

13.5 Примерный порядок выполнения простых однотабличных запросов
Таблица результатов простого однотабличного запроса генерируется следующим образом:
1. Взять таблицу, указанную в предложении FROM.
2. Если имеется предложение WHERE, применить заданное в нем условие отбора к каждой строке таблицы и оставить только те строки, для которых это условие выполняется (TRUE), остальные строки отбросить.
3. Для каждой из оставшихся строк вычислить значение каждого элемента в списке возвращаемых столбцов (предложение SELECT) и создать одну строку таблицы результатов запроса.
4. Если указано ключевое слово DISTINCT, удалить из таблицы результатов запроса все повторяющиеся строки.
5. Если имеется предложение ORDER BY, отсортировать результаты запроса.
13.6. Многотабличные запросы
Рассмотренные до настоящего момента запросы выбирали данные из одной таблицы. Поскольку информация в базе данных хранится в нескольких таблицах, на практике очень часто требуется использовать запросы, использующие данные из нескольких таблиц. Такие запросы называют многотабличными.
13.6.1. Полные имена столбцов.
Поскольку в различных таблицах столбцы могут называться одинаково, возникает необходимость «разъяснения» СУБД, из какой таблицы должен выбираться тот или иной столбец. Для этой цели используются полные имена столбцов, которые имеют вид:
<Имя_таблицы>.<Имя_столбца>
Такая запись позволяет СУБД однозначно идентифицировать каждый столбец, указанный в запросе. В случае если столбец задан не полным именем, и столбец с таким именем присутствует в нескольких таблицах многотабличного запроса, СУБД выдаст сообщение об ошибке, в котором будет сказано, что в запросе присутствует неоднозначная ссылка на столбец.
13.6.2. Псевдонимы таблиц.
Нетрудно заметить, что полные имена столбцов существенно увеличивают текст запроса и делают его трудночитаемым. Поэтому в полных именах столбцов часто используют псевдонимы таблиц, которые задаются в предложении FROM через пробел после имени таблицы:
FROM <Имя таблицы1> <Псевдоним_табл1>, <Имя таблицы2> <Псевдоним_табл2>, …
Псевдонимы делают как можно более короткими, в идеале – состоящими из одной буквы.
При наличии псевдонима таблицы в запросе полные имена столбцов будут иметь вид:
<Псевдоним_табл>.<Имя_столбца>
Псевдонимы таблиц действуют только внутри самого запроса, они никак не влияют на структуру базы данных и реальные имена таблиц.
В сложных запросах рекомендуется использовать псевдонимы для всех используемых таблиц и полные имена столбцов.
13.6.3. Особенности многотабличных запросов.
Если в запросе используются данные из нескольких таблиц, то все требуемые таблицы необходимо перечислить в предложении FROM. Однако нужно понимать, что сначала СУБД из всех исходных таблиц получает одну результирующую таблицу посредством операции умножения.
Умножение (декартово произведение) двух таблиц представляет собой таблицу (называемую таблицей произведения), состоящую из всех возможных комбинаций строк двух исходных таблиц. Столбцами таблицы произведения являются все столбцы первой таблицы, за которыми следуют все столбцы второй таблицы.
Пример. Пусть имеется база данных, в которой хранится информация о домашних животных и их владельцах.
Схема данных имеет следующий вид:

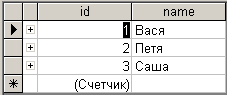
Содержимое таблицы OWNERS (владельцы):
Содержимое таблицы ANIMALS (животные):

