

125 Кібербезпека / 4 Курс / 3.1_3.2_4.1_Захист інформації в інформаційно-комунікаційних системах / Лiтература / [Sumeet_Dua,_Xian_Du]_Data_Mining_and_Machine_Lear(BookZZ.org)
.pdf58 Data Mining and Machine Learning in Cybersecurity
of cyber attacks, identifying which system vulnerabilities have been used in known attacks and determining what actions cyber administrators should take to defend against such attacks. Moreover, execution signatures vary substantially from one attack category to another, so that specific detection methods are required to classify attack patterns and, thus, to improve detection capability. Researchers have proposed many machine-learning algorithms for misuse detection systems. Reported results show that there is a great berth of room for improvement in detection performance.
In this chapter, we introduce fundamental knowledge, key issues, and challenges in misuse/signature detection systems, such as building efficient rule-based algorithms, feature selection for rule matching and accuracy improvement, and supervised machine-learning classification of attack patterns. First, we present a detailed description of the basic techniques and applications of several representative supervised machine-learning classifiers in a misuse detection system, such as association rules, fuzzy-rule-based method, artificial neural network (ANN), support vector machine (SVM), and genetic programming (GP). Second, we explore the machine-learning methods for feature selection. Such methods include decision trees, classification and regression tree (CART), and Bayesian network (BN). Third, we briefly analyze and discuss the accuracies of these techniques along with other machine-learning algorithms (maximum likelihood Gaussian classifiers, incremental radial basis function, fuzzy adaptive resonance theory mapping, and k-nearest neighbor [KNN]) for misuse detection. We explore the limitations and difficulties of using these machine-learning methods in misuse detection systems and outline possible problems such as inadequate ability to detect a novel attack, irregular performance for different attack types, and requirements of the intelligent feature selection. We will guide readers to learn more about the use of advanced machine-learning techniques to solve these problems.
3.1 Misuse/Signature Detection
Misuse detection, also called signature detection, is used to recognize specifically unique patterns of unauthorized behavior to predict and detect subsequent similar attempts. These specific patterns, called signatures, include patterns of specific log files or packets that have been identified as a threat. Each file is composed of signatures, which are unique arrangements of zeros and ones. For example, in a hostbased intrusion detection system (IDS), a signature can be a pattern of system calls. In a network-based IDS, a signature can be a specific pattern of the packet such as packet content signatures and/or header content signatures that can indicate unauthorized actions such as improper FTP initiation. The packet includes source or destination IP addresses, source or destination TCP/UDP ports, and IP protocols such as UDP, TCP, and ICMP, and data payloads.
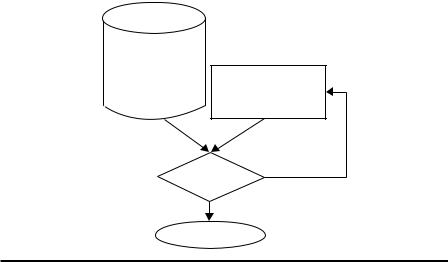
As shown in Figure 3.1, misuse/signature detection methods match the learned patterns and signature of attacks to identify malicious users. If the learned patterns
Supervised Learning for Misuse/Signature Detection 59
Signature |
|
|
of attacks |
Learned patterns |
|
(Login name = |
||
(Login name = |
||
‘Sadan’) |
||
‘Sadan’) |
||
|
No
Match?
Yes
Abnormal!
Figure 3.1 Misuse detection using “if–then” rules.
and signature of attacks match, the system will alert the system administrator that a cyber attack has been detected. Then, the administrator will attempt to label the attack. The related information will be delivered to an administrator. For example (see Figure 3.1), if we have an attack signature as “Login name = ‘Sadan’,” then, when any data matches this signature, the system will alert the administrator that anomalous events have been detected.
Signature detection methods typically search for known potentially malicious information by scanning cyberinfrastructure and, thus, make decisions based on a significant amount of prior knowledge of the attack signatures. For these solutions to work, the security software will need to obtain collections of known cyber attack characteristics. Therefore, the quality and reliability of the signature detection results rely on the frequent updating of the signature database. For example, antispyware tools usually use signature detection techniques to find malicious software embedded in a computational system. When a signature-based antispyware tool is active, it scans files and programs in the system and compares them with the signatures in the database. If there is a match, the tool will alert the system administrator that spyware has been detected and will provide information associated with the spyware, such as the name of the software, the danger level, and the location of the spyware, to cyber administrators.
