

1.5.Физические модели баз данных
Классификация файлов, используемых в системах баз данных

В соответствии с методам управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с последовательной адресацией (магнитофоны). Файлы с постоянной длиной записи расположенные на устройствах прямого доступа является файлами прямого доступа.
Для файлов с постоянной длиной записи адрес размещения записи с N к вычисляется т.о.
ВА+(К-1)+LZ+1, где ВА – базовый адрес, LZ – длина записи.
Файлы с переменной длиной записи всегда являются файлами непоследовательного доступа. Они организовываются двумя способами:
1. конец записи отличается специальным маркером
2. В начале каждой записи записывается ее длина.
В БД доступ по N записи неэффективный, как правило, мы знаем значение ключа, но не знаем №записи, соответствующий этому ключу.
Для файлов прямого доступа иногда можно построить функцию, которая по значению ключа однозначно вычислила адрес (№записи файла).
NZ=F(K), К – значение ключа.
F() должна быть линейной, чтобы обеспечивать однозначное соответствие.
Если значения ключей разбросаны по нескольким диапазонам, то построить взаимнооднозначную функцию не удается. В этом случае используют методы хеширования (рандомизации). Создаются специальные хэш-функции h(К), К – значение ключа.
Однако несколько разным ключам могут соответствовать одно значение h(K), т.е. один адрес, - возникают коллизии.
При использовании хеширования необходимо:
- выбрать хеш-функцию,
- выбрать метод разрешения коллизий.
а) использование области переполнения
б) использование области свободного замещения
а) основная область

б) для любой записи добавляется 2 указателя: указатель на предыдущую запись и указатель на следующую
Индексные файлы (индексно-прямые, индексно-последовательные, В-деревья
Индексные файлы могут представить как файлы состоящие зи 2-х частей: индексная часть и основная часть. Различают 2 типа файлов:
- с плотным индексом или индексно-прямые файлы
- с неплотным индексом (неполным) или индексно – последовательные файлы
значение ключа – это значение первичного ключа
Для индексно-прямых файлов поиск начинается в индексной области, где применяется двоичный алгоритм поиска, потом путем прямой адресации обращение к основной области по конкретному номеру записи.
Количество обращений к диску (при поиске записи):
Тn=log2 N+1
Например Длина записи LZ=12 байт. Количество записей в файлах KZ=100000
Размер блока LB=1024 байт
т.к. количество записей 100000, то для записи N нужно 4 байта, следовательно длина индексной записи LI: LI=LK+4=16 байт
1024/16=64 – количество индексн. записей в одном блоке 100000/64=1563 блоков следовательно Tn=log21563+1=11+1=12 обращений к диску
Если нет индексного пространства, то при произвольном хранении в основной области 100000/(1024/128)=12500 блоков – обращений к диску (времени просмотра внутри блока пренебрегаем). Т.к. процесс происходит в оперативной памяти.
Для индексно последовательный файлов – файлы хранятся в упорядоченном виде, следовательно Tn=log212500=14 обращений к диску.
Неплотный индекс строится для упорядоченных файлов. Индекс имеет вид:
-
Значение ключа 1-й записи блока
№ блока с этой записью
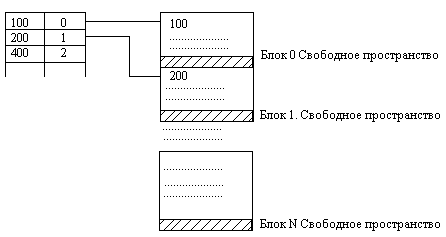
Пример заполнения индексной и основной области при организации неплотного индекса. Если для плотного индекса нужно было ссылаться на 100000 записей, то сейчас – при неплотном индексе требуется ссылаться на 12500 блоков, следовательно для ссылки (т.е. для адреса) достаточно 2 байта. Следовательно, длина индексной записи:
LI=LK+2=12+2=14 байт
1024/14=73 – количество индексных записей в одном блоке 12500/73=172 – количество индексных блоков.
Tn=log2 172+1=8+1=9 – обращений к диску.
Следовательно организация неплотного индекса дает выигрыш в скорости по сравнению с плотным индексом.
Организация индексов в виде В-деревьев:
Идея: построить индекс над уже существующим индексом (например неплотным индексом). Область может быть рассмотрена как основной файл, над которым снова строим неплотный индекс и т.д., пока не останется всего один индексированный блок.
При вставке и удалении узлов производится реструктуризация дерева с тем, чтобы сохранить его сбалансированность.
Инвертированные списки
Осуществляется доступ по первичным ключам. Инвертированный список – это двухуровневая индексная структура. На первом уровне упорядоченные значения вторичных ключей. На втором уровне цепочка блоков, содержащих номера записей, содержащих одно и то же индексное значение второго ключа. Далее – собственно основной файл.
При модификации основного файла
- изменяется запись основного файла
- исключается старая ссылка на предыдущее значение вторичного ключа.
- добавляется новая ссылка на новое значение вторичного ключа.
Страничная организация памяти
Основная единица обмена является страница данных. Все данные хранятся постранично.
Все страницы имеют определенную структуру.
 -
4 –х байтовое слово: 2 байта – смещение
строки на странице,
-
4 –х байтовое слово: 2 байта – смещение
строки на странице,
2 байта – длина строки.
Любая строка в БД имеет уникальный идентификатор RowID – 4 байта; номер страницы и номер строки на странице. Под номер страницы отводится 3 байта
мы можем адресоваться к 16777215
Все манипуляции происходят со слотами а не строками.