существует ряд инструментальных систем проектирования, для которых исходные данные представляются в виде совокупности графических схем. На основе последних в конечном итоге генерируются структуры баз данных и прикладное программное обеспечение информационной системы.
Одним из наиболее распространенных видов информационной модели экономической системы являются так называемые диаграммы потоков данных (ДПД). При построении диаграмм потоков данных используются "строительные" элементы четырех типов:
-
сущности;
-
потоки данных;
-
процессы;
-
накопители данных.
Коротко остановимся на каждом из них.
Сущности. Сущностями обычно являются логические классы информационных объектов экономической системы, которые представляют собой источники либо приемники информационных сообщений. Например: заказчики; поставщики; налогоплательщики; персонал; держатели акций; бухгалтерия; информационно-поисковая система; склад; цех и т.п.
Сущность обозначается квадратом, верхняя и левая стороны которого имеют двойную толщину (рис. 5.1). Для ссылок сущность обозначается идентификатором в верхнем левом углу (см. рис. 5.1, а). При построении ДПД желательно дать словесную интерпретацию каждой сущности, особенно если возможно ее неоднозначное толкование.
Для того чтобы избежать пересечения линий потоков данных, одна и та же сущность может изображаться на ДПД несколько раз. Квадраты, обозначающие одинаковые сущности, имеют перечеркнутый правый нижний угол (см. рис. 5.1, б). Если рассматриваемая сущность находится за пределами границ исследуемой системы, то при дублировании на схеме она перечеркивается двумя линиями (см. рис. 5.1, в).

Рис. 16.1. Варианты обозначения сущностей на ДПД:
а — простая сущность; б — дублированные внутренние сущности;
в — дублированные внешние сущности
Поток данных. Изображается стрелкой, предпочтительно горизонтальной или вертикальной. Направление стрелки указывает направление потока (рис. 16.2). Там, где поток данных идет в двух направлениях, можно использовать двойную стрелку (рис. 5.2, а), или фиксировать каждый поток в отдельности (рис. 5.2, б).
Каждый поток данных должен рассматриваться как пневмопочта, по которой посылаются пакеты данных. На поток данных можно ссылаться, указывая процессы, сущности или накопители данных, которые поток соединяет. Тем не менее каждый поток данных должен иметь наименование, которое указывается вдоль стрелки или над ней. Наименование должно отражать смысл содержимого потока.
В первоначальных вариантах наименование потока данных представляется строчными буквами (рис. 5.3, а). На более поздних стадиях, когда эти наименования найдут отражение в словаре данных, их заменяют на прописные буквы (рис. 5.3, б).
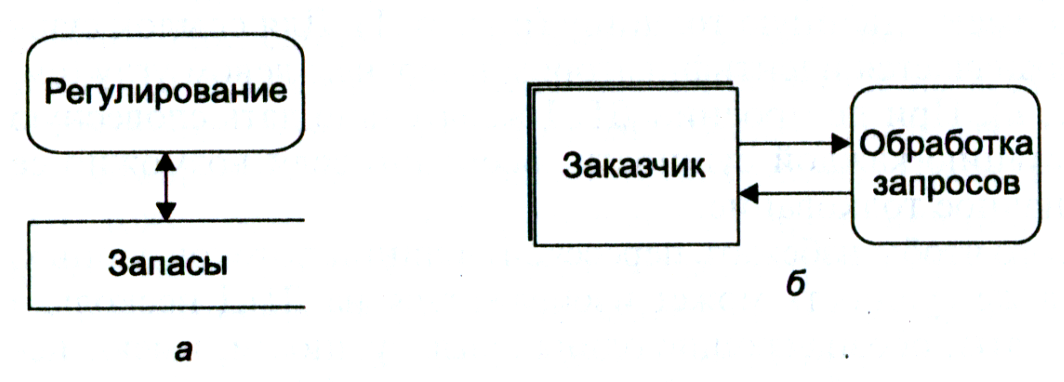
Рис. 5.2. Двунаправленные потоки данных: а — единая потоковая магистраль; 6 — разделенные встречные потоки

Рис. 5.3. Примеры наименований потоков данных: а – первоначальный вариант; б — проектный вариант, зафиксированный в словаре данных
Часто оказывается, что в одном и том же потоке данных помещается несколько "пакетов" данных, и тогда бывает трудно подобрать наименование, которое адекватно отражало бы содержимое потока данных. Например, заказчики могут высылать заказы, отправлять платежи, делать возврат поврежденных товаров, отправлять запросы, предъявлять претензии и т.д. Очень неудобно рисовать множественные потоки данных (рис. 5.4, а).

Рис. 5.4. Приемы дезагрегации потоков данных: а — исходный поток данных; б — агрегация потоков с последующей маршрутизацией; в — маршрутизация потоков по процессам
Есть два выхода из этого положения:
а) агрегация потоков в один поток под общим наименованием, содержание которого следует искать или в словаре данных, или при просмотре выходных данных блока, принимающего данный поток (на рис. 5.4, б это функция "Маршрутизация транзакций");
б) каждому типу сообщений выделяется отдельный поток (см. рис. 5.4, в), направленный к специальному процессу (применяется в том случае, если каждое сообщение обрабатывается различными способами и в действительности состоит из различных элементов данных).
Процессы. Процессы описывают функции обработки данных и обозначаются прямоугольниками с закругленными углами, разделенными на три сектора (рис. 5.5).

Рис. 5.5. Условное обозначение процесса
Для идентификации процесс просто нумеруется. Нумерация процессов не должна меняться, за исключением разделения или объединения процессов, поскольку она служит в качестве ссылки для потоков данных и используется при декомпозиции процессов.
Наименование функции следует представлять в форме предложения, начинающегося с глагола в неопределенной форме. Например: "Предоставить информацию о ежедневных продажах", "Ввести новые сведения о заказчике", "Проверить платежеспособность заказчика". Основное требование при этом заключается в том, что описание функции должно восприниматься однозначно всеми участниками разработки.
В нижнем секторе блока "Процесс" дается ссылка на исполнителя данной функции. Это может быть специалист, группа специалистов, департамент фирмы или компьютерная программа (рис. 5.6).
Накопители данных. Накопители данных — это центры возникновения и хранения данных. Каждый накопитель идентифицируется буквой D с произвольным числом в квадрате с левой стороны (рис. 5.7). Имя накопителя данных должно быть максимально информативным для пользователя.

Рис. 5.6. Примеры описания процессов

Рис. 5.7. Идентификация накопителей данных:
а — накопитель данных; б — дублированные накопители данных
Для того чтобы не усложнять диаграмму потоков данных пересечением линий, используют дубликаты накопителей данных, обозначая их дополнительными вертикальными линиями с левой стороны квадрата.
Когда процесс сохраняет данные, то стрелка потока данных направлена в накопитель данных (рис. 5.8, а), и наоборот, когда данные вчитываются с накопителя данных, то стрелка имеет направление к процессу (рис. 5.8, б). Если при считывании данных необходимо задать аргумент поиска, то он фиксируется на противоположной от наименования стороне потока данных. Аргумент поиска, как правило, формируется в процессе и передается в накопитель данных, как это показано на рис. 5.8, в.

Рис. 5.8. Доступ к накопителям данных: а — запоминаемые данные; б — считываемые данные; в - спецификация аргумента поиска
С помощью перечисленных элементов строится графическая информационная модель предметной области, называемая диаграммой потоков данных, которая в последующем играет роль объединяющего звена на всем жизненном цикле разработки и развития КИС. На ее основе осуществляется декомпозиция КИС по комплексам и задачам, устанавливается очередность разработки системы (выделяются очереди КИС), определяются источники и величина ожидаемого экономического эффекта и принимаются другие важные проектные решения.
Как следует из материала настоящей темы, при построении диаграмм потоков данных используются как естественный, так и графический языки.
Источником естественного языка служат люди, описывающие систему, а источником графического языка - сама методология моделирования. Графический язык модели обеспечивает структуру, близкую к естественному языку, и накладывает на последний некоторые ограничения, повышая тем самым точность семантики языка модели. Следовательно, графический язык диаграмм потоков данных организует естественный язык вполне определенным и однозначным образом и за счет этого позволяет адекватно описывать экономические системы.