

r-value и l-value
l-value (“Обозначает объект” адрес переменной в памяти)
r-value (значение этой переменной)
Соответственно, существует правило:
Lvalue=rvalue. То есть на первое место в равенстве всегда ставится адрес переменной, а на второе её значение.
lvalue/rvalue является свойством не объектов и/или функций, а выражений:
char a [10];
++i lvalue
*&i lvalue
a[5] lvalue
a[[i] lvalue
однако:
i + 1 rvalue
i++ rvalue
Очевидно, что, если мы будем использовать любое из приведенных выражений в контексте, требующем значения, например, в правой части операции присваивания, использование адресов будет ошибкой. Т.е., хотя выражение i является lvalue ("адрес"), компилятор должен использовать соответствующее rvalue ("значение"). В терминах стандарта C++ это называется преобразованием из lvalue к rvalue (lvalue-to-rvalue conversion).
Для некоторых простых языков критерием того, является ли данное выражение e lvalue, может служить возможность помещения этого выражения по левую сторону от знака присваивания, т.е. "e = . . .". Однако, для C++ этот критерий "не работает". Например, для rvalues классов можно вызывать функции члены. Поэтому, вполне возможно, что, несмотря на то, что выражение С() является rvalue (если C — имя класса), оно вполне может находиться слева от '='. С другой стороны, несмотря на то, что выражения, состоящее только из имени массива или функции, являются lvalue, они не могут стоять по левую сторону от '='.
Кроме того, ситуацию дополнительно осложняет наличие non-modifiable lvalues, например, если t определена как "const int t;", выражение t является non-modifiable lvalue, т.е. объект, который нельзя модифицировать.
Одним из чуть более успешно "работающих" критериев для C++ может служить возможность применения к выражению операции взятия адреса, т.е. "&e". В частности, этот критерий "срабатывает" правильно для временных объектов и non-modifiable lvalues. Однако, и здесь не все гладко: если в классе C переопределена операция взятия адреса (operator &) и при этом она помещена в секцию private, к выражению c, являющемуся lvalue, если c — имя переменной типа C, операция & будет неприменима. И наоборот: если операция & определена в секции public, к выражению C(), являющемуся rvalue, можно будет применять операцию &.
Таким образом, единственно верным руководством к определению того, является ли данное выражение языка C++ lvalue или rvalue может служить только стандарт. В некоторой степени положение упрощается за счет того, что для большинства случаев соответствующие правила легко запомнить:
Имя переменной — lvalue (non-modifiable, если переменная const); может быть преобразовано к rvalue того же типа.
Имя переменной-ссылки — lvalue.
Результат операции взятия адреса (&) — rvalue типа указатель.
Результат операции разыменования (*) — lvalue указуемого типа.
Имя функции — (non-modifiable) lvalue; может быть преобразовано к rvalue "указатель на функцию".
Имя массива — (non-modifiable) lvalue; может быть преобразовано к rvalue "указатель на первый элемент массива".
Выражения, результатом которых является временная переменная — rvalue. Например, результат вызова функции int f(), операции +, -. *, / ... для встроенных типов, явное создание временной переменной int() или C(), преобразования не к ссылочным типам и т.п.
Результат функции, возвращающей ссылку, или операции преобразования к ссылочному типу — lvalue.
POD-типы
POD-типы я зыке С++ расшифровываются как «Plain Old Data», что можно трактовать как простые данные стиле С
ЗЩ
POD-типы
Все встроенные арифметические типы (включая wchar_t и bool)
Перечисления, т.е. типы, объявленные при помощи ключевого слова enum
Указатели
POD-структуры (структуры простых данных в стиле С)
Чтобы структура была POD-типом она должна удовлетворять следующим требованиям:
Не иметь пользовательских конструкторов, деструктора или копирующего оператора присваивания;
Не иметь базовых классов;
Не иметь виртуальных функций;
Не иметь защищенных (protected) или закрытых (private) нестатических членов данных
Не иметь нестатических членов данных не POD-типов (или массивов таких типов), а также ссылок
Копирующий оператор присваивания –это такой нешаблонный нестатический operator=, у которого есть строго один параметр типа Х, X&, const X& и др., где Х-тип рассматриваемой структуры и\или объединения.
Абстрактный класс.
Абстрактный класс в объектно-ориентированном программировании — базовый класс, который не предполагает создания экземпляров. Абстрактные классы реализуют на практике один из принципов ООП - полиморфизм. Абстрактный класс может содержать (и не содержать) абстрактные методы и свойства. Абстрактный метод не реализуется для класса, в котором описан, однако должен быть реализован для его неабстрактных потомков. Абстрактные классы представляют собой наиболее общие абстракции, то есть имеющие наибольший объем и наименьшее содержание.
На языке программирования C++ абстрактный класс объявляется включением хотя бы одной чистой виртуальной функции, типа virtual _сигнатура_функции_ =0;, которая как и другие может быть заменена
Адаптирующие итераторы
Итератор –это обобщение понятия указателя для работы со структурами данных стандартным способом. Итераторы
Итераторы — это объекты, которые ведут себя более или менее подобно указателям.
Они предоставляют возможность выполнять циклическую обработку элементов контей-
нера — подобно тому, как вы используете указатель для организации цикла по массиву.
Существует пять типов итераторов.Р а б о т а с к о н т е й н е р а м и S T L 1 0 9
Итератор Тип доступа
Произвольного доступа Сохраняет и извлекает значения. Доступ к элементам — в произвольном порядке
Двунаправленный Сохраняет и извлекает значения. Допускает перемещение вперед и назад
Прямой Сохраняет и извлекает значения. Перемещение только вперед.
