

Лабораторная работа №31 / Отчет
.doc
Уфимский Государственный Авиационный Технический Университет
Кафедра ТК
Отчет по лабораторной работе №3
Построение простейшего дерева вывода
по курсу «Системное программное обеспечение»
Вариант 6
Выполнил:
студент гр.Т28-420
Приняла: к.т.н.,
ст. преподаватель
Карамзина А.Г.
Уфа 2005
Цель работы
Изучение основных понятий теории грамматик простого и операторного предшествования, ознакомление с алгоритмами синтаксического анализа (разбора) для некоторых классов КС-грамматик, получение практических навыков создания простейшего синтаксического анализатора для заданной грамматики операторного предшествования.
Задание
Для выполнения лабораторной работы требуется написать программу, которая выполняет лексический анализ входного текста в соответствии с заданием, порождает таблицу лексем и выполняет синтаксический разбор текста по заданной грамматике с построением дерева разбора.
Текст на входном языке задается в виде символьного (текстового) файла. Допускается исходить из условия, что текст содержит не более одного предложения входного языка. Программа должна выдавать сообщения о наличие во входном тексте ошибок.
Для выполнения лабораторной работы возьмем тот же самый язык, который был использован для выполнения лабораторной работы №2
Этот язык может быть задан с помощью КС-грамматики.
Грамматика входного языка в форме Бэкуса-Наура
G( {or, xor, and, (, ), not, :=, b, ;}, {S, F, T, E, M, A}, P, S)
P:
S→ M;
M→ b:=F
F→ F or T | F xor T | T
T→ T and E | E
T→ ( F )
E→ A | not A | b
Множества крайних правых и левых символов
|
Символ (U) |
Шаг 1 (начало построения) |
Последний шаг (результат) |
||
|
L(U) |
R(U) |
L(U) |
R(U) |
|
|
S |
M |
; |
Ma |
; |
|
M |
a |
F |
a |
FTEA a ) |
|
F |
FT |
T |
FTEA not a |
TEA a ) |
|
T |
TE |
E |
TEA not a |
EA a ) |
|
A |
( |
) |
( |
) |
|
E |
A not a |
A a |
A not a ( |
A a ) |
Множества крайних правых и левых терминальных символов
|
Символ (U) |
Шаг 1 (начало построения) |
Последний шаг (результат) |
||
|
Lt(U) |
Rt(U) |
Lt(U) |
Rt(U) |
|
|
S |
; |
; |
a |
; |
|
M |
a |
:= |
a |
or, xor, and, not, a, ), := |
|
F |
or, xor |
or,xor |
or, xor, and, not, a, ( |
or, xor, and, not, a, ) |
|
T |
and |
and |
and, not, a, ( |
not a ) |
|
A |
( |
) |
( |
) |
|
E |
not a |
not a |
not a ( |
a ) |
На основе этих множеств и правил грамматики G построим матрицу предшествования грамматики
Матрица предшествования грамматики
|
|
; |
and |
:= |
or |
xor |
b |
( |
) |
not |
end |
|
; |
- |
- |
- |
- |
- |
- |
- |
- |
- |
> |
|
and |
> |
- |
- |
> |
> |
< |
< |
> |
< |
- |
|
:= |
> |
< |
- |
< |
< |
< |
< |
- |
< |
- |
|
or |
> |
< |
- |
> |
> |
< |
< |
> |
< |
- |
|
xor |
> |
< |
- |
> |
> |
< |
< |
> |
< |
- |
|
b |
> |
> |
< |
> |
> |
- |
< |
> |
- |
- |
|
( |
- |
< |
- |
< |
< |
< |
< |
= |
< |
- |
|
) |
> |
> |
- |
> |
> |
- |
- |
> |
- |
- |
|
not |
> |
> |
- |
> |
> |
- |
< |
> |
- |
- |
|
begin |
< |
- |
