

7. Модели данных
В классической теории баз данных модель данных есть формальная теория представления и обработки данных в СУБД, которая включает, по меньшей мере, три аспекта:
- аспект структуры (методы описания типов и логических структур данных в базе данных);
- аспект манипуляции (методы манипулирования данными);
- аспект целостности (методы описания и поддержки целостности базы данных).
Аспект структуры определяет, что из себя логически представляет база данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных, аспект целостности определяет средства описаний корректных состояний базы данных.
7.1. Иерархическая модель данных
В основе иерархической модели данных лежит древовидная структура. Иерархическая модель представляет собой упорядоченный набор деревьев, точнее, набор экземпляров одного типа дерева. Дерево состоит из связанных сегментов различных уровней (см. рис. 7.1).
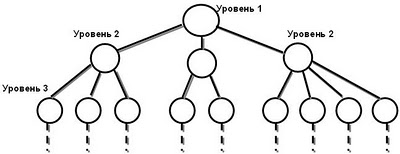
Рисунок 7.1 – Иерархическая модель данных
Основными информационными единицами в иерархической модели являются сегмент и поле. Поле - наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Тип сегмента — это поименованная совокупность входящих в него типов полей. Экземпляр сегмента образуется из конкретных значений полей данных.
Между сегментами существуют связи типа «предок-потомок». Дерево начинается с корневого сегмента. Каждый сегмент имеет не более одного предка, произвольное количество потомков и, по крайней мере, одно поле.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего предка.
К сегментам могут применяться такие операции как запомнить, модифицировать, удалить, извлечь, найти. Операция поиска сводится к одной из возможных процедур обхода дерева и всегда начинается с корневого сегмента в направлении потомков.
Иерархическая модель довольно удобна для представления предметных областей, так как иерархические отношения довольно часто встречаются между сущностями реального мира. Иерархическая модель позволяет реализовать связи типа «один-к-одному» и «один-ко-многим».
Достоинства иерархической модели: простота и быстродействие.
Недостатки иерархической модели:
- необходимость дублирования деревьев для реализации связей типа «многие-ко-многим» и, следовательно, увеличение затрат на поиск;
- невозможность существования потомка без предка (ввод пустых сегментов-предков, удаление предка влечет за собой удаление всех его потомков);
Примером иерархической модели является дерево каталогов в операционных системах компании Microsoft. В файловой системе существует корневой диск (возможно, несколько дисков), в котором могут размещаться папки (каталоги) и файлы. Внутри папки могут находиться как файлы, так и другие папки, в которых, в свою очередь, также папки и файлы. При этом уровень вложенности папок практически неограничен. Требование иерархической модели о том, что каждый узел может быть связан только с одним узлом вышележащего уровня иерархии в файловой системе также соблюдается – файл может физически находиться только в одной папке. Если его необходимо поместить в две папки, требуется выполнить копирование файла. При этом фактически получится два независимых файла, то есть при изменении одного из них, другой файл не изменится, если повторно не выполнить копирование.