Входной Извлекает, но не сохраняет значения. Перемещение только вперед
Выходной Сохраняет, но не извлекает значения. Перемещение только вперед
Вообще итератор, имеющий более широкие возможности доступа, может применять-
ся вместо итератора с меньшими возможностями. Например, прямой итератор может
быть использован вместо входного итератора.
Итераторы обрабатываются подобно указателям. Обратные итераторы либо двуна-
правлены, либо произвольного доступа, которые перемещаются по последовательности
в обратном направлении. Таким образом, если обратный итератор указывает на конец по-
следовательности, то увеличение этого итератора на единицу переместит его на элемент,
предшествующий конечному.
Все итераторы должны поддерживать типы операций с указателями, допустимые для
их категории. Например, класс входного итератора должен поддерживать операции ->,
++, *, == и !=. Более того, операция * не может использоваться для присваивания зна-
чения. В отличие от входного, итератор произвольного доступа должен поддерживать
операции ->, +, ++, -, --, *, <, >, <=, >=, -=, +=, ==, != и []. Вдобавок операция * должна
позволять присваивание. Операции, поддерживаемые каждым типом итераторов, пере-
числены ниже.
Итератор Тип доступа
Произвольного доступа *, ->, =, +, -, ++, --, [], <, >, <=, >=, -=, +=, ==, !=
Двунаправленный *, ->, =, ++, --, ==, !=
Прямой *, ->, =, ++, ==, !=
Входной *, ->, =, ++, ==, !=
Выходной *, =, ++
При ссылках на различные типы итераторов в описаниях шаблонов будут использо-
ваны следующие термины.
Термин Итератор
BiIter Произвольного доступа
ForIter Двунаправленный
InIter Прямой
OutIter Входной
RandIter Выходной
Алгоритмы стандартной библиотеки С ++
Алгоритм |
Назначение |
adjacent_find |
Выполняет поиск совпадающих смежных элементов внутри последовательности и возвращает итератор для первого найденного совпадения |
binary_search |
Выполняет двоичный поиск заданного значения внутри упорядоченной последовательности |
copy |
Копирует последовательность |
copy_backward |
Аналогичен алгоритму copy, за исключением того, что копирование происходит в обратном порядке, т.е. сначала перемещаются элементы, находящиеся в конце последовательности |
count |
Возвращает количество элементов с заданным значением в последовательности |
count_if |
Возвращает количество элементов, которые удовлетворяют заданному предикату |
equal |
Определяет одинаковы ли два диапазона |
equal_range |
Возвращает диапазон, в который можно вставить элемент, не нарушая порядок некоторой последовательности |
fill и fill_n |
Заполняют диапазон заданным значением |
find |
В заданном диапазоне выполняет поиск заданного значения и возвращает итератор для первого вхождения найденного элемента |
find_end |
В заданном диапазоне выполняет поиск заданной последовательности. Возвращает итератор, соответствующий концу искомой последовательности |
find_first_of |
Выполняет поиск первого элемента внутри заданной последовательности, который совпадает с любым элементом из заданного диапазона |
find_if |
В заданном диапазоне выполняет поиск элемента, для которого определенный пользователем унарный предикат возвращает значение true |
for_each |
Применяет заданную функцию к заданному диапазону элементов |
generate и generate_n |
Присваивают значения, возвращаемые некоторой функцией генератором, элементам из заданного диапазона |
includes |
Устанавливает факт включения всех элементов одной заданной последовательности в другую заданную последовательность |
inplace_merge |
Объединяет один заданный диапазон с другим. Оба диапазона должны быть отсортированы в порядке возрастания. После выполнения алгоритма полученная последовательность сортируется в порядке возрастания |
iter_swap |
Меняет местами значения, адресуемые итераторами, которые передаются в качестве параметров |
lexicographical_compare |
Сравнивает одну заданную последовательность с другой в лексикографическом порядке |
lower_bound |
Выполняет поиск первого элемента в заданной последовательности, значение которого не меньше заданного значения |
make_heap |
Создает кучу из заданной последовательности |
max |
Возвращает максимальное из двух значений |
max_element |
Возвращает итератор для максимального элемента внутри заданного диапазона |
merge |
Объединяет две упорядоченные последовательности, помещая результат в третью последовательность |
min |
Возвращает минимальное из двух значений |
min_element |
Возвращает итератор для минимального элемента внутри заданного диапазона |
mismatch |
Выполняет поиск первого несовпадения элементов в двух последовательностях и возвращает итераторы для этих двух элементов |
next_permutation |
Создает следующую перестановку заданной последовательности |
nth_element |
Упорядочивает заданную последовательность таким образом, чтобы все элементы, значения которых меньше значенияE, размещались перед этим элементом, а все элементы, значения которых больше значения E, размещались после него |
partial_sort |
Сортирует заданный диапазон |
partial_sort_copy |
Сортирует заданный диапазон, а затем копирует столько элементов, сколько может поместиться в результирующую последовательность |
partition |
Сортирует заданную последовательность таким образом, чтобы все элементы, для которых заданный предикат возвращает значение true, размещались перед элементами, для которых этот предикат возвращает значение false |
pop_heap |
Меняет местами первый и предпоследний элементы заданного диапазона, а затем перестраивает кучу |
prev_permutation |
Создает предыдущую перестановку последовательности |
push_heap |
Помещает элемент в конец кучи |