This technique often locates known threats. However, this technique may cause false alarms. A false alarm is an instance in which an alert occurs although unauthorized access has not been attempted. For example, a user may forget a login password and make multiple attempts to sign into an account. Most site accounts lock for 24 h after three failed login attempts. Attempts after this point can be regarded as attacks. Depending on the robustness and seriousness of a triggered signature, an alarm or notification will be reported to the proper authorities.
60 Data Mining and Machine Learning in Cybersecurity
The strength of a misuse/signature detection system depends on the sufficiency of the knowledge of the system vulnerabilities and known attack patterns. Traditionally, the construction of the knowledge of a cyberinfrastructure relies heavily on domain experts. Domain experts vary in experience and knowledge, which leads to the incomplete coverage and inaccurate detection of malicious behaviors. Moreover, any variation, evolution, or blending of known attacks can challenge the similarity learning process.
3.2 Machine Learning in Misuse/Signature Detection
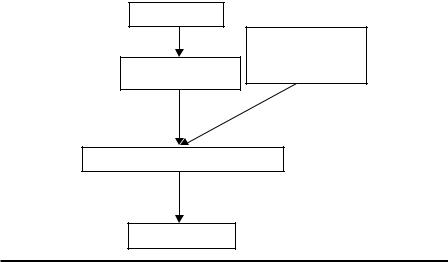
As shown in Figure 3.2, a typical misuse/signature detection system consists of five steps: information collection, data preprocessing, misuse/signature identification by matching methods, rules regeneration, and denial of service (DoS) or other security response. The data resources include cyber attribute data such as audit log, network packet flow, and windows registry. Data preprocessing prepares input data for pattern learning by reducing noises and normalizing, selecting, and extracting features. Once these steps have been performed, domain experts or automatic intelligent learning systems build intrusive learning models, such as rule-based expert systems, based on prior knowledge of malicious code and data and vulnerabilities in cyberinfrastructures. Then, we can apply the learned classification models or rules to the incoming data for misuse pattern detection. If any cyber information is found to be similar to the attack patterns in an apriori rule, then decisions will be made automatically by software or manually by cyber administrators after further
Data source |
|
|
Intrusion learning |
|
model (e.g., rules |
Data preprocessing |
generation) |
|
|
Activities |
Intrusion signatures |
|
Pattern matching and intrusion detection
Defense response
Figure 3.2 Workflow of misuse/signature detection system.
Supervised Learning for Misuse/Signature Detection 61
analysis. Consequently, misuse/signature detection can be simply understood as an “if–then” sequence as shown in Figure 3.1.
Machine-learning methods play several core roles in misuse detection systems. These approaches can provide feature selection in the data preprocessing step and help build rules or perform pattern classification and recognition in signature identifications. As shown in Figure 3.2, machine-learning algorithms can improve pattern matching and intrusion detection by intelligently comparing the misuse/signature patterns with the collected cyber information. As the training data for the buildup of rules or other machine-learning models are labeled as normal, anomalous, or as specific attack types, most of the machine-learning methods employed in misuse detection systems are supervised. Subsequently, these detection techniques rely on the similarity measure between input events and the signatures of known intrusions. They flag the event that is close to a predefined pattern of intrusion. Thus, known attacks can be detected immediately and realizably with a lower false-positive rate. However, signature detection is ineffective for detecting novel attacks.
3.3Machine-Learning Applications in Misuse Detection
In this section, we present a variety of misuse techniques that are based on machinelearning methods. We have listed some examples of machine-learning methods applied in misuse detection systems in Table 1.2. Below, we introduce the fundamental techniques of rule-based classifiers, GP, decision tree, and BN. We also discuss the application of these methods, ANN, and SVM in misuse detection system along with examples. We begin with rule-based signature analysis.
3.3.1 Rule-Based Signature Analysis
Many misuse-detection techniques frequently utilize some form of rule-based analysis. Rules describe the correlation between attribute conditions and class labels. When applied to misuse detection, the rules become descriptive scenarios for network attacks. The intrusion detection mechanism identifies a potential attack if a user’s activities are found to be consistent with the established rules for detecting a threat. The use of comprehensive rules is critical in the application of expert systems for intrusion detection. Below, we present the fundamentals of associative rules classification and associative rules classification application in misuse detection. In Section 3.3.1.1, we introduce associative classification and association rules. We discuss the application of association rules in misuse detection. In Section 3.3.1.2, we extend the above technique to fuzzy-rule-based classification.
62 Data Mining and Machine Learning in Cybersecurity
3.3.1.1 Classification Using Association Rules
Agrawal et al. (1993) introduced association rules to capture and represent causal relationships among attributes in a multidimensional database. Association rules classification describes the frequent patterns in a data set, e.g., computer and antivirus software that appear frequently together in a transaction data set.
