

1.4. Проектирование баз данных
Цели проектирования
Информационные системы больших организаций содержат несколько десятков БД, нередко распределенных между несколькими взаимосвязанными ЭВМ различных подразделений. (Так в больших городах создается не одна, а несколько овощных баз, расположенных в разных районах.)
Отдельные БД могут объединять все данные, необходимые для решения одной или нескольких прикладных задач, или данные, относящиеся к какой-либо предметной области (например, финансам, студентам, преподавателям, кулинарии и т.п.). Первые обычно называют прикладными БД, а вторые – предметными БД (соотносящимся с предметами организации, а не с ее информационными приложениями).
Каждый из рассмотренных подходов к проектированию воздействует на результаты проектирования в разных направлениях. Желание достичь и гибкости, и эффективности привело к формированию методологии проектирования, использующей как предметный, так и прикладной подходы. В общем случае предметный подход используется для построения первоначальной информационной структуры, а прикладной – для ее совершенствования с целью повышения эффективности обработки данных.
Основная цель проектирования БД – это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте.
Таким образом, при проектировании базы данных решаются две основные проблемы:
Отображение объектов предметной области в абстрактные объекты модели данных так, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.). Часто эту проблему называют проблемой логического проектирования баз данных.
Обеспечение эффективного выполнения запросов к базе данных, т.е. рациональное расположение данных во внешней памяти, создание полезных дополнительных структур (например, индексов) с учетом особенностей конкретной СУБД. Эту проблему называют проблемой физического проектирования баз данных.
Этапы проектирования
Концептуальное проектирование базы данных
Этап 1. Создание локальной концептуальной модели данных исходя из представлений о предметной области каждого из типов пользователей. Этап включает в себя следующие стадии:
определение типов сущностей;
определение типов связей;
определение атрибутов и связывание их с типами сущностей и связей;
определение доменов атрибутов;
определение атрибутов, являющихся первичными ключами;
создание диаграммы «сущность-связь»;
обсуждение локальных концептуальных моделей данных с конечными пользователями.
Логическое проектирование базы данных (для реляционной модели)
Этап 2. Построение и проверка локальной логической модели данных на основе представления о предметной области каждого из типов пользователей. Этап включает в себя следующие стадии:
определение набора отношений исходя из структуры локальной логической модели данных;
проверка модели с помощью правил нормализации;
проверка модели в отношении транзакций пользователей;
создание диаграмм "сущность-связь";
определение требований поддержки целостности данных;
обсуждение разработанных локальных логических моделей данных с конечными пользователями.
Этап 3. Создание и проверка глобальной логической модели данных. Этап включает в себя следующие стадии:
слияние локальных логических моделей данных в единую глобальную модель данных;
проверка глобальной логической модели данных;
проверка возможностей расширения модели в будущем;
создание окончательного варианта диаграммы «сущность-связь»;
обсуждение глобальной логической модели данных с пользователями.
Физическое проектирование базы данных (с использованием реляционной СУБД)
Этап 4. Перенос глобальной логической модели данных в среду СУБД. Этап включает в себя следующие стадии:
проектирование основных таблиц в среде СУБД;
реализация бизнес-правил предприятия в среде СУБД.
Этап 5. Проектирование физического представления базы данных. Этап включает в себя следующие стадии:
анализ транзакций;
выбор файловой структуры;
определение вторичных индексов;
анализ необходимости введения контролируемой избыточности данных;
определение требований к дисковой памяти.
Этап 6. Разработка механизмов защиты.
разработка пользовательских представлений (видов);
определение прав доступа.
Этап 7. Организация мониторинга и настройка функционирования системы.
Инфологическая модель данных «Сущность-связь»
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка). Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений (например, «Красный», «Синий», «Банановый», «Белая ночь» и т.д.), однако каждому экземпляру сущности присваивается только одно значение атрибута.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся атрибутам. Для сущности Студент ключом может являться атрибут Номер_зачетной_книжки или набор: Фамилия, Имя, Отчество и Год рождения (при условии, что в учебном заведении не будут учиться два однофамильца, родившиеся в одном году).
Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Характеристика связей
При построении инфологических моделей можно использовать язык ER-диаграмм (от англ. Entity-Relationship, т.е. сущность-связь). В них сущности изображаются помеченными прямоугольниками, ассоциации – помеченными ромбами или шестиугольниками, атрибуты – помеченными овалами, а связи между ними – ненаправленными ребрами, над которыми может проставляться степень связи (1 или буква, заменяющая слово "много") и необходимое пояснение.
В ER-диаграммах связь – это линия, соединяющая геометрические фигуры, изображающие сущности, атрибуты, ассоциации и другие информационные объекты. В тексте же этот термин используется для указания на взаимозависимость сущностей. Если эта взаимозависимость имеет атрибуты, то она называется ассоциацией.
Между двумя сущностям, например, А и В возможны три типа связей.
Первый тип – связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В.
Второй тип – связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В.
Третий тип – связь МНОГИЕ-КО-МНОГИМ (М:М): экземпляр одной сущности связан с несколькими экземплярами другой сущности и наоборот, любой экземпляр второй сущности связан с несколькими экземплярами первой сущности.
Ограничения целостности
Целостность (от англ. integrity – нетронутость, неприкосновенность, сохранность, целостность) – понимается как правильность (корректность, правдоподобность, однозначность, непротиворечивость) данных в любой момент времени. Но эта цель может быть достигнута лишь в определенных пределах. Например, нельзя обнаружить, что вводимое значение 5 (представляющее номер дня недели) в действительности должно быть равно 3. С другой стороны, значение 9 явно будет ошибочным и СУБД должна его отвергнуть. Однако для этого ей следует сообщить, что номера дней недели должны принадлежать набору (1,2,3,4,5,6,7), то есть создать домен – указать перечень всевозможных значений того или иного атрибута.
Для того чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений (не путать с незаконными изменениями и разрушениями, являющимися проблемой безопасности). Современные СУБД имеют ряд средств для обеспечения поддержания целостности (так же, как и средств обеспечения поддержания безопасности).
Выделяют четыре вида целостности:
целостность по сущностям (декларативная целостность);
целостность по ссылкам (ссылочная целостность – referential integrity);
целостность, определяемая пользователем (семантическая целостность);
физическая целостность (целостность файлов операционной системы).
Декларативная целостность – целостность по сущностям. Ограничения целостности, необходимые для обеспечения декларативной целостности обычно задаются при объявлении (декларировании, от слова declaration – «объявление») сущности в базе данных.
Для обеспечения декларативной целостности базы данных используются следующие механизмы:
тип данных;
размер типа данных;
опция NOT NULL;
домен;
первичный ключ;
уникальный ключ.
Ссылочная целостность – целостность по ссылкам. Данный вид целостности необходимо обеспечивать, когда данные, находящиеся в нескольких таблицах, связаны между собой и зависят друг от друга (ассоциации и обозначения). Для обеспечения ссылочной целостности базы данных используют внешние (или вторичные) ключи.
Внешний ключ – это набор атрибутов зависимой сущности, по значениям которых можно идентифицировать сущность, с которой она связана. Иными словами, значения атрибутов, входящих в состав внешнего ключа, выбираются из значений атрибутов, составляющий первичный ключ той сущности, на которую ссылается зависимая сущность. В общем случае значения атрибутов, составляющих внешний ключ, могут иметь неопределенные значения (NULL), но если это невозможно по смыслу реализуемой задачи, можно на эти атрибуты наложить дополнительные ограничения целостности, запрещающие использование неопределенных значений.
При указании внешнего ключа, связывающего две сущности, необходимо также определить необходимость выполнения так называемых каскадных действий. Каскадные действия – операции, выполняемые СУБД автоматически (неявно) при возникновении того или иного события, вызванного чаще всего действиями пользователей.
В частности, необходимо определить, что случиться при попытке удаления целевой сущности, на которую ссылается внешний ключ? Например, при удалении поставщика, который осуществил, по крайней мере, одну поставку. Существует три возможности:
Каскадирование: операция удаления «каскадируется» с тем, чтобы удалить также поставки этого поставщика.
Ограничение: удаляются лишь те поставщики, которые еще не осуществляли поставок. Иначе операция удаления отвергается.
Установка: для всех поставок удаляемого поставщика внешний ключ устанавливается в неопределенное значение, а затем этот поставщик удаляется. Такая возможность, конечно, неприменима, если данный внешний ключ не должен содержать NULL-значений.
