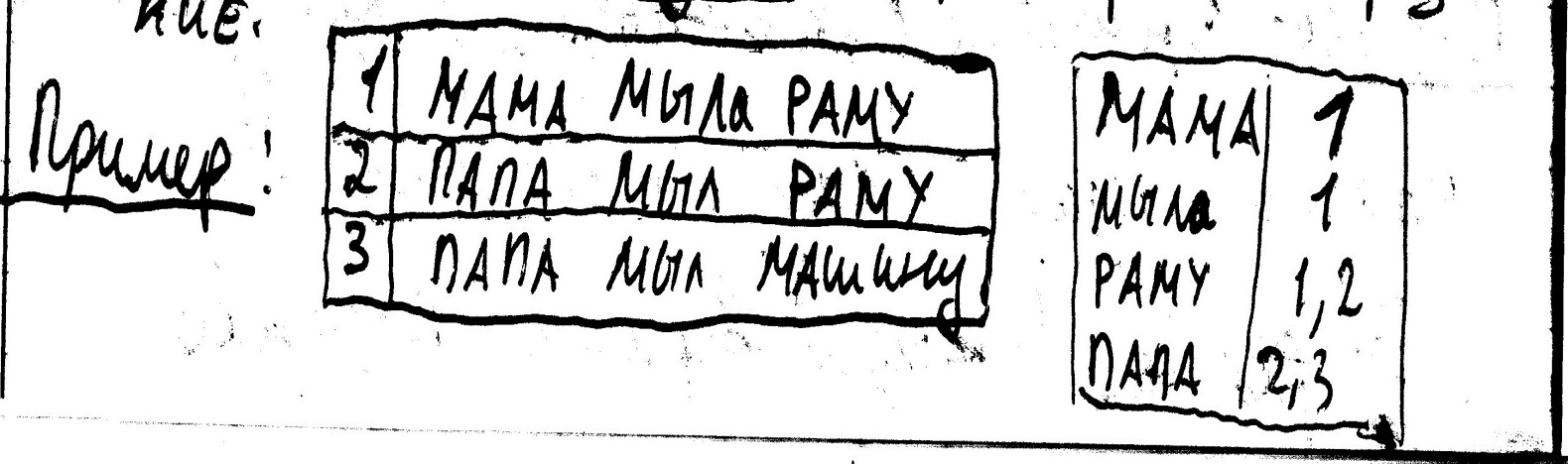39. Физические модели баз данных. Типы индексов.
1)В-дерево.
Применяется для организации индексов
многих СУБД. Индексирует информацию на
жестком диске. Обладает свойствами
сбалансированности и высокой ветвистости.
(Доступ к каждому блоку на жестком диске
очень велик, поэтому важно уменьшить
количество узлов, просматриваемых при
каждой операции).
2)
Пространственный индекс.
Разбиение области пространства на
ячейки одинакового размера. Для каждой
ячейки создается список всех
 объектов,
имеющих с ней непустое пересечение.
Строится список объектов, являющихся
объединением списков объектов для
соответствующих ячеек.
объектов,
имеющих с ней непустое пересечение.
Строится список объектов, являющихся
объединением списков объектов для
соответствующих ячеек.
R-дерево
строится по ограничивающим прямоугольным
параллелепипедам исходных объектов.
Напоминает В-дерево. В каждой вершине
R-дерева
фиксированное число объектов.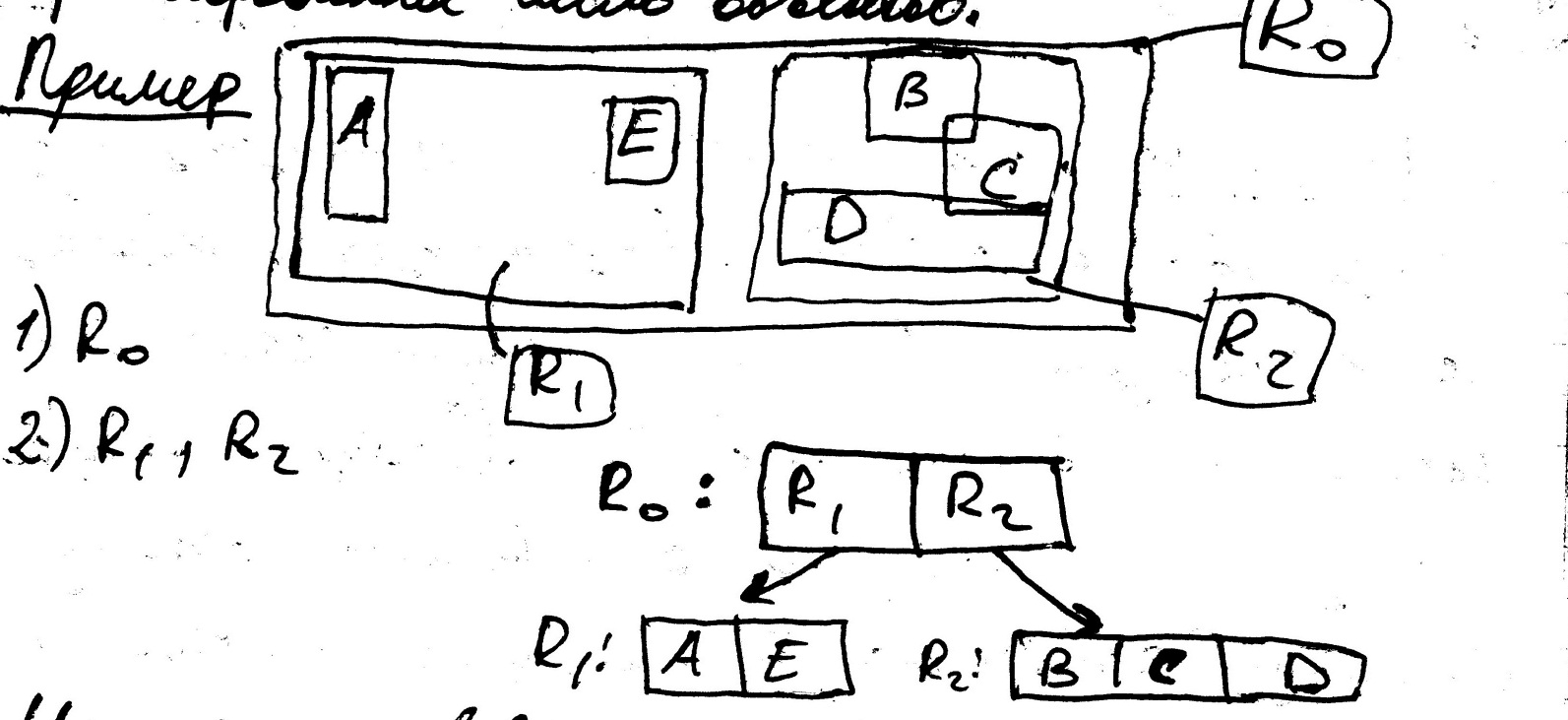
Используется в СУБД по пространственным данным.
Хэш-индекс. Хранение не самих значений, а их хэшей ->уменьшается размер. Из-за нелинейности хэш-функций нельзя сортировать. Нельзя использовать в сравнениях больше/меньше.
Индексы с реверсированным ключем. Тоже В-дерево, но с реверсивным ключем. Реверс нужен для того, чтобы записи индекса попадали в разные блоки.
Полнотекстовый индекс. Ориентировано на разбиение.