For example, let us assume that an association rule from the shell command history file of a user, which is a stream of commands and their arguments, is trn → rec.humor, [0.3, 0.1]. This association rule indicates that 30% of the time when the user invokes trn, he or she is reading the news in rec.humor, and reading this newsgroup accounts for 10% of the activities recorded in his or her command history file. If minimum support is 0.25 and minimum confidence is 0.25, we can say that this rule is strong.
Association rules are generated in two steps. First, we find all frequent itemsets and identify the strong association rules in the frequent itemsets. Mining frequent itemsets from a large data set is challenging, because it generates a large number of itemsets, which satisfy the minimum support threshold, and if any itemset is frequent, its subset should also be frequent. Researchers have proposed many efficient algorithms for association rule mining. Among these methods, an apriori algorithm introduced by Agrawal et al. in 1993 is the most commonly used frequent association rule mining algorithm. This algorithm uses support and confidence measures of interestingness and improves rule mining efficiency by using the prior knowledge of frequent itemset properties that all nonempty subsets of a frequent itemset must also be frequent. Subsequently, the apriori algorithm consists of the following steps.
Step 1. Find all length 1 itemsets that satisfy the minimum support threshold. Step 2. Iteratively generate sets of candidate length k itemsets by combining
two length k − 1 frequent itemsets. Prune the infrequent length k candidate itemsets that include any infrequent length k − 1 subsets. Find all length k itemsets among the candidate pool, which satisfy the minimum support threshold.
Step 3. Generate all nonempty subsets for each of the frequent itemsets generated in Step 2.
Step 4. For each nonempty subset generated in Step 3, output the corresponding rules for the frequent itemsets that satisfy minimum confidence.
Application Study 1: Application of Association Rules in Audit Data for Misuse Detection
In this study, we demonstrate the application of association rules as a misuse detection technique. The following is an example, based on host-based record data, of one telnet session recorded by a mid-size company server (shown in Table 3.1). There are 15 transactions in this database. Using the apriori algorithm, we can obtain the association rules, which are extracted between items of time, hostname, command,
Supervised Learning for Misuse/Signature Detection 63
Table 3.1 Example of Shell Command Data
Time |
Hostname |
Command |
Arg |
|
|
|
|
am |
Bluedawg |
cd |
home |
|
|
|
|
am |
Bluedawg |
vi |
tex |
|
|
|
|
am |
Bluedawg |
boss |
|
|
|
|
|
am |
Bluedawg |
subject |
conference |
|
|
|
|
am |
Bluedawg |
vi |
tex |
|
|
|
|
am |
Bluedawg |
boss |
|
|
|
|
|
am |
Bluedawg |
subject |
progress |
|
|
|
|
am |
Bluedawg |
cd |
work |
|
|
|
|
am |
Bluedawg |
vi |
tex |
|
|
|
|
am |
Bluedawg |
hotel |
|
|
|
|
|
am |
Bluedawg |
subject |
travel |
|
|
|
|
am |
Bluedawg |
vi |
tex |
|
|
|
|
am |
Bluedawg |
boss |
|
|
|
|
|
am |
Bluedawg |
subject |
plan |
|
|
|
|
am |
Bluedawg |
logout |
|
|
|
|
|
and arg. Since the basic apriori algorithm does not consider domain knowledge, its application results in a large number of irrelevant rules. Given prior knowledge, we can reduce redundant rules in postprocessing or use item constraints over attribute values. For example, in our case study, Lee et al. (1999) proposed to use association rules and frequent episodes computed from audit data to guide further audit data gathering and feature selection. They then modified two algorithms using axis and reference attributes as item constraints to compute only the relevant patterns. In addition, an iterative approximate mining procedure was applied across each level to uncover the low frequency, important patterns. In Table 3.2, we list two interesting rules that we generated using the shell command records in Table 3.1.
We recommend readers find the detailed description of these methods in Lee et al. (1999).
Application Study 2: Application of Association Rules in Network Traffic Data for Misuse Detection
In Lee et al. (1999), the authors presented an example of network traffic data at a company. The association rules were extracted between items of label, service,
64 Data Mining and Machine Learning in Cybersecurity
Table 3.2 Examples of Association Rules for Shell Command Data
Association Rules |
Meaning |
|
|
|
|
Command = vi time = am |
When using vi to edit a file, the user |
|
|
is always editing a tex file, in the |
|
Host = Bluedawg |
||
morning and at host Bluedawg and |
||
|
||
Arg = tex |
25% of the data has this pattern. |
|
|
||
|
|
|
(confident = 1.0, support = 0.25) |
|
|
|
|
|
Command = vi time = am |
The mail is 75% sent to boss, in the |
|
|
morning and at host Bluedawg and |
|
Host = Bluedawg |
||
19% of the data has this pattern. |
||
|
||
Arg = boss |
|
|
|
|
|
(support = 0.25, confident = 0.75) |
|
|
|
|
Table 3.3 Example of “Traffic” Connection Records
|
|
host_ |
srv_ |
host_ |
host_diff_ |
|
Label |
Service |
count |
count |
REJ_% |
srv_% |
… |
|
|
|
|
|
|
|
Normal |
ecr_i |
1 |
1 |
0 |
1 |
… |
|
|
|
|
|
|
|
DOS |
ecr_i |
350 |
350 |
0 |
0 |
… |
|
|
|
|
|
|
|
PROBING |
User-level |
231 |
1 |
85 |
89 |
… |
|
|
|
|
|
|
|
Normal |
http |
1 |
0 |
0 |
1 |
… |
|
|
|
|
|
|
|
… |
… |
… |
… |
… |
… |
… |
|
|
|
|
|
|
|
Source: Lee, W.K. et al., A data mining framework for building intrusion detection models, in: Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, 1999, pp. 120–132. © [1999] IEEE.
host_count, srv_count, host_REJ_%, and host_diff_srv_% as shown in Table 3.3. The following were two association rules for DOS and PROBING attacks:
{service = ecr_i,host _ count ≥ 5,host _ srv_count ≥ 5 DOS},
and
{host_REJ% ≥ 83%,host_diff_srv% ≥ 87% PROBING}.
The first rule refers to the transactions that occur when icmp echo request service is called, and the connections over the past two seconds on the same destination
Supervised Learning for Misuse/Signature Detection 65
host with the same service provider as the current information source are equal to or more than five. The connection for these transactions was labeled a DOS attack.
The second rule refers to the transactions that occur on the same destination host when the rejected connections over the past two seconds account for not less than 83%, and the different services account for not less than 87%. The connection for these transactions was labeled a PROBING attack.
3.3.1.2 Fuzzy-Rule-Based
The rule-based misuse detection system can be outwitted by a slight variance in attacks, which can cause mismatches between anomalous data and signatures. This mismatch is due to the hard cutoff in the rules generated by experts or intelligent systems. Human experts can update rules after new attacks are detected and identified. However, the reliance on human expertise can lead to uncertain reasoning in a noisy and changing cyberinfrastructure environment. To generate human-like expertise in machine learning and the decision-making process, researchers have developed fuzzy-rule-based systems to exploit the tolerance for handling and manipulating uncertainty, robustness, and partial truth to achieve tractability. The most difficult task in building a fuzzy classification system is to find a set of fuzzy rules pertaining to the specific classification problem that you are trying to solve.
As discussed above, a rule-based system classifies the membership of data points in a binary term: a data point belongs to either a normal or an anomalous data set (or in a multiset system, a data point that has to fall into one and only one set). We can indicate the membership of any data point in a set by {0, 1}. In fuzzy set theory, the membership of any data point in a set is described by a value in the range [0.0, 1.0], with 0.0 representing absolute falseness and 1.0 representing absolute truth.
Given a set of data points X = {x} and a fuzzy set A, the membership of each data point x A can be denoted by a membership function m as f(x), where A is a fuzzy set and f: A → [0, 1]. For each data set, x A, f(x) is the weight of membership of x. In particular, an element mapping to the value 0 means that the member is not included in the fuzzy set, while 1 describes a fully included member. Values strictly between 0 and 1 characterize the fuzzy members. The set {x A|m(x) > 0} is called the support of the fuzzy set (A,m).
A fuzzy system is characterized by a set of linguistic statements based on expert knowledge. For example, a rule is in the form of “if: antecedent–then: consequent,” e.g., rule: if (src_ip == dst_ip) then “land attack.” Correspondingly, a fuzzy rule is presented in the form of “if: antecedent–then: consequent [weight],” e.g., if (src_ip == dst_ip) then “land attack” [0.6]. We present this rule as
FZ(rule) = FO(src _ ip = = dst _ ip) 0.6,

66 Data Mining and Machine Learning in Cybersecurity
where FO(src_ip = = dst_ip) justifies and evaluates the input (src_ip, dst_ip) using a fuzzy operator function FO.* Then, the above result is applied to the consequent “land attack” by assigning the weight of the rule through the fuzzy membership function.
Given the data set X = {xi}, i = 1, …, n in d-dimensional feature space, we denote
each data point xi as xi |
= (xi1, …, xid). Then, the pattern space can be represented as |
||
unit cube [0, 1]d and xi |
[0, 1]d. In Abraham et al. (2007a), each feature dimension |
||
is partitioned into K grids with interval [αk−1, αk] denoting the kth interval and |
|||
α0 = 0, αK = 1. Correspondingly, the 0.5-level set of the membership function hk(·), |
|||
k = 1, …, K is defined with αk = (1/(K − 1))(k − 0.5). Given C classes in a data set, |
|||
mc (xi ) = |
1 |
∑xi c |
hk (xij ) for xij [αk−1, αk] represents the membership weight |
n |
|||
|
c |
j {1,…,d } |
|
of data point xi in class c, c {1, …, C}, where nc denotes the number of data points classified in class c. Subsequently, a single fuzzy rule for class c can be presented as the following,
Rc : if xi1 is A1c and xi 2 is A2c and xid is Adc , then the class c.
In the above, Aic denotes the antecedent fuzzy set of ith rule for the ith feature. The membership function of Aic is defined as
c |
|
xi − uic 2 |
|
|||
Ai |
(xi ) = exp |
− |
|
|
, |
(3.1) |
c |
||||||
|
|
|
2σi |
|
|
|
where uic and σic are the mean of the ith feature values of the data points in class c. A drawback to the above approach is that the number of possible fuzzy if–then rules exponentially increases with dimensionality of feature space. Another problem with this approach is that it uses fuzzy if–then rules with certainty grades without using any local information about training patterns in the corresponding
fuzzy subspace. To solve these problems, the following fuzzy rules can be used:
Rc : if xi1 is A1c and xi2 is A2c and … xid is Adc , then the class c,
with CF = CFc , c {1,…,C}.
In the above, CFc is the grade of certainty for class c.
To achieve the consequent class and grade of certainty for each of these classes, we employ the following heuristic steps.
Step 1. For each training data point, xi = (xi1,…, xid), calculate the joint antecedent fuzzy set of the qth rule as
Πq (xi ) = Aq1 (xi1 ) × × Aqd (xid ), q = 1, …, n.
* For example, the fuzzy operator function of logic function “A and B” is min{A,B}.
Supervised Learning for Misuse/Signature Detection 67
Step 2. For each class c {1, …, C}, calculate the sum of the grades of the training data points in class c with the qth fuzzy rule R with the qth fuzzy rule Rq as
βc (Rq ) = ∑Πq (xi ). |
(3.2) |
|||||||||
|
|
|
xq c |
|
|
|
|
|
|
|
Step 3. Seek the class that has the maximum value calculated in Step 2. |
|
|||||||||
βc* (Rq ) = max {βc (Rq )}, |
c {1, …, C}. |
(3.3) |
||||||||
Step 4. Calculate the grade of certainty as following: |
|
|||||||||
|
|
|
βc* (Rq ) − |
|
|
|
|
|
||
CFq = |
β |
, |
(3.4) |
|||||||
∑ |
C |
|
|
|
|
|||||
|
|
|
βc (Rq ) |
|
|
|||||
|
|
|
|
c =1 |
|
|
|
|
|
|
|
|
|
|
βc (Rq ) |
|
|
||||
β = ∑ |
|
|
||||||||
|
. |
|
(3.5) |
|||||||
(C −1) |
|
|||||||||
|
|
|
c ≠c * |
|
|
|
|
|
|
|
Application Study 3: Application of Fuzzy Rules in 1998 DARPA Intrusion Detection Data Sets for Misuse Detection
Abraham et al. applied fuzzy rules in 1998 DARPA intrusion detection data sets for misuse detection in (Abraham et al., 2007b). Forty-one features were extracted for each connection record, including 24 attack types, which also were categorized into four groups: DoS, remote to user attack (R2L), user to root (U2R), and probes. Thus, five classes are defined in the data set: normal, DoS, R2L, U2R, and probes.
Three phases were included in the experiments: feature selection, training, and testing. In the feature selection phase, 12 important attributes were selected for real-time intrusion detection using the decision-tree method. In the training phase, data were normalized to (0,1). Then, the grade of certainty was learned, so that the grade of certainty was increased if an attack was classified correctly, and when an attack was classified inaccurately, the grade of certainty was decreased. Triangular membership functions were used for all fuzzy-rule-based classifiers. Abraham et al. introduced three fuzzy-rule-based classifiers and compared the experimental performance with the results obtained using linear genetic program (LGP), SVM, and decision tree. Furthermore, they modeled a fuzzy ensemble IDS as a combination of classifiers to model lightweight and more accurate (heavyweight) IDS.