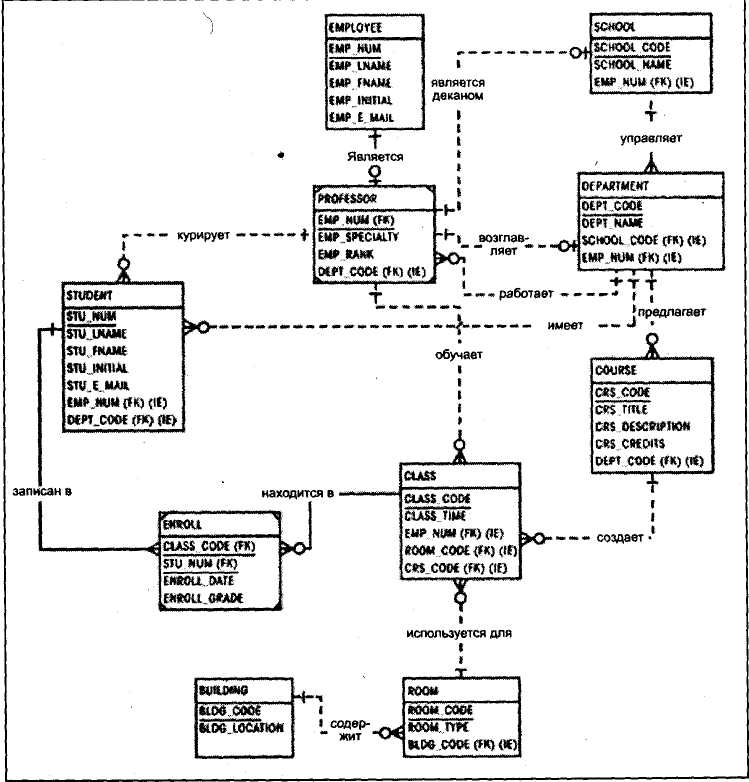
В качестве примера рассматривается пример использования ER-проектирования (модель «птичья лапка») при проектировании системы работы колледжа.
Нормализация и нормальные формы
Понятие полной и транзитивной функциональной зависимостей
Функциональная зависимость (functional dependence – FD) – в отношении R атрибут Y функционально зависит от атрибута Х в том и только в том случае, если каждому значению Х соответствует в точности одно значение Y: R.Х R.Y
Полная функциональная зависимость (full functional dependence – FFD): функциональная зависимость R.Х R.Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества Х (точным подмножеством множества Х называется любое его подмножество, не совпадающее с X).
Транзитивная функциональная зависимость: функциональная зависимость R.Х R.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости R.Х R.Z и R.Z R.Y.
Нормальные формы и нормализация
Нормальные формы (normal forms) – это набор стандартов проектирования данных. Общепринятыми считаются пять нормальных форм. Создание таблиц в соответствии с этими стандартами называется нормализацией.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
первая нормальная форма (1NF);
вторая нормальная форма (2NF);
третья нормальная форма (3NF);
нормальная форма Бойса — Кодда (BCNF);
четвертая нормальная форма (4NF);
пятая нормальная форма, или нормальная форма проекции — соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
каждая следующая нормальная форма улучшает свойства предыдущей;
при переходе к следующей нормальной форме свойства предыдущих сохраняется.
Выполнение правил нормализации обычно приводит к разделению таблиц на две или больше таблиц с меньшим числом столбцов, выделению отношений первичный ключ – внешний ключ в меньшие таблицы, которые снова могут быть соединены с помощью операции объединения.
Одним из основных результатов разделения таблиц в соответствии с правилами нормализации является уменьшение избыточности данных в таблицах. Правила нормализации, подобно принципам объектного моделирования, развивались в рамках теории баз данных.
Первая нормальная форма (1NF) требует, чтобы на любом пересечении строки и столбца находилось единственное значение, которое должно быть атомарным. Кроме того, в таблице, удовлетворяющей первой нормальной форме, не должно быть повторяющихся групп.
Вторая нормальная форма (2NF): отношение R находится во второй нормальной форме в том и только в том случае, когда находится в первой нормальной форме (1NF) и каждый неключевой атрибут полностью зависит от первичного ключа.
Второе правило нормализации требует, чтобы любой неключевой атрибут зависел от всего первичного ключа. Следовательно, таблица не должна содержать неключевых атрибутов, зависящих только от части составного первичного ключа.
Третья нормальная форма (3NF): отношение R находится в третьей нормальной форме в том и только в том случае, если находится во второй нормальной форме (2NF) и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Третья нормальная форма повышает требования второй нормальной формы: она не ограничивается составными первичными ключами. Третья нормальная форма требует, чтобы ни один неключевой атрибут не зависел от другого неключевого атрибута. Любой неключевой атрибут должен зависеть только от первичного ключа.