- |
- |
- |
< |
- |
- |
- |
- |
Алгоритм разбора цепочек грамматики операторного предшествования игнорирует нетерминальные символы. Поэтому преобразуем исходную грамматику таким образом, чтобы оставить в ней только один нетерминальный символ. Тогда получим следующий вид правил:
S → S;
S → b:=S
S → S or S
S → S xor S
S → S and S
S → (S)
S → not S
S → b
Листинг программы
Main.h
#ifndef MainH
#define MainH
#include <Classes.hpp>
#include <Controls.hpp>
#include <StdCtrls.hpp>
#include <Forms.hpp>
#include <Dialogs.hpp>
#include <ExtCtrls.hpp>
#include <Grids.hpp>
#include <ComCtrls.hpp>
class TLexTable
{
private:
char h(char ch)
{
if (ch=='n') return 'F';
if (ch=='o') return 'A';
if (ch=='x') return 'C';
if (ch=='a') return 'I';
if (ch==':') return 'P';
if (ch==' ') return 'h';
if (ch==';') return 'S';
if (ch=='(') return 'T';
if (ch==')') return 'U';
if ((ch=='0')||(ch=='1')) return 'L';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')) return 'O';
if (ch=='{') return 'M';
return 'e';
}
char A(char ch)
{
if (ch=='r') return 'B';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if (ch==' ') return 's';
return 'e';
}
char B(char ch)
{
if (ch==' ') return 's';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char C(char ch)
{
if (ch=='o') return 'D';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if (ch==' ') return 's';
return 'e';
}
char D(char ch)
{
if (ch=='r') return 'E';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if (ch==' ') return 's';
return 'e';
}
char E(char ch)
{
if (ch==' ') return 's';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char F(char ch)
{
if (ch=='o') return 'G';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if ((ch==' ')||(ch==';')) return 's';
return 'e';
}
char G(char ch)
{
if (ch=='t') return 'H';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if (ch==' ') return 's';
return 'e';
}
char H(char ch)
{
if (ch==' ') return 's';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char I(char ch)
{
if (ch==' ') return 's';
if (ch=='n') return 'J';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char J(char ch)
{
if (ch=='d') return 'K';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
if (ch==' ') return 's';
return 'e';
}
char K(char ch)
{
if (ch==' ') return 's';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char L(char ch)
{
if (ch==' ') return 's';
return 'e';
}
char M(char ch)
{
if (ch=='}') return 'N';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))||(ch==' ')) return 'M';
return 'e';
}
char N(char ch)
{
if (ch==' ') return 's';
return 'e';
}
char O(char ch)
{
if (ch==' ') return 's';
if (((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||(ch=='_')||((ch>='0')&&(ch<='9'))) return 'O';
return 'e';
}
char P(char ch)
{
if (ch=='=') return 'R';
return 'e';
}
char R(char ch)
{
if (ch==' ') return 's';
return 'e';
}
char S(char ch)
{
if (ch==' ') return 's';
return 'e';
}