random_shuffle |
Придает случайный характер заданной последовательности |
remove, remove_if, remove_copy иremove_copy_if |
Удаляют элементы из заданного диапазона |
replace, replace_copy, replace_if и replace_copy_if |
Заменяют заданные элементы из диапазона другими элементами |
reverse и reverse_copy |
Меняет порядок следования элементов в заданном диапазоне на противоположный |
rotate и rotate_copy |
Выполняет циклический сдвиг влево элементов в заданном диапазоне |
search |
Выполняет поиск одной последовательности внутри другой |
search_n |
Внутри некоторой последовательности выполняет поиск заданного числа подобных элементов |
set_difference |
Создает последовательность, которая содержит разность двух упорядоченных множеств |
set_intersection |
Создает последовательность, которая содержит пересечение двух упорядоченных множеств |
set_symmetric_difference |
Создает последовательность, которая содержит симметричную разность двух упорядоченных множеств |
set_union |
Создает последовательность, которая содержит объединение двух упорядоченных множеств |
sort |
Сортирует заданный диапазон |
sort_heap |
Сортирует кучу в заданном диапазоне |
stable_partition |
Упорядочивает заданную последовательность таким образом, чтобы все элементы, для которых заданный предикат возвращает значение true, размещались перед элементами, для которых этот предикат возвращает false. Такое разбиение является стабильным, что означает сохранение относительного порядка последовательности |
stable_sort |
Выполняет устойчивую (стабильную) сортировку заданного диапазона. Это значит, что равные элементы не переставляются |
swap |
Меняет местами заданные два значения |
swap_ranges |
Выполняет обмен элементов в заданном диапазоне |
transform |
Применяет функцию к заданному диапазону элементов и сохраняет результат в новой последовательности |
unique и unique_copy |
Удаляет повторяющиеся элементы из заданного диапазона |
upper_bound |
Находит последний элемент в заданной последовательности, который не больше заданного значения |
Алгоритмы обрабатывают данные, содержащиеся в контейнерах. Несмотря на то, что каждый контейнер обеспечивает поддержку собственных базовых операций, стандартные алгоритмы позволяют выполнять более расширенные или более сложные действия. Они также позволяют работать с двумя различными типами контейнеров одновременно. Для получения доступа к алгоритмам библиотеки STL необходимо включить в программу заголовок <algorithm>.
В библиотеке STL определено множество алгоритмов, которые описаны в таблице 1. Все эти алгоритмы представляют собой шаблонные функции. Это означает, что их можно применять к контейнеру любого типа.
6. Алфавит и идентификаторы языка С++
В тексте на любом естественном языке можно выделить четыре основных элемента: символы, слова, словосочетания и предложения. Подобные элементы содержит и алгоритмический язык, только слова называют лексемами (элементарными конструкциями), словосочетания — выражениями, а предложения — операторами. Лексемы образуются из символов, выражения — из лексем и символов, а операторы — из символов, выражений и лексем. В этой записи рассмотрен алфавит языка программирования C++ и его лексемы.
Алфавит C++
Алфавит C++ включает:
прописные и строчные латинские буквы и знак подчеркивания;
арабские цифры от 0 до 9;
специальные знаки: ? { } , ¦ [ ] ( ) + — / % * . \ ‘ : ? < = > ! & # ~ — ; ^
пробельные символы: пробел, символы табуляции, символы перехода на новую строку.
Из символов алфавита формируются лексемы языка:
идентификаторы;
ключевые (зарезервированные) слова;
знаки операций;
константы;
разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими, как разделители или знаки операций.
Идентификаторы
Идентификатор — это имя программного объекта. В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания. Прописные и строчные буквы различаются, например, sysop, SySoP и SYSOP — три различных имени. Первым символом идентификатора может быть буква или знак подчеркивания, но не цифра. Пробелы внутри имен не допускаются.
Совет
Для улучшения читаемости программы следует давать объектам осмысленные имена. Существует соглашение о правилах создания имен, называемое венгерской нотацией (поскольку предложил ее сотрудник компании Microsoft венгр по национальности), по которому каждое слово, составляющее идентификатор, начинается с прописной буквы, а вначале ставится префикс, соответствующий типу величины, например, iMaxLength, IpfnSetFirstDialog.
Другая традиция — разделять слова, составляющие имя, знаками подчеркивания: maxjength, number_of_galosh.
Длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения. Идентификатор создается на этапе объявления переменной, функции, типа и т. п., после этого его можно использовать в последующих операторах программы. При выборе идентификатора необходимо иметь в виду следующее:
идентификатор не должен совпадать с ключевыми словами и именами используемых стандартных объектов языка;
не рекомендуется начинать идентификаторы с символа подчеркивания, поскольку они могут совпасть с именами системных функций или переменных, и, кроме того, это снижает мобильность программы;
на идентификаторы, используемые для определения внешних переменных, налагаются ограничения компоновщика (использование различных компоновщиков или версий компоновщика накладывает разные требования на имена внешних переменных)
Ключевые слова
Ключевые слова — это зарезервированные идентификаторы, которые имеют специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены. Список ключевых слов C++ приведен в таблице ниже.
Список ключевых слов C++ |
|||
asm |
else |
new |
this |
auto |
enum |
operator |
throw |
bool |
explicit |
private |
true |
break |
export |
protected |
try |
case |
extern |
public |
typedef |
catch |
false |
register |
typeid |
char |
float |
reinterpret_cast |
typename |
class |
for |
return |
union |
const |
friend |
short |
unsigned |
const_cast |
goto |
signed |
using |
continue |
if |
sizeof |
virtual |
default |
inline |
static |
void |
delete |
int |
static__cast |
volatile |
do |
long |
struct |
wchar_t |
double |
mutable |
switch |
while |
dynamic_cast |
namespace |
template |
|
Знаки операций
Знак операции — это один или более символов, определяющих действие над операндами. Внутри знака операции пробелы не допускаются. Операции делятся на унарные, бинарные и тернарную по количеству участвующих в них операндов. Знаки операций приведены в отдельной заметке – Операции языка C++
Один и тот же знак может интерпретироваться по-разному в зависимости от контекста. Все знаки операций за исключением [ ], ( ) и ? : представляют собой отдельные лексемы.
Большинство стандартных операций может быть переопределено (перегружено).
Константы
Константами называют неизменяемые величины. Различаются целые, вещественные, символьные и строковые константы. Компилятор, выделив константу в качестве лексемы, относит ее к одному из типов по ее внешнему виду (формат константы можно указать самостоятельно).
Форматы констант, соответствующие каждому типу, приведены в таблице ниже.
Константа |
Формат |
Константа |
Целая |
Десятичный: последовательностьдесятичных цифр, начинающаясяне с нуля, если это не число нуль Восьмеричный: нуль, за которым следуют восьмеричные цифры (0,1,2,3,4,5,6,7)
Шестнадцатеричный: 0х или 0Х, за которым следуют шестнадцатеричные цифры (0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F) |
8, 0, 199226 01, 020, 07155
0хА, 0x1B8, 0X00FF |
Вещественная |
Десятичный:[цифры].[цифры]Экспоненциальный: [цифры][.][цифры]{Е¦е}[+¦ -][цифры] |
5.7, .001, 35.0.2Е6, .11е-З, 5Е10 |
Символьная |
Один или два символа, заключенных в апострофы |
‘А’, ‘ю’, ‘*’, ‘db’, ‘\0′, ‘\n’ , ‘\012′, ’\x07\x07′ |
Строковая |
Последовательность символов, заключенная в кавычки |
«Здесь был Vasia»,»\t3начение r=\0xF5\n» |
Не следует забывать, что у каждого типа данных есть диапазон допустимых значений.
Если требуется сформировать отрицательную целую или вещественную константу, то перед константой ставится знак унарной операции изменения знака (-), например: -218, -022, -0х3C, -4.8, -0.1e4.
Вещественная константа в экспоненциальном формате представляется в видемантиссы и порядка. Мантисса записывается слева от знака экспоненты (Е или е), порядок — справа от знака. Значение константы определяется как произведение мантиссы и возведенного в указанную в порядке степень числа 10. Обратите внимание, что пробелы внутри числа не допускаются, а для отделения целой части от дробной используется не запятая, а точка.
Символьные константы, состоящие из одного символа, занимают в памяти один байт и имеют стандартный тип char. Двухсимвольные константы занимают два байта и имеют тип int, при этом первый символ размещается в байте с меньшим адресом.
Все строковые литералы рассматриваются компилятором как различные объекты.
Строковые константы, отделенные в программе только пробельными символами, при компиляции объединяются в одну. Длинную строковую константу можно разместить на нескольких строках, используя в качестве знака переноса обратную косую черту, за которой следует перевод строки. Эти символы игнорируются компилятором, при этом следующая строка воспринимается как продолжение предыдущей. Например, строка
“Никто не доволен своей \ внешностью, но все довольны \ своим умом”
полностью эквивалентна строке
“Никто не доволен своей внешностью, но все довольны своим умом”
В конец каждого строкового литерала компилятором добавляется нулевой символ, представляемый управляющей последовательностью \0. Поэтому длина строки всегда на единицу больше количества символов в ее записи. Таким образом, пустая строка ?? имеет длину 1 байт.
Обратите внимание на разницу между строкой из одного символа, например, «А», и символьной константой ?А?.
Пустая символьная константа недопустима.
Арифметика указателей.
С указателями на данные возможны арифметические операции сложения и вычитания. Пример:
1 #include <iostream>
2
3 using std::cout;
4
5 int main(void) {
6 int a = 0;
7 int b = 0;
8 ptrdiff_t inInts = &a – &b;
9 ptrdiff_t inChars =
10 reinterpret_cast<char*>(&a)
11 – reinterpret_cast<char*>(&b);
12 cout
13 << inChars << ‘ ‘
14 << inInts << ‘\n’;
15 return 0;
16 }
Единица измерения разницы между указателями – это количество элементов указываемого типа. В приведённом примере в переменной inInts будет разница в int-ах, а в inChars – в char-ах. Надо заметить, что данный код может выводить на экран разные числа в зависимости от:
компилятора
размера int
вида сборки (debug/release)
Кроме вычитания (вычисления разницы указателей), к указателям можно применять операции сложения и вычитания с целым числом. Если в приведённом выше примере сложить &b и inInts, то мы получим &a:
1 #include <iostream>
2
3 using std::cout;
4
5 int main(void) {
6 int a = 0;
7 int b = 0;
8 ptrdiff_t inInts = &a – &b;
9 int* c = &b + inInts;
10 cout <<
11 ((&a == c)
12 ? “Equal\n”
13 : “Not equal\n”);
14 return 0;
15 }
Таким образом с двумя указателями можно производить следующие арифметические операции:
- == != < > <= >=
а с одним указателем и числом такие:
+ - ++ – += -=
С арифметикой указателей связана операция доступа к элементу массива по индексу. В приведённом ниже примере, все переменные получат значение элемента массива с индексом 3, т.е. это всё эквивалентные записи одной и той же идеи:
1 #include <iostream>
2
3 using std::cout;
4
5 int main(void) {
6 int a[5] = {1,2,3,4,5};
7 int v1 = *(a + 3);
8 int v2 = *(3 + a);
9 int v3 = a[3];
10 int v4 = 3[a];
11 int v5 = *(&a[0] + 3);
12 cout << v1 << ‘\n’;
13 cout << v2 << ‘\n’;
14 cout << v3 << ‘\n’;
15 cout << v4 << ‘\n’;
16 cout << v5 << ‘\n’;
17 return 0;
18 }
8. Арифметические операторы
- вычитание или унарный минус;
+ сложение;
* умножение;
/ деление;
% деление по модулю;
++ увеличение на единицу;
-- уменьшение на единицу;
9. АТД «стек» и варианты реализации
19. Базовые принципы ООП
Принцип персональной ответственности (Single Responsibility Principle) – класс обладает только 1 ответственностью, поэтому существует только 1 причина, приводящая к его изменению
Принцип открытия-закрытия (Open-Closed Principle) – классы должны быть открыты для расширений, но закрыты для модификаций. Расширение поведения производится за счет делегирования
Принцип подстановки Лискоу (Liskov Substitution Principle) – дочерние классы можно использовать через интерфейсы базовых классов без знания о том, что это дочерний класс. Другими словами дочерний класс не должен отрицать поведение родительского класса.
