

Изменение параметров бд (alter database)
Выполняется с помощью команды
ALTER DATABASE имя_БД
MODIFY FILE логическое_имя (SET параметр = значение)
Пример. Установление максимального размера файла данных
ALTER DATABASE TestDB1
MODIFY FILE TestDB1_Data (SET MAXSIZE = 5)
Удаление бд (drop database)
Выполняется с помощью команды
DROP DATABASE имя_БД
Пример. Удаление БД TestDB1
DROP DATABASE TestDB1
Создание Групп файлов (Filegroups)
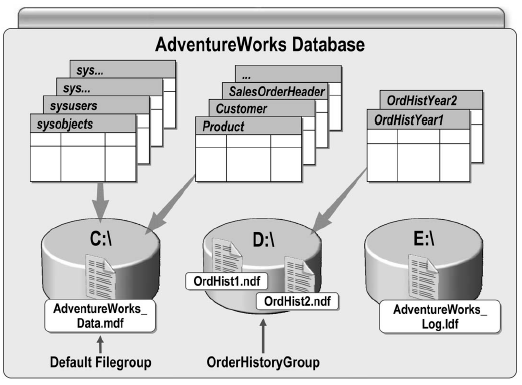
Файловая группа – логическая совокупность файлов данных, которая позволяет администратору управлять файлами внутри файловой группы как одним файлом. Например, вы можете использовать файловые группы для контроля физического расположения объектов БД и для разделения изменяемых данных от данных, предназначенных только для чтения.
Типы файловых групп. База данных содержит файловую группу Primary (первичная) и может содержать несколько групп, определенных пользователем.
Файловая группа Primary содержит первичный файл данных с системными таблицами. Первичный файл данных обычно имеет расширение .mdf.
Файловая группа, определенная пользователем состоит из файлов данных, сгруппированных вместе для одних и тех же административных задач. Эти файлы данных принято называть вторичными, и они обычно имеют расширение .ndf.
Пример сценария
Можно создать файловые группы для разделения часто запрашиваемых файлов данных от часто изменяемых файлов данных. Например, файлы OrdHist1.ndf и OrdHist2.ndf расположены отдельно от таблиц Product, Customer и SalesOrderHeader. Нельзя располагать журнал транзакций в файловых группах, т.к. журнал транзакций управляется отдельно от пространства данных. Журнал транзакций имеет обычно расширение .ldf. Пример создания БД:
CREATE DATABASE [AdventureWorks] ON
PRIMARY
( NAME = N'AdventureWorks_Data', FILENAME = N'C:\AdventureWorks_Data.mdf' ),
FILEGROUP [OrderHistoryGroup]
( NAME = N'OrdHist1', FILENAME = N'D:\OrdHist1.ndf' ),
( NAME = N'OrdHist2', FILENAME = N'D:\OrdHist2.ndf' )
LOG ON
( NAME = N'AdventureWorks_log', FILENAME = N'E:\AdventureWorks_log.ldf')
Для удаления или добавления файлов и файловых групп существующей БД можно использовать команду ALTER DATABASE. Например:
ALTER DATABASE TestDB
ADD FILEGROUP [Secondary]
GO
ALTER DATABASE TestDB
ADD FILE (NAME=N’Test2’,
FILENAME=N’C:\Program Files\Microsoft SQL Server\
MSSQL.1\MSSQL\Data\Test2.ndf’)
TO FILEGROUP [Secondary]
GO
ALTER DATABASE TestDB MODIFY FILEGROUP [Secondary] DEFAULT
GO
Используя файловые группы, вы можете:
Хранить изменяемые данные отдельно от данных, предназначенных только для чтения.
Хранить индексы отдельно от таблиц.
Резервировать и восстанавливать некоторые файлы или файловые группы вместо целой БД.
Группировать таблицы и индексы с похожими требованиями сопровождения в одной и той же файловой группе.
Разделить пользовательские таблицы и другие объекты БД от системных таблиц БД. В этом случае необходимо сменить файловую группу по умолчанию, чтобы предотвратить неожиданный рост таблиц БД от системных таблиц в первичной файловой группе.
Хранить секции секционированных таблиц в разных файловых группах. Это хороший способ физически разделить данные для различных нужд доступа внутри одной таблицы и может дать выигрыш в производительности.