char T(char ch)
{
if (ch==' ') return 's';
return 'e';
}
char U(char ch)
{
if (ch==' ') return 's';
return 's';
}
char e(char ch)
{
return 'e';
}
int intLex[250];
AnsiString ansiLex[250];
AnsiString ModString;
int Length;
public:
int ModLength;
TLexTable(AnsiString FileName)
{
FILE *f;
f = fopen(FileName.c_str(),"r");
char ch=' ';
char state='h';
int type = 0;
AnsiString lex="";
int i=0;
while (!feof(f))
{
fscanf(f,"%c",&ch);
if (ch=='\n') ch=' ';
switch (state){
case 's':
{
i++;
ansiLex[i] = lex.Trim();
intLex[i] = type;
lex="";
fpos_t filepos;
fgetpos(f,&filepos);
filepos--;
fsetpos(f,&filepos);
ch=' ';
state='h';
}break;
case 'h':state=h(ch);break;
case 'A':{
type = 1;
state=A(ch);
}break;
case 'B':{
type = 2;
state=B(ch);
}break;
case 'C':{
type = 1;
state=C(ch);
}break;
case 'D':{
type = 1;
state=D(ch);
}break;
case 'E':{
type = 3;
state=E(ch);
}break;
case 'F':{
type=1;
state=F(ch);
}break;
case 'G':{
type = 1;
state=G(ch);
}break;
case 'H':{
type = 4;
state=H(ch);
}break;
case 'I':{
type=1;
state=I(ch);
}break;
case 'J':{
type=1;
state=J(ch);
}break;
case 'K':{
type=5;
state=K(ch);
}break;
case 'L':{
type = 6;
state=L(ch);
}break;
case 'M':state=M(ch);break;
case 'N':{
type=7;
state=N(ch);
}break;
case 'O':{
type=1;
state=O(ch);
}break;
case 'P':state=P(ch);break;
case 'R':{
type=8;
state=R(ch);
}break;
case 'S':{
type=9;
state=S(ch);
}break;
case 'T':{
type=10;
state=T(ch);
}break;
case 'U':{
type=11;
state=U(ch);
}break;
case 'e':
{
i++;
ansiLex[i] = lex.Trim();
intLex[i] = 12;
lex="";
state=h(ch);
}break;
}
AnsiString t(ch);
lex+=t;
};
Length = i;
}
AnsiString *GetModLines()
{
AnsiString *ModLines;
ModLines = new AnsiString[Length+1];
int j=0;
for (int i=1;i<=Length;i++)
{
switch (intLex[i]){
case 1:{ModLines[j]="b"; j++;}break;
case 2:{ModLines[j]="or";j++;}break;
case 3:{ModLines[j]="xor";j++;}break;
case 4:{ModLines[j]="not";j++;}break;
case 5:{ModLines[j]="and";j++;}break;
case 6:{ModLines[j]="b";j++;}break;
case 8:{ModLines[j]=":=";j++;}break;
case 9:{ModLines[j]=";";j++;}break;
case 10:{ModLines[j]="(";j++;}break;
case 11:{ModLines[j]=")";j++;}break;
}
ModLength = j;
}
return ModLines;
}
void Output(TStringGrid *sgGrid)
{
sgGrid->RowCount = Length+1;
sgGrid->Cells[0][0] = "Лексема";
sgGrid->Cells[1][0] = "Тип лексемы";
for (int i=1;i<=Length;i++)
{
sgGrid->Cols[0]->Add(ansiLex[i]);
AnsiString tmp="";
switch (intLex[i]){
case 1:{tmp = "идентификатор";}break;
case 2:{tmp = "OR";}break;
case 3:{tmp = "XOR";}break;
case 4:{tmp = "NOT";}break;
case 5:{tmp = "AND";}break;
case 6:{tmp = "константа";}break;
case 7:{tmp = "комментарий";}break;
case 8:{tmp = "оператор приравнивания";}break;
case 9:{tmp = "точка с запятой";}break;
case 10:{tmp = "открывающая круглая скобка";}break;
case 11:{tmp = "закрывающая круглая скобка";}break;
case 12:{tmp = "ошибка";}break;
}
sgGrid->Cols[1]->Add(tmp);
}
}
};
class TfrmMain : public TForm
{
__published: // IDE-managed Components
TLabel *Label1;
TEdit *Edit1;
TButton *btnClose;
TTreeView *tree;
TMemo *mmInput;
void __fastcall btnCloseClick(TObject *Sender);
private: // User declarations
void AddTerminal(String);
void AddMatrix(FILE*,int);
int index_terminal(String);
int first_terminal(int);
int cmp_substr(String,String);
void sdvig(int,int);
int AddRules();
int cmp_rules(String,int);
int package(int,int);
void AddChild(String,int);
public: // User declarations
__fastcall TfrmMain(TComponent* Owner);
};
extern PACKAGE TfrmMain *frmMain;
#endif
Main.cpp
#include <vcl.h>
#include <stdio.h>
#pragma hdrstop
#include "Main.h"
#pragma package(smart_init)
#pragma resource "*.dfm"
TfrmMain *frmMain;
String *input_line;
String stack[256];
String terminal[32];
String rules[10];
String input_rules;
int **mega_matrix;
int all_rules=0;
__fastcall TfrmMain::TfrmMain(TComponent* Owner)
: TForm(Owner)
{
mmInput->Lines->LoadFromFile("input.txt");
TLexTable *LexTable;
LexTable = new TLexTable("input.txt");
input_line = LexTable->GetModLines();
input_line[LexTable->ModLength] = "end";
AddTerminal("precedence_matrix.txt");
all_rules = AddRules();
int count_stack;
stack[0] = "begin";
int stack_index = 0;
int lines_index = 0;
stack[0]="begin";
int cmp_rez;
int left;
int fl = 0;
while(1)
{
if((input_line[lines_index]=="end") && (stack[1]=="S") && (stack[2]=="")) break;
cmp_rez = cmp_substr(stack[first_terminal(stack_index)],input_line[lines_index]);
if(cmp_rez==1 || cmp_rez==0)
{
sdvig(stack_index,lines_index);
lines_index++;
stack_index++;
}
if(cmp_rez==2)
{
left = package(stack_index,all_rules);
if(left == -1) {fl=1; break; }
else stack_index= stack_index - left;
}
if(cmp_rez==-1) {fl=1; break; }
}
if (fl==1) {
Edit1->Text= "Неправильная конструкция";
}
else Edit1->Text=input_rules;
TTreeNode *Node1;
tree->Items->Clear();
tree->Items->Add(NULL, "S");
Node1 = tree->Items->Item[0];
for(int j = StrToInt(input_rules.Length()); j>0 ;j--)
{
int n = tree->Items->Count;
for (int i=n-1;i>=0 ;i--)
{
if(tree->Items->Item[i]->HasChildren == false)
if(tree->Items->Item[i]->Text =="S")
{
String t = rules[StrToInt(input_rules.SubString(j,1))];
AddChild(rules[StrToInt(input_rules.SubString(j,1))],i);
break;
}
}
}
}
void TfrmMain::AddTerminal(String filename)
{
FILE *input;
char *temp;
temp = new char[32];
input = fopen(filename.c_str(),"r");
int i=0;
while (strcmp(temp,"end"))
{
fscanf(input,"%s",temp);
terminal[i]=temp;
i++;
}
terminal[i]="#";
AddMatrix(input,i);
fclose(input);
}
void TfrmMain::AddMatrix(FILE *input,int n)
{
int i=0;
char *temp;
temp = new char [32];
mega_matrix = new int *[n];
for (int i = 0; i < n; i++)
mega_matrix[i] =new int[n];
while(!feof(input))
{
fscanf(input,"%s",temp);
for(int j=0;j<n;j++) {
fscanf(input,"%s",temp);
if(temp[0]=='<') mega_matrix[i][j] = 1;
if(temp[0]=='>') mega_matrix[i][j] = 2;
if(temp[0]=='=') mega_matrix[i][j] = 0;
if(temp[0]=='-') mega_matrix[i][j] = -1;
}
i++;
}
}
int TfrmMain:: index_terminal(String trm)
{
int count=0;
if(trm=="begin") trm = "end";
while(terminal[count]!="#") {
if(trm==terminal[count]) return count;
count++;
}
return -1;
}
int TfrmMain::first_terminal(int count)
{
for(int i=count;i!=0;i--)
{
if(index_terminal(stack[i])!=-1) return i;
}
}
int TfrmMain::cmp_substr(String sub1, String sub2)
{
if(index_terminal(sub1)>=0&&index_terminal(sub2)>=0)
return mega_matrix[index_terminal(sub1)][index_terminal(sub2)];
else return -1;
}
void TfrmMain::sdvig(int count_s,int count_l)
{
stack[count_s+1]=input_line[count_l];
}
int TfrmMain::AddRules()
{
char *temp = new char [32];
FILE *input = fopen("rules.txt","r");
int i=0;
while(!feof(input))
{
fgets(temp,256, input);
rules[i] = String(temp);
rules[i].SetLength(rules[i].Length()-1);
while(rules[i].Pos(" ")) {rules[i].Delete(rules[i].Pos(" "),1);}
i++;
}
return i;
}
int TfrmMain::cmp_rules(String rls,int n)
{
for(int i=0;i<n;i++)
{
if(rls==rules[i]) return i;
}
return -1;
}
int TfrmMain::package(int count_st,int n)
{
String trm,tV,Vt,VVt,V;
int ftrm = first_terminal(count_st);
trm = stack[ftrm];
tV = trm + stack[ftrm+1];
Vt = stack[ftrm-1] + trm;
V = stack[ftrm-1] + trm + stack[ftrm+1];
VVt = stack[ftrm-2]+ stack[ftrm-1]+trm;
if(cmp_rules(trm,n)>=0)
{
int rez = cmp_rules(trm,n);
stack[ftrm]="S";
input_rules+=IntToStr(rez);
return 0;
}
if(cmp_rules(tV,n)>=0)
{
int rez = cmp_rules(tV,n);
stack[ftrm]="S";
stack[ftrm+1]="";
input_rules+=IntToStr(rez);
return 1;
}
if(cmp_rules(Vt,n)>=0)
{
int rez = cmp_rules(Vt,n);
stack[ftrm-1]="S";
stack[ftrm]="";
input_rules+=IntToStr(rez);
return 1;
}
if(cmp_rules(V,n)>=0)
{
int rez = cmp_rules(V,n);
stack[ftrm-1]="S";
stack[ftrm]="";
stack[ftrm+1]="";
input_rules+=IntToStr(rez);
return 2;
}
if(cmp_rules(VVt,n)>=0)
{
int rez = cmp_rules(VVt,n);
stack[ftrm-2]="S";
stack[ftrm-1]="";
stack[ftrm]="";
input_rules+=IntToStr(rez);
return 2;
}
return -1;
}
void __fastcall TfrmMain::btnCloseClick(TObject *Sender)
{
Close();
}
void TfrmMain::AddChild(String child,int ind_item)
{
int lenght = child.Length();
char *rezult_child;
String temp_string="";
rezult_child = new char [lenght];
TTreeNode *Node1;
Node1 = tree->Items->Item[ind_item];
strcpy(rezult_child,child.c_str());
for(int i=0;i<lenght;i++)
{
temp_string = temp_string + rezult_child[i];
if(temp_string=="S")
{
tree->Items->AddChild(Node1,temp_string);
temp_string="";
}
if(index_terminal(temp_string)>=0)
{
tree->Items->AddChild(Node1,temp_string);
temp_string="";
}
}
}
Результаты работы
Входная цепочка: a := d and ( d xor not ( 0 and ( t or g ) ) ) ;
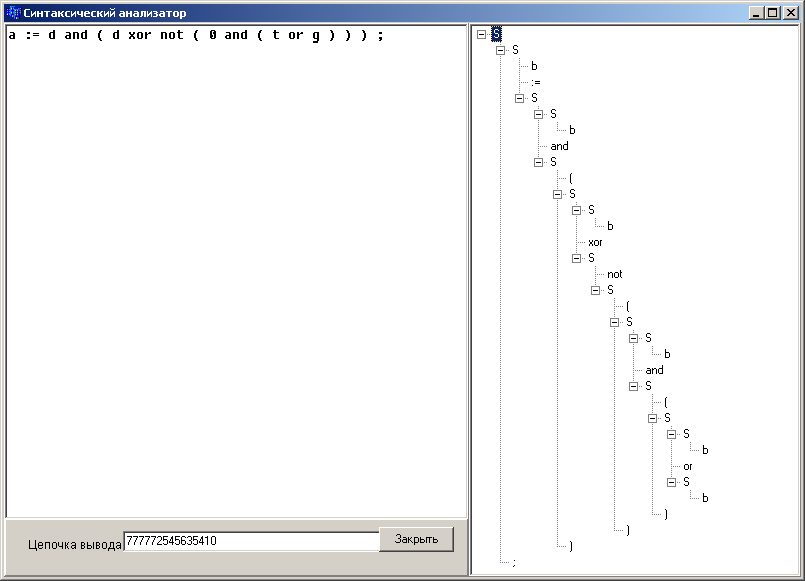
Вывод
В ходе лабораторной работы были изучены основные понятия грамматик простого и операторного предшествования, а также алгоритмы синтаксического анализа. Получены практические навыки создания простейшего синтаксического анализатора для заданной грамматики операторного предшествования.