

4.7.Структуры данных типа таблица. Способы организации таблиц. Основные операции над табличными структурами. Организация поиска в таблицах. Примеры операций поиска в таблицах.
Динамические структуры данных любого типа – вектор, список, таблица – объявляются без описания их размерности. В процессе решения задач размерности этих структур могут изменяться.
Использование динамической памяти для организации хранения массивов в памяти позволяет задавать только адрес массива в памяти, а его размерность определять при решении задачи. При этом место для данных выделяется из свободной области ОП (new)– из «кучи», а обращение к выделенным областям происходит по указателям на них. Выделенную память необходимо освобождать по окончанию работы с ней (delete).
На основе указателей строятся такие динамические структуры данных, как: динамический вектор, список, таблица, дерево и т.п.
Для объявления класса таблицы можно воспользоваться определением двумерного массива или массива из указателей на списки любого типа.
Таблица как массив массивов:
class CTable { … int x[][]; … } |
обращение к j-тому элементу i-той строки: x [i, j]
struct CListNode { int x; CListNode* next; }; class CTable { … CListNode* head[]; …} |
обращение к первому элементу списка i-той строки внутри класса:
CListNode* h = head[i];
cout<<h->x;
остальные элементы списка адресуются последовательным перебором.
while (h->next != null)
h = h->next;
Поиск в таблицах.
Алгоритмизация поиска значений очень важна для решения многих задач.
Основная задача поиска – определение наличия требуемого ключа.
а) Поиск в упорядоченных таблицах.
Последовательный поиск прямым перебором - достаточно найти больший ключ и поиск можно останавливать. Неэффективен, C=(n+1)/2
Предполагается, что есть некоторый массив ключей K[i] записей A[i]. Ищется K[i] =key. В этом алгоритме последовательно проверяются все имеющиеся ключи. Оценка эффективности поиска через p (i) - вероятность извлечения i – ой записи.
p(1)+ p(2)+ p(3)+……. P(n) =1, если искомый ключ есть в структуре. Среднее число сравнений: p(1)+2* p(2)+3* p(3)+…….n* P(n)
Минимизация поиска обеспечивается соотношением
P(n) ≤…… ≤ p(3) ≤ p(2) ≤ p(1)
Из этого соотношения видно, что переупорядочивание данных существенно увеличивает скорость последовательного поиска. Два алгоритма переупорядочивания: перемещение в начало и метод транспозиции. Найденные записи перемещаются в начало или меняются местами с предыдущей записью.
Бинарный поиск, когда поиск производится в половине таблицы, а затем, в зависимости от соотношения ключей, выбирается та часть таблицы, в которой требуемый ключ наиболее вероятен. Имеет количество сравнений приблизительно C=log2n.
-
D1
D 2
D3
Dn
Mid = n+1 div 2

D
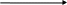 mid
< key
mid
< key
8 |
запись |
14 |
запись |
21 |
……… |
23 |
……… |
34 |
…….. |
37 |
……… |
41 |
запись |
56 |
запись |
23 |
у |
56 |
… |
 казатель
казатель …….
…….Задачи удаления и вставки элементов должны решаться алгоритмически. Каждый удаляемый элемент может снабжаться признаком и физически не перемещаться. Вставить элемент можно на место удаленного.
Задача разработчика – обеспечить различие ключей: у разных элементов таблицы не может быть одинаковых ключей.
Методы преобразования таблицы для организации поиска. а) Метод транспозиции – перемещения.
При многократном обращении к поиску i-ой записи в таблице, она перемещается к началу таблицы (на 1-ое место или другое место). Постепенно таблица упорядочивается в соответствии с требованиями поиска.
б) Хеш-таблицы.
Хеш-таблицы отличаются от простых таблиц тем, что для поиска и идентификации записей в таблицах используются преобразования ключей таблицы в некоторый индекс. Функция, обеспечивающая такое преобразование – хеш-функция: H- хеш-функция, key – ключ элемента таблицы. Пример хеш-ф-ции:
H(key)=mod(key, 10); - В этом случае хеш-функция имеет значения от 0 до 9.
Организация поиска в хеш-таблицах.
Организуются списки из всех записей, чьи ключи хешируются в одно и то же значение. Пример:
40,75,63,78,130, 91, 15,85
0
40
|
|
1 |
|
2 |
n |
3 |
|
4 |
nil |
5 |
75
|
6 |
n |
7 |
nil |
8 |
78 nil |
9 |
nil |




 il
il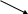


 il
il
Решение проблемы размещения элементов с одинаковыми ключами обеспечивается простым размещением нового элемента таблицы в соответствующей цепочке.
Удаление элемента таблицы также не требует её преобразования - уничтожаем только элемент цепи. Вставка нового элемента – в соответствующую цепь.
Поиск: искомый ключ хешируется -> получаем номер строки. Уже в ней – последовательный перебор. Т.о. хэш-таблица есть способ хранения данных в неотсортированном виде, оптимизированный для поиска.
Выбор хеш-функции
Метод деления. Некоторый целый ключ делится на размер таблицы
H (Key) =mod (Key , m) - 1987 mod 100 = 87
2. Метод середины квадрата. Ключ умножается сам на себя и из полученного числа выбирается несколько средних цифр этого квадрата. Пример:1987*1987=3948169 или 1986*1986=3944196. Получены разные ключи.
3. Метод свертки. Ключ в двоичном представлении разбивается на сегменты и над этими сегментами выполняется операция XOR:
Пример: Ключ = 1101010011 . Разбиваем ключ на два числа по 5 разрядов
И над двумя числами выполняем операцию XOR: