

Курсовые проекты / лабы не мои / лаба3 / отчёт3 / отчёт3
.docМинистерство образования РФ
Уфимский Государственный Авиационный Технический Университет
Кафедра ТК
Лабораторная работа №2
“ Проектирование лексического анализатора ”
Выполнил: ст.гр УТС-411
Файзуллин Р.Р.
Ситдикова О.
Проверил: доцент кафедры ТК
Карамзина А.Г.
Уфа 2007
Цель работы: изучение основных понятий теории регулярных грамматик, ознакомление с назначением и принципами работы лексических анализаторов (сканеров), получение практических навыков построения сканера на примере заданного простейшего входного языка.
Вариант 2: входной язык содержит логические выражения, разделенные символом ; (точка с запятой). Логические выражения состоят из идентификаторов, констант true и false, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
КС-грамматика входного языка в форме Бэкуса-Наура:
^-знак пробела
G({0..9, a..z, ;, (, ), :, =,^}, {R,ZZ,OO,Q,Q1,I,A,A1,A2,N,N1,N2,X,X1,X2,O,O1,T,T1,T2,T3,F,F1,F2,F3,F4},P,S)
P:
H®H^
R®H;
ZZ®H)
OO®H(
Q®H:
Q1®Q=
I®Hb..He|Hg..Hm|Hp..Hs|Hu..Hw|Hy|Hz|Aa..Am|Ao..Az|A0..A9|A1a..A1c|A1e..A1z|A10..A19|A2a..A2z|A20..A29|Na..Nn|Np..Nz|N0..N9|N1a..N1s|N1u..N1z|N10..N19|N2a.. N2z|N20..N29|Xa..Xn|Xp..Xz|X0..X9|X1a..X1q|X1s..X1z|X10..X19|X2a…X2z|X20..X29| Oa..Oq|Os..Oz|O0..O9|O1a..O1z|O10..O19|Ta..Tq|Ts..Tz|T0..T9|T1a..T1t|T1v..T1z|T10..T19|T2a..T2d|T2f..T2z|T20..T29|T3a..T3z|T30..T39|Fb..Fz|F0..F9|F1a..F1k|F1m..F1z|F10..F19|F2a..F2r|F2t..F2z|F20..F29|F3a..F3d|F3f..F3z|F30..F39|F4a..F4z|F40..F49|Ia..Iz||I0..I9
A®Ha
A1®An
A2®A1d
N®Hn
N1®No
N2®N1t
X®Hx
X1®Xo
X2®X1r
O®Ho
O1®Or
T®Ht
T1®Tr
T2®T1u
T3®T2e
F®Hf
F1®Fa
F2®F1l
F3®F2s
F4®F3e
S®R^|ZZ^|OO^|Q1^|A2^|N2^|X2^|O1^|T3^|I^|F4^
Фрагмент графа переходов КА для разделяющего знака, знака пробела, круглых открывающихся и закрывающихся скобок, знака присваивания, представлен на рис.1.
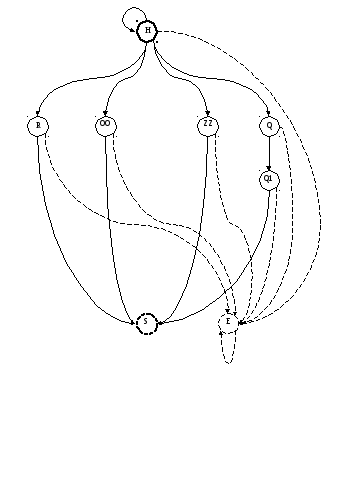
Рис.1. Фрагмент графа переходов КА разделяющего знака, скобок и знака присваивания.
Фрагмент графа переходов КА для идентификатора, операторов сравнения “xor”, “not”, “and”, “or” представлен на рис.2.
