

4.4. Алгоритми планування
Як ми вже знаємо, алгоритм планування дає змогу короткотерміновому планувальникові вибирати з готових до виконання потоків той, котрий потрібно виконувати наступним. Можна сказати, що алгоритми планування реалізують політику планування.
Залежно від стратегії планування, яку реалізують алгоритми, їх поділяють на витісняльні та невитісняльні. Витісняльні алгоритми переривають потоки під час їхнього виконання, невитісняльні — не переривають. Деякі алгоритми відповідають лише одній із цих стратегій, інші можуть мати як витісняльний, так і невитіс-няльний варіанти реалізації.
4.4.1. Планування за принципом fifo
Розглянемо найпростіший («наївний») невитісняльний алгоритм, у якому потоки ставлять на виконання в порядку їхньої появи у системі й виконують до переходу в стан очікування, явної передачі керування або завершення. Чергу готових потоків при цьому організовують за принципом FIFO, тому алгоритм називають алгоритмом FIFO.
Як тільки в системі створюється новий потік, його керуючий блок додається у хвіст черги. Коли процесор звільняється, його надають потоку з голови черги. У такого алгоритму багато недоліків:
він за визначенням є невитісняльним;
середній час відгуку для нього може бути доволі значним (наприклад, якщо першим надійде потік із довгим інтервалом використання процесора, інші потоки чекатимуть, навіть якщо вони самі використовують тільки короткі інтервали);
він підлягає ефекту конвою (convoy effect).
Ефект конвою можна пояснити такою ситуацією. Припустимо, що в системі є один потік (назвемо його Тсри), обмежений можливостями процесора, і багато потоків Tcpu, обмежених можливостями введення-виведення. Рано чи пізно потік Гсри отримає процесор у своє розпорядження і виконуватиме інструкції з довгим інтервалом використання процесора. За цей час інші потоки Тіо завершать введення-виведення, перемістяться в чергу готових потоків і там чекатимуть, при цьому пристрої введення-виведення простоюватимуть. Коли Гсрц нарешті заблокують і відбудеться передача керування, всі потоки Гіо швидко виконають інструкції своїх інтервалів використання процесора (у них, як ми знаємо, такі інтервали короткі) і знову перейдуть до введення-виведення. Після цього Гсри знову захопить процесор на тривалий час і т. д.
4.4.2. Кругове планування
Найпростішим для розуміння і найсправедливішим витісняльним алгоритмом є алгоритм кругового планування (round-robin scheduling). У середні віки терміном «round robin» називали петиції, де підписи йдуть по колу, щоб не можна було дізнатися, хто підписався першим (ця назва свідчить, що для такого алгоритму всі потоки рівні).
Кожному потокові виділяють інтервал часу, який називають квантом часу (time quantum, time slice) і упродовж якого цьому потокові дозволено виконуватися. Коли потік усе ще виконується після вичерпання кванта часу, його переривають і перемикають процесор на виконання інструкцій іншого потоку. Коли він блокується або закінчує своє виконання до вичерпання кванта часу, процесор теж передають іншому потокові. Довжина кванта часу для всієї системи однакова.
Такий алгоритм реалізувати досить легко. Для цього черга готових потоків має бути циклічним списком. Коли потік вичерпав свій квант часу, його переміщують у кінець списку, туди ж додають і нові потоки (рис. 4.3). Перевірку вичерпання кванта часу виконують в обробнику переривання від системного таймера.
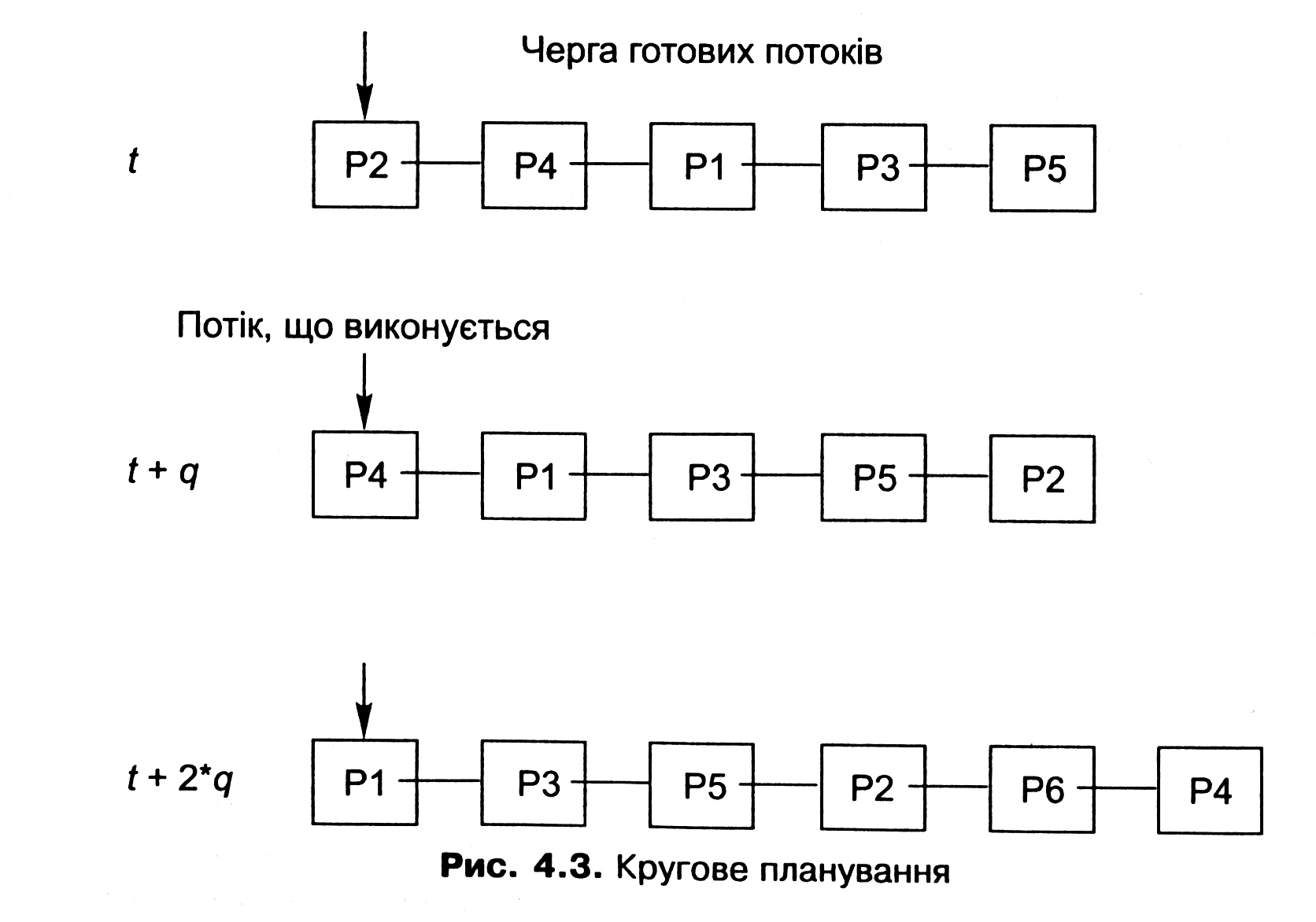
Єдиною характеристикою, яка впливає на роботу алгоритму, є довжина кванта часу. Тут слід дотримуватися балансу між часом, що витрачається на перемикання контексту, і необхідністю відповідати на багато одночасних інтерактивних запитів.
Задания надто короткого кванта часу призводить до того, що відбувається дуже багато перемикань контексту, і значний відсоток процесорного часу витрачається не на корисну роботу, а на ці перемикання. З іншого боку, задания надто довгого кванта хоча й заощаджує процесорний час, але спричиняє до зниження часу відгуку на інтерактивні запити, бо якщо десять користувачів одночасно натиснуть клавішу, то десять потоків потраплять у список готових, внаслідок чого останній з них очікуватиме десять довгих квантів часу. У випадку з квантом нескінченної довжини кругове планування зводиться до алгоритму FIFO (усі потоки встигають заблокуватися або закінчитися до вичерпання кванта). На практиці рекомендують встановлювати довжину кванта в 10-100 мс.
Зазначимо, що традиційне кругове планування може давати «перекіс» у бік потоків, обмежених можливостями процесора. Такі потоки переважно використовують свій квант повністю, тоді як потоки, обмежені можливостями введення-виведення, часто передають керування до вичерпання кванта, і в результаті їм дістається менше процесорного часу. Для вирішення цієї проблеми можна збільшувати довжину кванта (з огляду на проблеми, описані раніше) або вводити додаткову чергу потоків, що завершили введення-виведення, яка має перевагу на виконання перед чергою готових потоків.