Принцип инверсии зависимостей (Dependency Inversion Principle) – зависимости внутри системы стоятся на основе абстракций (интерфейсы или абстрактный классы). Модули верхнего уровня не зависят от модулей нижнего уровня. Абстракции не зависят от подробностей.
Принцип отделения интерфейса (Interface Segregation Principle) – клиенты не должны попадать в зависимость от методов, которыми они не пользуются. Клиенты сами определяют, какие интерфейсы им нужны.
Основные принципы объектно-ориентированного программирования
|
||
|
||
Абстрагирование подразумевает собой процесс изменения уровня детализации программы. Основная его роль - выделение существенных характеристик некоторого объекта, отличающие его от всех других видов объектов и, таким образом, четкое определение его концептуальных границ с точки зрения наблюдателя. Когда мы абстрагируемся от проблемы, мы предполагаем игнорирование ряда подробностей с тем, чтобы свести задачу к более простой. Задача абстрагирования и последующей декомпозиции типична для процесса создания программ. Декомпозиция используется для разбиения программ на компоненты, которые затем могут быть объединены, позволив решить основную задачу, абстрагирование же предлагает продуманный выбор таких компонент. Последовательно выполняя то один, то другой процесс можно свести исходную задачу к подзадачам, решение которых известно. Для одного и того же моделируемого в программе объекта в зависимости от решаемой задачи необходимо учитывать различные свойства и характеристики, то есть рассматривать его на различных уровнях абстракции. Например, если мы будем рассматривать объект «Файл» в контексте разработки текстового редактора, то нас в первую очередь будут интересовать такие параметры объекта, как тип представления информации в файле, методы чтения и записи информации из/в файл, используемые промежуточные буферы для хранения информации. Иными словами, для данной предметной области интерес представляет внутреннее содержимое файла. Если же тот же объект «Файл» рассматривать в контексте разработки файлового менеджера, то на первый план выходят свойства объекта, характеризующие его как элемент файловой системы (имя файла, путь к файлу, атрибуты, права доступа и т.п.). Выбор правильного набора абстракций для заданной предметной области представляет собой главную задачу объектно-ориентированного проектирования. Инкапсуляция есть объединение в едином объекте данных и кодов, оперирующих с этими данными. В терминологии объектно-ориентированного программирования данные называются членами данных (data members) объекта, а коды - объектными методами иди функциями-членами (methods, member functions) Инкапсуляция является важным принципом ООП, организующим защиту информации от ненужных и случайных модификаций, что обеспечивает целостность данных и упрощает отладку программного кода после изменений. Все компоненты объекта разделяются на интерфейс и внутреннюю реализацию. Интерфейс - это лицевая сторона объекта, способ работы со стороны его программного окружения - других объектов, модулей программы. В интерфейсной части описывается, что умеет делать объект. Это похоже на ручку регулировки громкости у телевизора. Разработчик создал сложный объект (телевизор), и ручка регулировки громкости является тем интерфейсом, посредством которого окружение этого объекта (телезритель) может влиять на его внутреннее состояние (громкость звучания). В противоположность интерфейсу, внутренняя реализация объекта представляет собой те компоненты класса, которые по замыслу разработчика класса не должны быть доступны извне. Реализация - это изнанка объекта, она определяет, как он выполняет задание, поступающее от интерфейсных компонент. Продолжая аналогию с телевизором, можно сказать, что, очевидно, существует внутренняя реализация этого сложного технического объекта в виде совокупности электронных устройств, объединенных в сложные электрические схемы. Использование интерфейсного элемента (ручки регулировки) приводит в действие механизмы внутренней реализации, которые и обеспечивают в конечном итоге изменение громкости звучания прибора. При этом главным требованием принципа инкапсуляции, повторимся, является изоляция внутренней реализации объекта от окружения. Этим достигается целостность объекта при любых возможных внешних воздействиях на него. Для телевизора эта изоляция заключается в наличии защитных панелей, которые скрывают от пользователя детали внутреннего устройства и не позволяют изменять громкость, например, путем подкручивания отверткой каких-нибудь элементов электронной схемы. Для программной системы использование защитной панели, конечно, неприменимо, однако, идея изоляции внутреннего содержимого объекта от окружения реализуется посредством специальных средств объектно-ориентированных языков программирования. Таким образом, инкапсуляция реализует в объектно-ориентированном программировании принципы, предложенные Д. Парнасом, которые гласят: 1. Разработчик программы должен предоставлять пользователю всю информацию, которая нужна для эффективного использования приложения, и ничего кроме этого. 2. Разработчик программного обеспечения должен знать только требуемое поведение объекта и ничего кроме этого. Наследование состоит в процессе создания новых объектов (потомков) на основе уже имеющихся объектов (предков) с передачей их свойств и методов по наследству. Наследование позволяет модифицировать поведение объектов и придает объектно-ориентированному программированию исключительную гибкость. Идея наследования заимствована у природы, где потомство, наследуя основные характеристики предков, обладает некоторыми оригинальными отличительными особенностями. Программный объект также может унаследовать от объекта-предка некоторые свойства и методы, а добавленные к этим унаследованным атрибутам собственные свойства и методы позволяют расширить функциональность по отношению к объекту-предку. Преимущество принципа наследования заключается в повторном использовании кода, когда каждый новый объект не создается с нуля, а строится на фундаменте уже существующего объекта. При этом уменьшается как размер кода, так и сложность программы. Благодаря использованию принципа наследования в современные системы программирования включены библиотеки классов, которые представляют собой многоуровневые иерархические системы классов, описывающих элементы программного или пользовательского интерфейса прикладной программы. В основе подобных систем лежат базовые классы, которые обычно очень просты и являются обобщением свойств всех остальных классов библиотеки. Классы-потомки базовых дополняются собственными свойствами, приобретая дополнительную функциональность. Они, в свою очередь, становятся основой для классов следующих уровней иерархии. Таким образом формируется гибкая и стройная система классов. Примерами библиотек классов, построенных по такому принципу, можно назвать Turbo Vision, Objects Windows Library или Visual Component Libraries фирмы Inprise (Borland) или Microsoft Foundation Classes фирмы Microsoft. Достоинством библиотек классов помимо того, что они представляют готовый «строительный материал» для программиста в виде стабильно работающих объектов, является и то, что программист получает возможность создавать собственные классы, не определяя их с нуля, а всего лишь доопределив ряд недостающих свойств для какого-либо стандартного класса библиотеки, выбранного в качестве базового. Полиморфизм - это свойство родственных объектов (то есть тех объектов, классы которых являются производными от одного родителя) вести себя по-разному в зависимости от ситуации, возникающей в момент выполнения программы. Словополиморфизм происходит от греческих слов poly (много) и morphos (форма) и означает множественность форм методов объектов. Если в объекте-потомке и объекте-родителе определены одноименные методы, имеющие разную кодовую реализацию (это называется перегрузкой метода в объекте-потомке), то вызов данного метода может быть привязан к его конкретной реализации в одном из родственных объектов только в момент выполнения программы. Это называется поздним связыванием, а методы, реализующие позднее связывание - полиморфными или виртуальными. Принцип полиморфизма можно проиллюстрировать примером из реального мира, когда родственные объекты «птица», «рыба» и «животное» по-разному реализуют операцию «перемещение», летая, плавая и бегая соответственно. Таким образом, если предположить наличие базового класса «живое существо», обобщающего свойства этих трех объектов, то метод «перемещение» потребует полиморфного объявления. Это позволит избежать ситуаций, когда вызов метода «перемещение» для объекта типа «рыба» приведет к тому, что объект реализует операцию «бежать». Другой пример, который ближе к практике реального программирования: для иерархии объектов - графических фигур (окружность, квадрат, треугольник и т.п.) можно определить виртуальную функцию draw(), отображающую фигуру. Объявление функции draw() виртуальной позволит обеспечить надлежащий отклик на событие с требованием отобразить ту или иную фигуру. |
||
|
20. бесконечные циклы
Бесконечным циклом называется цикл, написанный таким образом, что условие выхода из него никогда не выполняется.
О программе, вошедшей в бесконечный цикл, иногда говорят, что она зациклилась. Использование этого глагола вышло далеко за пределы программирования, и он зачастую применяется с совершенно другим смыслом.