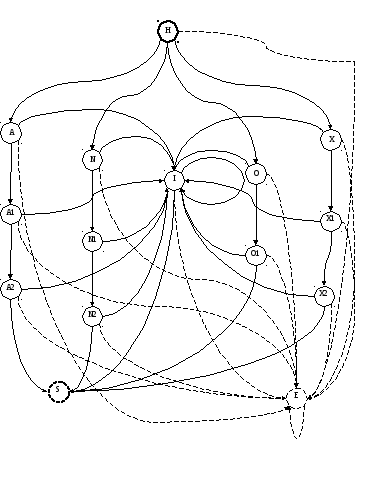
Рис.2. Фрагмент графа переходов КА идентификатора и операторов сравнения “xor”, “not”, “and”, “or”.
Фрагмент графа переходов КА для идентификатора и логических констант "false" и "true" представлен на рис.3.
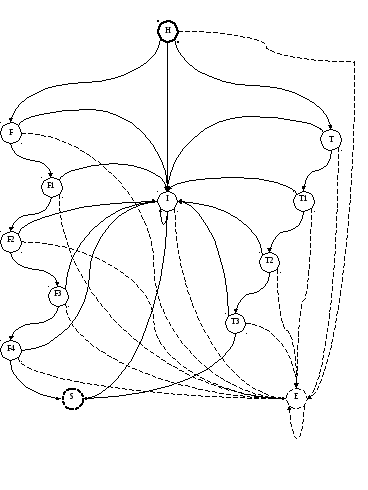
Рис.3. Фрагмент графа переходов КА идентификатора и логических констант "false" и "true".
Листинг программы:
unit Unit2;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, ComCtrls, StdCtrls, Grids;
type
TAutoState = ( AUTO_H, AUTO_ZZ, AUTO_OO, AUTO_Q, AUTO_R, AUTO_E, AUTO_Q1, AUTO_S, AUTO_A, AUTO_A1, AUTO_A2, AUTO_I, AUTO_N, AUTO_N1, AUTO_N2, AUTO_O, AUTO_O1, AUTO_X, AUTO_X1, AUTO_X2, AUTO_F, AUTO_F1, AUTO_F2, AUTO_F3, AUTO_F4, AUTO_T, AUTO_T1, AUTO_T2, AUTO_T3 );
TForm1 = class(TForm)
OpenDialog1: TOpenDialog;
PageControl1: TPageControl;
TabSheet1: TTabSheet;
Edit1: TEdit;
Button1: TButton;
Button2: TButton;
Memo1: TMemo;
TabSheet2: TTabSheet;
StringGrid1: TStringGrid;
Button3: TButton;
Memo2: TMemo;
Label1: TLabel;
Label2: TLabel;
Edit2: TEdit;
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Button3Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.Button1Click(Sender: TObject);
Var str:string;
begin
str:=Edit1.Text;
if Edit1.Text<>'' then Memo1.Lines.LoadFromFile(str)
else ShowMessage('Поле ввода файла пустое!');
end;
procedure TForm1.Button2Click(Sender: TObject);
begin
if OpenDialog1.Execute then Memo1.Lines.LoadFromFile(OpenDialog1.FileName) ;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
Memo1.Text:='';
Memo2.Text:='';
StringGrid1.Cells[0,0]:='№ п/п';
StringGrid1.Cells[1,0]:='Значение';
StringGrid1.Cells[2,0]:='Лексема';
end;
procedure TForm1.Button3Click(Sender: TObject);
var
ind,pos,dl,i,j,i1,fl,zn:integer;
st,str,stroka:string;
sost:TAutoState;
begin
for i:=0 to 2 do
for i1:=1 to 999 do
StringGrid1.Cells[i,i1]:='';
i1:=Memo1.Lines.Count;
ind:=1;
pos:=1;
for i:=1 to i1 do
begin
str:='';
stroka:=Memo1.Lines[i-1];
stroka:=stroka+' ';
dl:=Length(stroka);
sost:=AUTO_H;
fl:=0;
zn:=0;
for j:=1 to dl do
begin
st:=stroka[j];
case sost of
AUTO_H:
case stroka[j] of
';': begin sost:=AUTO_R;str:=str+st; end;
'(': begin sost:=AUTO_OO;str:=str+st; end;
')': begin sost:=AUTO_ZZ;str:=str+st; end;
':': begin sost:=AUTO_Q;str:=str+st; end;
'a': begin sost:=AUTO_A;str:=str+st; end;
'n': begin sost:=AUTO_N;str:=str+st; end;
'o': begin sost:=AUTO_O;str:=str+st; end;
'x': begin sost:=AUTO_X;str:=str+st; end;
't': begin sost:=AUTO_T;str:=str+st; end;
'f': begin sost:=AUTO_F;str:=str+st; end;
'b'..'e','g'..'m','p'..'s','u'..'w','y','z': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;str:=''; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_R:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=1; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_OO:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=2; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_ZZ:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=3; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_Q:
case stroka[j] of
'=': begin sost:=AUTO_Q1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_Q1:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=4; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_A:
case stroka[j] of
'a'..'m','o'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'n': begin sost:=AUTO_A1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_A1:
case stroka[j] of
'a'..'c','e'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'd': begin sost:=AUTO_A2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_A2:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=6; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_N:
case stroka[j] of
'a'..'n','p'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'o': begin sost:=AUTO_N1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_N1:
case stroka[j] of
'a'..'s','u'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
't': begin sost:=AUTO_N2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_N2:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=7; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_X:
case stroka[j] of
'a'..'n','p'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'o': begin sost:=AUTO_X1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_X1:
case stroka[j] of
'a'..'q','s'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'r': begin sost:=AUTO_X2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_X2:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=9; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_O:
case stroka[j] of
'a'..'q','s'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'r': begin sost:=AUTO_O1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_O1:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=8; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_T:
case stroka[j] of
'a'..'q','s'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'r': begin sost:=AUTO_T1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_T1:
case stroka[j] of
'a'..'t','v'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'u': begin sost:=AUTO_T2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_T2:
case stroka[j] of
'a'..'d','f'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'e': begin sost:=AUTO_T3;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_T3:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=10; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F:
case stroka[j] of
'b'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'a': begin sost:=AUTO_F1;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F1:
case stroka[j] of
'a'..'k','m'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'l': begin sost:=AUTO_F2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F2:
case stroka[j] of
'a'..'r','t'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
's': begin sost:=AUTO_F3;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F3:
case stroka[j] of
'a'..'d','f'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
'e': begin sost:=AUTO_F4;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F4:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=11; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_I:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_E: begin
if stroka[j]<>' 'then
begin
sost:=AUTO_E;
str:=str+st;
end
else
begin
sost:=AUTO_H;
Memo2.Lines.Append(str);
str:='';
end;
end;
end;
if fl=1 then
begin
StringGrid1.Cells[0,ind]:=IntToStr(ind);
StringGrid1.Cells[1,ind]:=str;
case zn of
1: StringGrid1.Cells[2,ind]:='Разделяюший знак';
2: StringGrid1.Cells[2,ind]:='Круглые открывающиеся скобки';
3: StringGrid1.Cells[2,ind]:='Круглые закрывающиеся скобки';
4: StringGrid1.Cells[2,ind]:='Знак присваивания';
5: StringGrid1.Cells[2,ind]:='Идентификатор';
6: StringGrid1.Cells[2,ind]:='Оператор сравнения "and"';
7: StringGrid1.Cells[2,ind]:='Оператор сравнения "not"';
8: StringGrid1.Cells[2,ind]:='Оператор сравнения "or"';
9: StringGrid1.Cells[2,ind]:='Оператор сравнения "xor"';
10: StringGrid1.Cells[2,ind]:='Логическая константа "true"';
11: StringGrid1.Cells[2,ind]:='Логическая константа "false"';
end;
str:='';
ind:=ind+1;
fl:=0;
end;
end;
end;
Edit2.Text:=IntToStr(ind-1);
end; end.
Результаты работы:
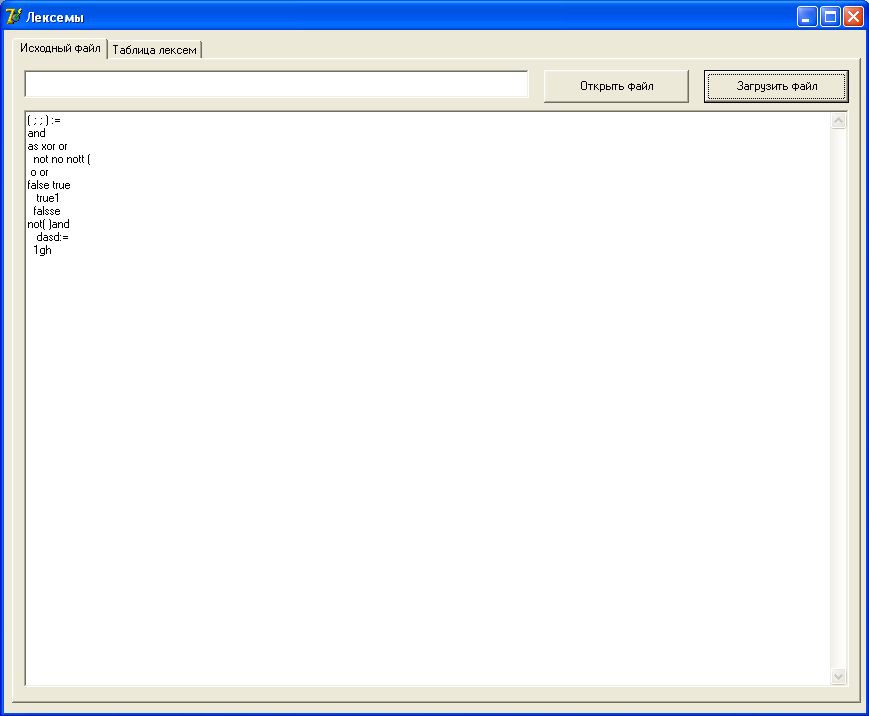
Рис.4. Модуль лексического анализатора (содержимое исходного файла).
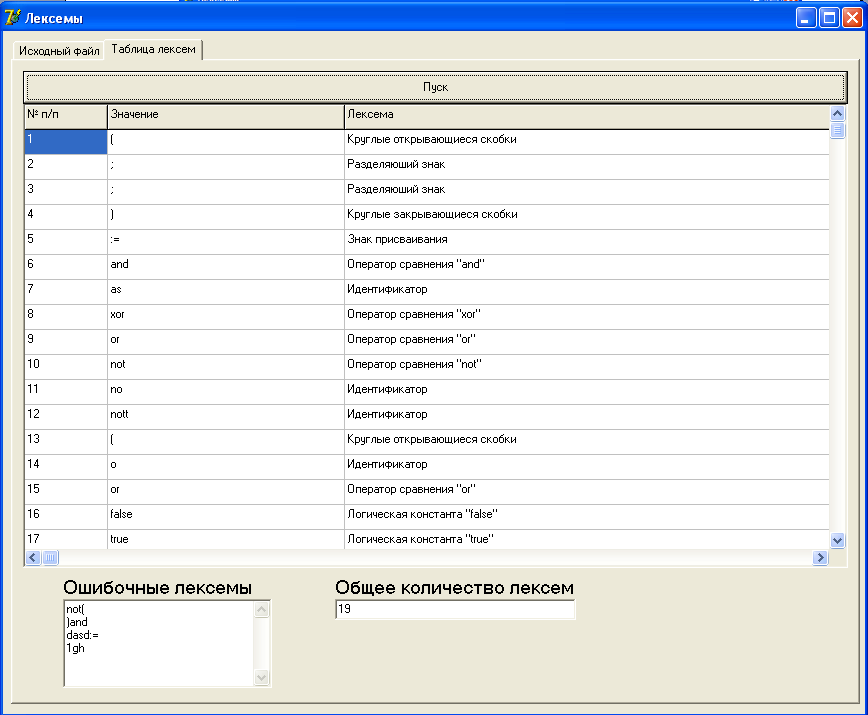
Рис.5. Модуль лексического анализатора (таблица лексем).
Вывод: в ходе проделанной работы были изучены основные понятия теории регулярных грамматик; был построен лексический анализатор, который позволяет выделить во входном тексте нужные лексемы; неверные лексемы анализатор помещает в поле ошибочных лексем, и продолжает работу пока не будет достигнут конец файла.