

2 Методы дистантного сопоставления с эталоном
Постановка
задачи. Необходимо
обнаружить объект с известным контуром
с известным контуром и
неизвестными координатами точки привязки
и
неизвестными координатами точки привязки на двумерном сигнале
на двумерном сигнале .
Априори известно множество эталонных
объектов
.
Априори известно множество эталонных
объектов с известными границами
с известными границами и рисунками интенсивностей.
и рисунками интенсивностей.
Представим сигнал
сканирующего устройства в виде
упорядоченного во временном и
пространственном интервале двумерного
множества значений
 ,
в котором можно выделить несколько
подмножеств значений: множество значений
интенсивности объекта и фона.
,
в котором можно выделить несколько
подмножеств значений: множество значений
интенсивности объекта и фона.
В случае априорной
неопределенности значения точки привязки
объекта, решение относительно его
обнаружения принимается посредством
анализа меры сходства эталонного объекта
 и анализируемого объекта
и анализируемого объекта .
.
Мера сходства двух объектов в простейшем случае может быть среднеквадратичной ошибкой
 , (1.10)
, (1.10)
или модулем разностей для сокращения числа производимых операций,
 . (1.11)
. (1.11)
вычисленных по области перекрытия смещенного эталона и самого объекта.
При «плавающем» значении среднего общего уровня интенсивности сигнала (например, при изменении общей чувствительности) можно воспользоваться мерой сходства, инвариантной к изменениям среднего уровня рисунка интенсивностей
 , (1.12)
, (1.12)
где
 - средний уровень интенсивности
обнаруживаемого объекта;
- средний уровень интенсивности
обнаруживаемого объекта;
 - средний уровень интенсивности эталонного
объекта.
- средний уровень интенсивности эталонного
объекта.
Значение меры сходства лежат в пределах от 0 до 1, что существенно облегчает принятие решения об обнаружении объекта.
Точное совпадение
эталона с какой-либо частью рисунка
интенсивностей в реальной ситуации
практически невозможно, вследствие
наличий зашумленности исходного сигнала,
а также, вследствие наличия априорной
неопределенности относительно точной
формы, размеров и структуры локализуемого
объекта. В таком случае вывод о присутствии
искомого объекта делается на основании
превышения приведенных выше мер сходства
некоторого порога обнаружения
 ,
который обычно выбирается одинаковым
для всех точек:
,
который обычно выбирается одинаковым
для всех точек:
 . (1.13)
. (1.13)
Второй типовой разновидностью методов эталонных обнаружений является процесс сравнения образа с эталоном при помощи функции взаимной корреляции [134] и позволяет принимать решение об обнаружении объекта при условии присутствия максимально «яркого» корреляционного отклика.
То есть, если взять меру различия между эталонным объектом и детектируемым как
 , (1.14)
, (1.14)
и представить это равенство в виде:
 , (1.15)
, (1.15)
 , (1.16)
, (1.16)
 , (1.17)
, (1.17)
 . (1.18)
. (1.18)
Слагаемое
 - это энергия эталона, которая является
постоянной и не зависит от координат
объекта
- это энергия эталона, которая является
постоянной и не зависит от координат
объекта .
Энергия детектируемого объекта в
пределах сканирующего окна представлена
слагаемым
.
Энергия детектируемого объекта в
пределах сканирующего окна представлена
слагаемым .
Второе слагаемое
.
Второе слагаемое - это взаимная корреляция детектируемого
объекта и эталона. При совпадении
двумерного сигнала объекта и эталона
корреляция будет велика, что, в свою
очередь, приводит к малым значениям
среднеквадратической ошибки.
- это взаимная корреляция детектируемого
объекта и эталона. При совпадении
двумерного сигнала объекта и эталона
корреляция будет велика, что, в свою
очередь, приводит к малым значениям
среднеквадратической ошибки.
Степень отличия
объектов не всегда адекватно отражается
их взаимной корреляцией. Поскольку
энергия детектируемого объекта при
такой оценке зависит от координат.
Взаимная корреляция может увеличиваться
даже при сравнении разных объектов,
если величина сигналов в точке
 велика.
велика.
Такое ограничение «обходится» использованием другой меры сходства детектируемого объекта с эталоном – нормированной взаимной корреляцией.
 . (1.19)
. (1.19)
В таком случае, обнаружение сигнала считается истинным, если значение нормированной взаимной корреляции больше порога обнаружения
 (1.20)
(1.20)
Основное применение подобные методы находят в кластерном анализе или в некоторых приложениях цифровой обработки изображений. С некоторыми допущениями и ограничениями эти методы также могут быть применимы для частных случаев обнаружения объектов.
Их использование ограничено ситуациями, когда нам известны форма и размеры объекта, который необходимо найти в данном секторе, однако неизвестны его координаты.
Достоинствами данного метода является его простота исполнения, малые вычислительные затраты, а также то, что обнаружение объекта не зависит от изменения его координат по вертикали и горизонтали, так как обнаружение объекта производится параллельно с оценкой его координат. Дополнительным преимуществом является и более высокая помехоустойчивость метода по сравнению с остальными.
Недостатком метода является то, что для обнаружения объектов разных типов нам необходимо хранить большую базу эталонных объектов в разных положениях, масштабах и, возможно даже для разных уровней чувствительности. При добавлении в базу эталонов нового обнаруживаемого объекта, необходимо занесение его «копий» во всех допустимых масштабах и поворотах, что существенно увеличивает затраты памяти обнаружителя, а также времени обнаружения пропорционально количеству вводимых объектов.
Дополнительные ограничения применения привносит то, что такое изменение формы объекта как, например, масштабирование или перекрывание, делает данный метод неприменимым для обнаружения большинства объектов в реальных ситуациях с большим уровнем неопределенности.
Так как в постановке задачи настоящей диссертации точная априорная информация о форме объекта, его ориентации и масштабе отсутствует, то вышеперечисленные методы неприменимы для решения исследуемой проблемы.
Перцептивный хэш-алгоритм
Упрощенный хэш
Суть данного алгоритма заключается в отображении среднего значения низких частот. В изображениях высокие частоты обеспечивают детализацию, а низкие – показывают структуру. Поэтому для построения такой хэш-функции, которая для похожих изображений будет выдавать близкий хэш, нужно избавиться от высоких частот. Шаги алгоритма следующие:
уменьшить размер. Самый быстрый способ избавиться от высоких частот — уменьшить изображение. Изображение уменьшаетсядоразмера 32х32;
убрать цвет. Маленькое изображение переводится в градации серого, так что хэш уменьшаетсявтрое;
найти среднее. Вычислить среднее значение цвета для всех 1024 пикселей;
построить цепочку битов. Для каждого пикселя делается замена цвета на 1 или 0 в зависимости от того, больше или меньше среднего, как показано на рисунке 7:

Рисунок 6 – Исходное изображение

Рисунок 7 – Полученный отпечаток
построить хэш. Перевод битов в одно значение. Порядок неимеет значения, нообычно биты записываются слева направо, сверху вниз;
Полученный хэшразмером128 байтустойчив к масштабированию, сжатию или растягиванию изображения, изменению яркости, контраста, манипуляциями с цветами. Но главное достоинство алгоритма – скорость работы. Для сравнения хэшей этого типа используется функция нормированного расстоянияХэмминга
Функции сравнения перцептивных хэш-значений
Перцептивные хэш-функции вычисляют похожие хэш-значения для похожих изображений. Существует несколько способов определить насколько похожи хэш-значения. В 4 описанных в предыдущем разделе алгоритмах используется две функции сравнения: расстояние Хэмминга(Hamming distance) и пик взаимнокорреляционной функции(Peak of Cross Correlation, PCC).
Расстояние Хэмминга
Расстояние Хэмминга определяет количество различных позиций между двумя бинарными последовательностями.
Пусть А – алфавит
конечной длины.
 бинарные
последовательности (векторы). Расстояние
Хэмминга ∆ междуxиyопределим как
бинарные
последовательности (векторы). Расстояние
Хэмминга ∆ междуxиyопределим как
 (2.1)
(2.1)
Этот способ сравнения хэш-значений используется в методе DCT Based Hash. Хэш занимает размер 8 байт, поэтому расстояние Хэмминга лежит в отрезке [0, 64].Чем меньше значение ∆, тем более похожи изображения.
Для облегчения сравнения расстояние Хэмминга можно нормировать с помощью длины векторов:
 (2.2)
(2.2)
Нормированное
расстояние Хэмминга используется в
алгоритмах SimpleHashиMarr-HildrethOperatorBasedHash. Расстояние Хэмминга
лежит в промежутке [0,1] и чем ближе к 0, тем более похожи изображения.
к 0, тем более похожи изображения.
Пик взаимнокорреляционной функции
Корреляцию между двумя сигналами определим как:
 (2.3)
(2.3)
где x(t) иy(t) - две непрерывные функции вещественных чисел.
Функция
 описывает смещение этих двух сигналов
относительно времени T. Переменная T
определяет насколько сигнал смещен
слева. Если сигналыx(t)
иy(t)
различны, функция
описывает смещение этих двух сигналов
относительно времени T. Переменная T
определяет насколько сигнал смещен
слева. Если сигналыx(t)
иy(t)
различны, функция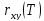 называется взаимнокорреляционной.
называется взаимнокорреляционной.
Пусть
 и
и ,
гдеi= 0, …N− 1 – две последовательности вещественных
чисел, аN– длина
обеих последовательностей. НВФ с
задержкойdопределим как
,
гдеi= 0, …N− 1 – две последовательности вещественных
чисел, аN– длина
обеих последовательностей. НВФ с
задержкойdопределим как
 (2.4)
(2.4)
где mxиmyобозначают среднее значение для соответствующей последовательности.
Пик взаимнокорреляционной
функции(PCC) – максимальное значение
функции
 ,
которое может быть достигнуто на
промежуткеd=[0,N].
,
которое может быть достигнуто на
промежуткеd=[0,N].
PCC используется для сравнения хэш-значений в алгоритме Radial Variance Based Hash. PCC ∈[0,1], чем больше его значение, тем более похожи изображения.
Синтез основного алгоритма
Целью данной работы является создание программного комплекса, способного в реальном времени производить анализ каждого кадра видеопотока, выделять отдельные лица и сопоставлять их с элементами ограниченного множества лиц, заданного заранее или формируемого в процессе работы системы.
Далее приведен основной алгоритм работы программного комплекса.
прием кадра из видеопотока локальной веб-камеры (удаленной IP-камеры или видеофайла);
предварительная подготовка данных, то есть преобразование изображения в серых тонах;
выделение лиц на полученном кадре на базе алгоритма Виолы-Джонса с предустановленными признаками Хаара;
выделение кадра с найденными лицами в коллекцию;
вычисление перцептивных хэшей для элементов этой коллекции;
сравнение каждого хэша с хэшами из базы данных и нахождение минимального расстояния между ними по Хэммингу;
отображение найденного лица и визуализация данных о нем;
Для реализации данного алгоритма были разработаны программа cvFacehashи подпрограммаcvHashCalc.
Алгоритм работы программы cvFaceHash:
загрузка базы данных. В данной базе хранятся перцептивные хэши лиц, которые необходимо найти в видеопотоке;
выделение лиц на полученном кадре на базе алгоритма Виолы-Джонса с предустановленными признаками Хаара;
расчет хэша найденного лица в видеопотоке;
сравнение каждого хэша с хэшами из базы данных и нахождение минимального расстояния между ними по Хэммингу;
отображение найденного лица и визуализация данных о нем;
Алгоритм работы программы cvFaceHashна представлен на рисунке 8.

Рисунок 8 – Функциональная блок-схема алгоритма cvFaceHash
Подпрограмма cvHashCalccзаписывает изображения лица человека по нажатию клавиши «Enter» под определенном именем. По завершению записывания, программа делает расчеты перцептивного хэша каждого сохраненного изображения. Далее сохраняет в базе данных перцептивные хеши. Алгоритм работы программыcvHashCalcпредставлен на рисунке 9.

Рисунок 9 – Функциональная блок-схема алгоритма cvHashCalc
Разработка программного решения
Выбор среды для разработки
Для распознавания лиц на изображениях и видеопоследовательностях в реальном времени на языке объектно-ориентированного программирования C# (Visual studio 2010) с использованием библиотеки OpenCV разработано программное обеспечение.
Библиотека OpenCV
OpenCV (от англ. Open Source Computer Vision Library, библиотека компьютерного зрения с открытым исходным кодом) — библиотека алгоритмов компьютерного зрения, обработки изображений и численных алгоритмов общего назначения с открытым кодом. Реализована на C/C++, также разрабатывается для C#, Python, Java, Javascript, Ruby, Matlab, Lua и других языков. Может свободно использоваться в академических и коммерческих целях — распространяется в условиях лицензии BSD.
Это библиотека, которая до 1-й версии разрабатывалась в Центре разработки программного обеспечения Intel (причём, российской командой в Нижнем Новгороде). OpenCV написана на языке высокого уровня (C/C++) и содержит алгоритмы для: интерпретации изображений, калибровки камеры по эталону, устранение оптических искажений, определение сходства, анализ перемещения объекта, определение формы объекта и слежение за объектом, 3D-реконструкция, сегментация объекта, распознавание жестов и т.д.
Эта библиотека очень популярна за счёт своей открытости и возможности бесплатно использовать как в учебных, так и коммерческих целях.
Фактически, OpenCV – это набор типов данных, функций и классов для обработки изображений алгоритмами компьютерного зрения.
Основные модули библиотеки
Библиотека OpenCV состоит из нескольких модулей:
CXCORE– ядро, содержит:
базовые структуры;
матричную алгебру;
алгоритмы работы с памятью;
алгоритмы преобразования типов;
алгоритмы для обработки ошибок;
функции для записи/чтения XML файлов;
функции для работы с 2D графиками.
CV– модуль обработки изображений, работа с компьютерным зрением, содержит:
функции для работы с изображениями (преобразование, фильтрация и т.д.);
функции для анализа изображений (поиск контуров, гистограммы и т.д.);
алгоритмы анализа движений, слежение за объектами;
алгоритмы распознания объектов (лиц, предметов);
алгоритмы для калибровки камер.
ML– машинное обучение:
функции для классификации и анализа данных.
HighGUI– модуль для создания пользовательского интерфейса, отвечает за:
создание окон;
вывод изображений;
захват видео из файлов и камер;
чтение/запись изображений.
CVCAM– захват видео с цифровых камер.
CVAUX– устаревшие функции:
пространственное зрение;
нахождение и описание черт лица;
поиск стерео соответствий;
описание текстур.
Поддерживаемые компиляторы:
Windows - Microsoft Visual C++, Borland C++, Intel Compiler, MinGW, Linux - GCC, Intel Compiler, Mac - Intel Compiler, Carbon и др.
В версии 2.2 структура библиотека реорганизована — теперь вместо больших универсальных модулей (cxcore, Cvaux, Highgui, Cvaux) библиотека OpenCV разделена на небольшие модули по функцианальному использованию:
opencv_core— основная функциональность. Включает в себя базовые структуры, вычисления (математические функции, генераторы случайных чисел) и линейную алгебру, DFT, DCT, ввод/вывод для XML и YAWL и т. д.
opencv_imgproc— обработка изображений (фильтрация, геометрические преобразования, преобразование цветовых пространств и т. д.).
opencv_highgui— простой UI, ввод/вывод изображений и видео.
opencv_ml— модели машинного обучения (SVM, деревья решений, обучение со стимулированием и т. д.).
opencv_features2d— распознавание и описание плоских примитивов (SURF (англ.)русск., FAST и другие, включая специализированный фреймворк).
opencv_video— анализ движения и отслеживание объектов (оптический поток, шаблоны движения, устранение фона).
opencv_objdetect— обнаружение объектов на изображении (нахождение лиц с помощью алгоритма Виолы-Джонса (англ.), распознавание людей HOG и т. д.).
opencv_calib3d— калибровка камеры, поиск стерео-соответствия и элементы обработки трехмерных данных.
opencv_flann— библиотека быстрого поиска ближайших соседей (FLANN 1.5) и обертки OpenCV.
opencv_contrib— сопутствующий код, ещё не готовый для применения.
opencv_legacy— устаревший код, сохраненный ради обратной совместимости.
opencv_gpu — ускорение некоторых функций OpenCV за счет CUDA, создан при поддержке NVidia.
Использование средств OpenCV в работе
Для использования средств, предоставляемых библиотекой OpenCVв проектах и для оценки ее возможностей необходимо сначала изменить настройки проекта с исходным кодом. В тестовых задачах использовался язык разработкиC++ и библиотека стандартных шаблоновSTLв средеVisualStudio2013.
Для подключения библиотеки OpenCVиспользовалась схема настройки параметров проекта:
исходные коды: c:\opencv\opencv\modules\;
подключаемые файлы: c:\opencv\opencv\build\include\;
исполняемые файлы: c:\opencv\opencv\build\x86\vc11\bin\;
библиотека: c:\opencv\opencv\build\x86\vc11\lib\.
Дополнительные элементы, которые нужно добавить в командную строку компоновки:
opencv_calib3d246d.lib;
opencv_contrib246d.lib;
opencv_core246d.lib;
opencv_features2d246d.lib;
opencv_flann246d.lib;
opencv_gpu246d.lib;
opencv_haartraining_engined.lib;
opencv_highgui246d.lib;
opencv_imgproc246d.lib;
opencv_legacy246d.lib;
opencv_ml246d.lib;
opencv_nonfree246d.lib;
opencv_objdetect246d.lib;
opencv_ocl246d.lib;
opencv_photo246d.lib;
opencv_stitching246d.lib;
opencv_superres246d.lib;
opencv_ts246d.lib;
opencv_video246d.lib;
opencv_videostab246d.lib.
Стандартное подключение к исходному коду:
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/nonfree/nonfree.hpp>
#include <opencv2/objdetect/objdetect.hpp>