Необходимо вывести список домашних животных и имена их владельцев.
Как видно из схемы данных, в таблице ANIMALS определено поле owner_id, которое является внешним ключом: в этом поле содержится идентификационный номер владельца для каждого животного (считается, что у одного животного может быть только один владелец). Именно благодаря связи между полями owner_id и id (из таблицы OWNERS) для каждого животного можно узнать имя его владельца.
Очевидно, что для получения требуемого результата нам потребуются обе таблицы. Для начала будем считать, что нам требуется полная информация о животных и их владельцах.
Тогда первые два предложения искомого запроса можно записать так:
SELECT *
FROM ANIMALS, OWNERS
Давайте проанализируем, как будет выполняться этот запрос.
Так как в предложении FROM перечислены названия двух таблиц, то SQL выполнит декартово произведение (умножение) этих двух таблиц и сформирует одну результирующую таблицу (таблицу произведения). При этом результирующая таблица будет содержать все возможные комбинации строк первой и второй таблиц, т.е. «на всякий случай» каждому животному будет поставлен в соответствие каждый владелец. Количество строк в результирующей таблице будет равно количеству строк первой таблицы, умноженному на количество строк во второй таблице. В нашем случае результирующая таблица будет содержать 4x3=12 строк.
Так как в предложении SELECT указана звездочка, то результирующая таблица будет содержать все столбцы таблицы ANIMALS и следующие за ними все столбцы таблицы OWNERS.
Таким образом, в результате выполнения выше приведенного запроса получим следующий результат:
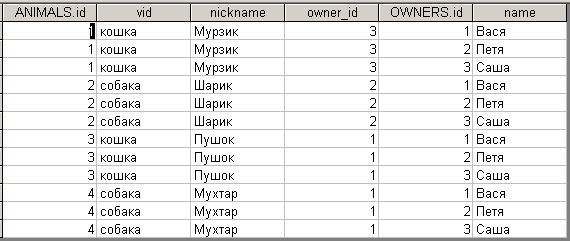
Очевидно, что нас не устраивают такие результаты. Получается, что каждое животное принадлежит сразу всем владельцам (и наоборот), что, конечно же, неверно (как видно из содержимого исходных таблиц). Другими словами, таблица произведения содержит много лишних, некорректных строк, в которых представлена неверная (несвязанная) информация. Справедливости ради отметим, что наряду с некорректными строками данная таблица произведения содержит также и все нужные нам, «правильные» строки со связанной информацией, как видно из следующей таблицы.
В этих «правильных» строках в связанных столбцах (согласно схеме данных это столбцы owner_id и OWNERS.id) находятся одинаковые значения, т.е. эти строки удовлетворяют следующему условию (условию равенства связанных столбцов):
Owner_id=OWNERS.id
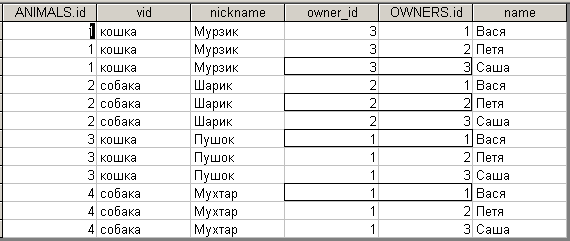
Таким образом, из всех строк результирующей таблицы необходимо оставить только нужные, или, другими словами, отбросить некоторые ненужные.
Произведение двух таблиц, из которого удалены некоторые строки, называется соединением этих таблиц.
Из вышесказанного следует вывод, что для правильной работы многотабличного запроса необходимо получить не произведение всех исходных таблиц (что осуществляется при указании названий всех таблиц в предложении FROM), а соединение всех исходных таблиц, в котором остаются только строки со связанной корректной информацией.
Следовательно, для получения соединения всех исходных таблиц (фактически для отбрасывания из таблицы произведения некоторых некорректных строк), в многотабличном запросе должно присутствовать предложение WHERE, в котором указывается условие (или несколько условий) равенства связанных столбцов.
В нашем случае предложение WHERE будет выглядеть так:
WHERE owner_id=OWNERS.id
Введя псевдонимы для обеих таблиц и учитывая то, что согласно заданию в качестве возвращаемых столбцов нам потребуются только столбцы vid, nickname и name, окончательный правильный вариант требуемого запроса запишем в следующем виде:
SELECT A.vid, A.nickname, O.name
FROM ANIMALS A, OWNERS О
WHERE A.owner_id=O.id;
В результате выполнения этого запроса мы получим требуемую информацию:
