

4.1. Методы организации хранения неструктурированных данных
Различают следующие методы хранения неструктурированных данных, организованных в виде файлов:
последовательные файлы,
цепочечные файлы,
инвертированные файлы,
кластерные файлы.
Совокупность файлов, содержащих текстовые данные, составляет полнотекстовую базу данных – ТБД, т.е. информационные массивы ИС.
4.1.1. Последовательные файлы
Файлы хранятся в произвольном порядке, например, в порядке их поступления. Не определены ни группы, ни классы файлов, нет справочников или других списков, обеспечивающих доступ к любому файлу.
Для нахождения всех файлов, обладающих некоторой характеристикой, требуется просмотр всего массива файлов. Неэффективность данного метода объясняет его практическое неиспользование.
Пусть, например, имеются тексты, которые хранятся в файлах с именами, соответственно, Ф1, Ф2, Ф3, Ф4, содержащие некоторые ключи Кi (на рисунке схематично показаны текстовые файлы, где в тексте среди слов содержатся ключевые слова):

Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1, например, компьютер. Тогда алгоритм поиска имеет вид:
из группы файлов выбирается первый файл Ф1 и соответствующий текст сканируется от начала – ищется совпадение слов текста с заданным ключевым словом;. Поскольку совпадение установлено, сканирование данного файла прекращается, пользователю выдается первый релевантный текст из файла Ф1;
из группы выбирается файл Ф2 и выполняется его сканирование от начала до конца. Совпадений нет, выполняется переход к анализу файла Ф3;
из группы файлов выбирается файл Ф3 и соответствующий текст сканируется. Выявляется совпадение, сканирование файла прекращается, и он выдается пользователю как второй релевантный текст. Выполняется переход к анализу файла Ф4;
из группы выбирается файл Ф4 и выполняется его сканирование от начала до конца. Совпадений нет, делается попытка перехода к анализу следующего файла, а поскольку все файлы просмотрены, алгоритм заканчивает работу.
Подобный метод организации хранения файлов и последующий поиск требуемых данных осуществляется в операционных системах семейства Windows и характеризуется большими временными затратами.
4.1.2. Цепочечные файлы
Файлы разделены на множества так, что все элементы одного множества отождествлены с помощью ключевого слова. По аналогии со структурированными данными можно говорить о подобии текстов, отождествленных с помощью одного ключа. Внутри каждого множества файлы соединены ссылками, а для доступа к первому элементу в цепочке организуются справочники - индексы. В роли ссылок могут выступать, в частности, полные имена файлов.
Пусть ТБД содержит те же файлы, что и в предыдущем примере. Индекс – это структурированный файл вида:
Ключевое слово |
Ссылка |
К1 |
Ф1 |
К2 |
Ф2 |
К3 |
Ф1 |
К4 |
Ф4 |
К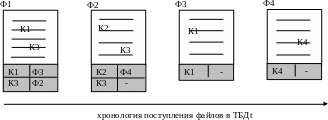 роме
того, претерпевают изменения и сами
файлы Ф1 – Ф4: они содержат описания
цепочек подобных файлов, размещенные,
например, в конце самих текстов (показаны
заливкой):
роме
того, претерпевают изменения и сами
файлы Ф1 – Ф4: они содержат описания
цепочек подобных файлов, размещенные,
например, в конце самих текстов (показаны
заливкой):
Из рисунка видно, что структура этих описаний соответствует структуре самого индекса: первое поле – это ключевое слово, а второе – ссылка на файл, следующий в цепочке подобных текстов.
Рассмотрим, как решается задача поиска релевантного текста при такой организации.
Пусть запрос по-прежнему содержит ключевое слово К1. Тогда алгоритм просмотра имеет вид:
по индексу определяется элемент со значением ключевого слова К1;
по полю ссылки находится имя файла, первого в цепочке файлов, содержащих данное слово – это Ф1; выводится содержимое данного файла;
по полю ссылки для ключевого слова К1 файла Ф1 определяется имя файла, следующего в цепочке ключевого слова К1, – это Ф3;
выводится содержимое файла Ф3;
по полю ссылки для ключевого слова файла Ф3 определяется имя файла, следующего в цепочке ключевого слова К1. Поскольку ссылка пуста, цепочка закончена, и алгоритм прекращает работу.