Примеры:
Оператор цикла for
for (;;) {
/* что-нибудь делаем */
}
Оператор цикла while
// вариант 1
while(true) {
/* что-нибудь делаем */
}
// вариант 2
while(1) {
/* что-нибудь делаем */
}
Оператор цикла do-while
// вариант 1
do {
/* что-нибудь делаем */
} while(true)
// вариант 2
do {
/* что-нибудь делаем */
} while(1)
21. Битовые операторы
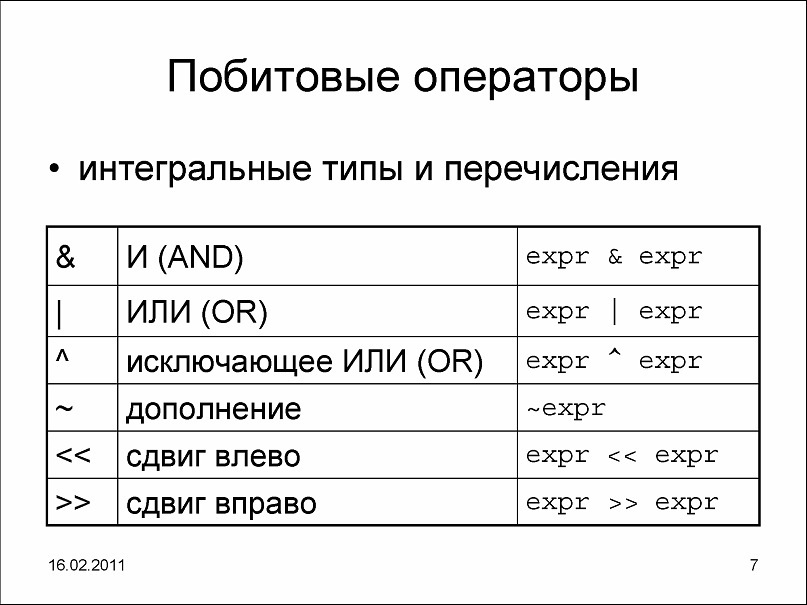
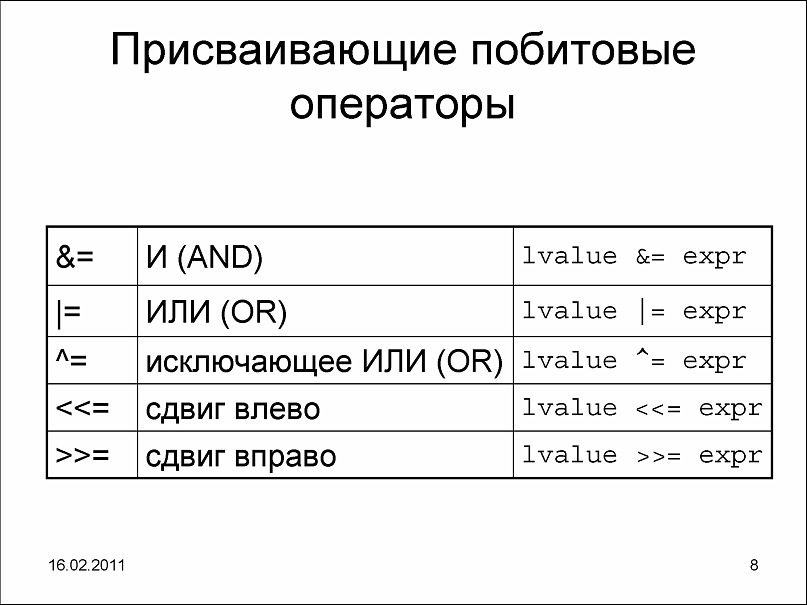
Битовые операторы по своему действию похожи на логические, за тем только исключением, что битовые операторы производят действия, как и следовало ожидать, над битами. op1 & op2 - Оператор "И" сравнивает два бита и генерирует результат "истина", если оба бита равны 1, иначе - "ложь" op1 | op2 - Оператор "ИЛИ" сравнивает два бита и генерирует результат "истина", если биты комплиментарные, иначе - "ложь". op1 ^ op2 - Оператор "Исключающее ИЛИ" сравнивает два бита и генерирует результат "истина", если один из битов (или они оба) равен 1, иначе - "ложь". ~op1 - Оператор "Дополнение" используется для инверсии всех битов. op1 >> op2 - Оператор "Сдвиг вправо" сдвигает все биты операнда вправо, теряя при этом правый крайний бит, - левый крайний бит становится равным 0. Каждый сдвиг битов операнда вправо равносилен его делению на 2. op1 << op2 - Оператор "Сдвиг влево" сдвигает все биты операнда влево, теряя при этом левый крайний бит, - правый крайний бит становится равным 0. Каждый сдвиг битов операнда вправо равносилен его умножению на 2. Замечание - битовые операции могут проводиться ТОЛЬКО над операндами целого типа.
22. буферизация при использовании потоков
Буферизация
• для записи и чтения используется
буфер, который освобождается при
переполнении или по требованию
пример:
strm.flush();
strm << obj << endl;
Работа с потоком начинается с его открытия. Поток можно открыть для чтения и/или записи в двоичном или текстовом режиме. Функция открытия потока имеет формат
FILE*fopen(const char*filename, const char*mode);
При успешном открытии потока функция возвращает указатель на предопределенную структуру типа FILE, содержащую всю необходимую для работы с потоком информацию, или NULL в противном случае. Первый параметр- имя открываемого файла в виде С-строки, второй – режим открытия файла:
“r”-файл открывается для чтения;
“w”-открывается пустой файл для записи( если файл существует, он стирается);
“a”-файл открывается для добавления информации в его конец;
“r+”-файл открывается для чтения записи(файл должен существовать;
“w+”-открывается пустой файл для чтения и записи
“a+”-файл открывается для чтения и добавления информации в его конец.
При открытии потока с ним связывается область памяти, называемая буфером. При выводе вся информация направляется в буфер и накапливается там до заполнения буфера или до закрытия потока. Чтение осуществляется блоками, равными размеру буфера, и данные читаются из буфера. Буферизация позволяет более быстро и эффективно обмениваться информацией с внешними устройствами. Следует иметь в виду, что при аварийном завершении программы выходной буфер может быть не выгружен, и возможна потеря данных. С помощью функций setbuf и setvbuf можно управлять размерами и наличием буфера.
23. Валидность итераторов
Инвалидация итераторов
Инвалидация итераторов происходит, когда итератор перестает указывать туда, куда должен указывать. В таком случае итератор становится невалидным.
vector
Инвалидация происходит при перераспределении
памяти, когда новый размер превышает
текущее значение параметра capacity.
Тогда происходит ивалидация всех
итераторов.
Если не происходит перераспределения памяти, то все итераторы после позиции вставки/удаления инвалидируются.
deque
Если элемент добавляется в пустую
последовательности или удаляется,
оставляя последовательность пустой,
итераторы на начало и конец
последовательности, полученные ранее
с помощью функций begin() и end(),
теряют валидность.
Если элемент вставляется на первую позицию или на последнюю, то все итераторы, определяющие существующие элементы, инвалидируются.
Если удаляется первый или последний элемент, то только итератор на него теряет валидность.
Во всех остальных случаях, добавление или удаление элемента приводит к инвалидации всех итераторов.
list
Если происходит удаление элемента из списка, то только итератор, указывавший на этот элемент, теряет валидность, т.к. в списке все элементы имеют постоянные адреса все время, пока существуют в списке.
24.ввод и вывод в стандартной библиотеке
Частью стандартной библиотеки C++ является библиотека iostream .В ней реализована поддержка для файлового ввода/вывода данных встроенных типов..
Для использования библиотеки iostream в программе необходимо включить заголовочный файл
#include <iostream>
Операции ввода/вывода выполняются с помощью классов istream (потоковый ввод) и ostream (потоковый вывод). Третий класс, iostream, является производным от них и поддерживает двунаправленный ввод/вывод. Для удобства в библиотеке определены три стандартных объекта-потока:
cin – объект класса istream, соответствующий стандартному вводу. В общем случае он позволяет читать данные с терминала пользователя;
cout – объект класса ostream, соответствующий стандартному выводу. В общем случае он позволяет выводить данные на терминал пользователя;
cerr – объект класса ostream, соответствующий стандартному выводу для ошибок. В этот поток мы направляем сообщения об ошибках программы.
Вывод осуществляется, как правило, с помощью перегруженного оператора сдвига влево (<<), а ввод – с помощью оператора сдвига вправо (>>):
#include <iostream>
#include <string>
int main()
{
string in_string;
// вывести литерал на терминал пользователя
cout << "Введите свое имя, пожалуйста: ";
// прочитать ответ пользователя в in_string
cin >> in_string;
if ( in_string.empty() )
// вывести сообщение об ошибке на терминал пользователя
cerr << "ошибка: введенная строка пуста!\n";
else cout << "Привет, " << in_string << "!\n";
}
Помимо чтения с терминала и записи на него, библиотека iostream поддерживает чтение и запись в файлы. Для этого предназначены следующие классы:
ifstream, производный от istream, связывает ввод программы с файлом;
ofstream, производный от ostream, связывает вывод программы с файлом;
fstream, производный от iostream, связывает как ввод, так и вывод программы с файлом.
Чтобы использовать часть библиотеки iostream, связанную с файловым вводом/выводом, необходимо включить в программу заголовочный файл
#include <fstream>
Ввод/вывод <cstdio> l<cstcnib> <cwchar> <fstream> <iomanip> 1 <ios> <iosfwcl> <iostream> <istreanp> <ostreanp' <sstream> <streambuf>
|
Функции ввода/вывода в стиле С Функции для работы с символами Функции ввода/вывода в стиле С для многобайтных символов Файловые потоки Манипуляторы Базовые классы потоков ввода/вывода Предварительные объявления средств ввода/вывода Стандартные объекты и операции с потоками ввода/вывода Входные потоки Выходные потоки Строковые потоки Буферизация потоков |
25. вещественные типы
Типы с плавающей точкой
• float – одинарная точность
• double – двойная точность
• long double – расширенная точность
26.
.виртуальная функция — это функция, которая может быть переопределена классом-наследником, для того чтобы тот имел свою, отличающуюся, реализацию. В языке C++ используется такой механизм, как таблица виртуальных функций
(кратко vtable) для того, чтобы поддерживать связывание на этапе выполнения программы. Виртуальная таблица — статический массив, который хранит для каждой виртуальной функции указатель на ближайшую в иерархии наследования реализацию этой функции. Ближайшая в иерархии реализация определяется во время выполнения посредством извлечения адреса функции из таблицы методов объекта.
27. Массив (встроенный)
• составной пользовательский тип
• тип T[size] – тип “массив из size
элементов типа Т”
• элементы индексируются от 0 до size-1
• в памяти расположены подряд
пример:
int divisors[12]; //! не инициализирован
Инициализация встроенного массива
• списком инициализаторов
• размер массива м.б. вычислен по
списку инициализации
• не указанные в списке значения
инициализируются по умолчанию
• используйте T arr[SIZE] = {0};
пример:
int ar1[] = {l, 2, 3, 4};
int ar2[32] = {l, 2};
int ar3[MAX_NUMS] = {0};
28.
Выражения
Как уже говорилось выше, выражения состоят из операндов, знаков операций и
скобок и используются для вычисления некоторого значения определенного
типа. Каждый операнд является, в свою очередь, выражением или одним из его
частных случаев — константой или переменной.
Примеры выражений:
(а + 0.12)/6
х && у II !z
(t * sin(x)-L05e4)/((2 * к + 2) * (2 * к + 3))
Операции выполняются в соответствии с приоритетами. Для изменения порядка
выполнения операций используются круглые скобки. Если в одном выражении за-
писагю несколько операций одинакового приоритета, унарные операции, условная
операция и операции присваивания выполняются справа палево, остальные — слева
направо. Например, а = b = с означает а = (Ь = с), а а + b + с означает (а + Ь) + с.
Порядок вычисления подвыражений внутри выражений не определен: например,
нельзя считать, что в выражении (sin(x + 2) + cos(y + 1)) обращение к синусу будет
выполнено раньше, чем к косинусу, и что х + 2 будет вычислено раньше, чем
У+1.
Результат вычисления выражения характеризуется значением и типом. Например,
если а и b — переменные целого типа и описаны так:
int а = 2. b = 5: