

4.5 Моделирование данных (idef1x)
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для удобного построения концептуальной схемы.
Концептуальная схема - универсальное представление структуры данных независимое от конечной реализации базы данных и аппаратной платформы.
Использование метода IDEF1X наиболее целесообразно для построения логической структуры базы данных после того, как все информационные ресурсы исследованы (скажем с помощью метода IDEF1) и решение о внедрении реляционной базы данных, как части корпоративной информационной системы, было принято.
Сущность в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друх от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности.
Связи в IDEF1X представляют собой ссылки, соединения и ассоциации между сущностями. Связи это суть глаголы, которые показывают, как соотносятся сущности между собой. Ниже приведен ряд примеров связи между сущностями:
Отдел <состоит из> нескольких Сотрудников
Самолет <перевозит> нескольких Пассажиров.
Сотрудник <пишет> разные Отчеты.

Во всех перечисленных примерах взаимосвязи между сущностями соответствуют схеме один ко многим. Это означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности. Причем первая сущность называется родительской, а вторая - дочерней. В приведенных примерах глаголы заключены в угловые скобки. Связи отображаются в виде линии между двумя сущностями с точкой на одном конце и глагольной фразой, отображаемой над линией.
Отношения многие ко многим обычно используются на начальной стадии разработки диаграммы, например, в диаграмме зависимости сущностей и отображаются в IDEF1X в виде сплошной линии с точками на обоих концах.
Так как отношения многие ко многим могут скрыть другие бизнес правила или ограничения, они должны быть полностью исследованы на одном из этапов моделирования.
Идентификация сущностей. Представление о ключах.
Сущность описывается в диаграмме IDEF1X графическим объектом в виде прямоугольника. На рис.2 приведен пример IDEF1X диаграммы. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены ключевые поля и часть, где расположены неключевые поля. Верхняя часть называется ключевой областью, а нижняя часть областью данных. Ключевая область объекта СОТРУДНИК содержит поле "Уникальный идентификатор сотрудника", в области данных находятся поля "Имя сотрудника", "Адрес сотрудника", "Телефон сотрудника" и т.д.
Ключевая область содержит первичный ключ для сущности. Первичный ключ - это набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над линией в ключевой области. Как следует из названия, неключевой атрибут - это атрибут, который не был выбран ключевым. Неключевые атрибуты располагаются под чертой, в области данных.
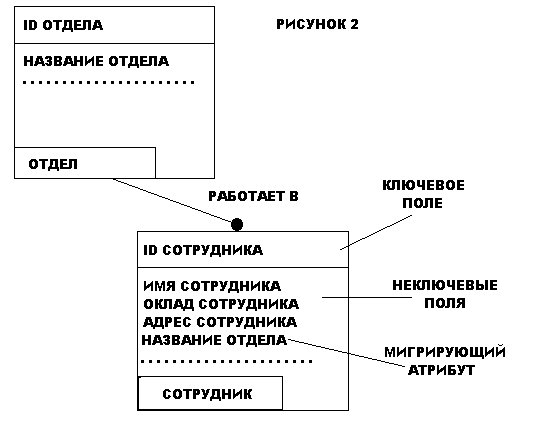
При создании сущности в IDEF1X модели, одним из главных вопросов, на который нужно ответить, является: "Как можно идентифицировать уникальную запись?". Для этого требуется уникальная идентификация каждой записи в сущности для того, чтобы правильно создать логическую модель данных. Напомним, что сущности в IDEF1X всегда имеют ключевую область и, поэтому в каждой сущности должны быть определены ключевые атрибуты.
Выбор первичного ключа для сущности является очень важным шагом, и требует большого внимания.
В качестве первичных ключей могут быть использованы несколько атрибутов или групп атрибутов.
Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты). Кандидаты в ключи должны уникально идентифицировать каждую запись сущности.
В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Правила устанавливают, что атрибуты и группы атрибутов должны:
Уникальным образом идентифицировать экземпляр сущности.
Не использовать NULL значений.
Не изменяться со временем. Экземпляр идентифицируется при помощи ключа. При изменении ключа, соответственно меняется экземпляр.
Быть как можно более короткими для использования индексирования и получения данных.
Если вам нужно использовать ключ, являющийся комбинацией ключей из других сущностей, убедитесь в том, что каждая из частей ключа соответствует правилам.
Для наглядного представления о том, как целесообразно выбирать первичные ключи, приведем следующий пример - выберем первичный ключ для знакомой нам сущности "СОТРУДНИК":
Атрибут "ID сотрудника" является потенциальным ключом, так как он уникален для всех экземпляров сущности СОТРУДНИК.
Атрибут "Имя сотрудника" не очень хорош для потенциального ключа, так как среди служащих на предприятии может быть, к примеру, двое Иванов Петровых.
Атрибут "Номер страхового полиса сотрудника" является уникальным, но проблема в том, что СОТРУДНИКА может не иметь такового.
Комбинация атрибутов "имя сотрудника" и "дата рождения сотрудника" может оказаться удачной для наших целей и стать искомым потенциальным ключом.
После проведенного анализа можно назвать два потенциальных ключа - первый "Номер сотрудника" и комбинация, включающая поля "имя сотрудника" и "Дата рождения сотрудника". Так как атрибут "Номер сотрудника" имеет самые короткие и уникальные значения, то он лучше других подходит для первичного ключа.
При выборе первичного ключа для сущности, разработчики модели часто используют дополнительный (суррогатный) ключ, т.е. произвольный номер, который уникальным образом определяет запись в сущности. Атрибут "Номер сотрудника" является примером суррогатного ключа. Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. К тому же суррогатные ключи могут автоматически генерироваться системой так, чтобы нумерация была сплошной, т.е. без пропусков.
Потенциальные ключи, которые не выбраны первичными, могут быть использованы в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.
Инверсные входы
В интересах бизнеса также требуется обращать внимание на атрибуты, не являющиеся уникальными, но использующимися для поиска информации в таблице. Эти атрибуты называются инверсными входами. Инверсный вход – это атрибут или группа атрибутов, которые используются для доступа к сущности (так, как если бы они были первичными ключами), однако не обязательно находят только один экземпляр.
К примеру, организации может потребоваться найти служащего по имени, также как и по номеру служащего, несмотря на то что, такой поиск может привести к получению одновременно нескольких записей. Когда вы назначите атрибут инверсным входом, после его названия будет стоять. En .У объекта, как показано ниже, может быть несколько инверсных входов.

Связи и внешние ключи (Relationships and Foreign Key Attributes)
Если сущности в диаграмме ERwin связаны, связь передает ключ (или набор ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними ключами. Внешние ключи определяются как атрибуты первичных ключей родительского объекта, переданные дочернему объекту через их связь.Передаваемые атрибуты называются мигрирующими.
Внешние ключи обозначаются в модели символами (FK), стоящими после названия.

7. Идентификация взаимосвязи в IDEF1X(вверху) и IE (внизу).

8. Объект с мигрировавшим внешним ключом (FK).
Классификация сущностей в IDEF1X . Зависимые и независимые сущности.
Зависимые и независимые сущности.
При разработке вашей модели, вы можете обнаружить сущности, уникальность которых зависит от значений атрибута внешнего ключа. Для этих сущностей (для уникального определения каждой сущности) внешний ключ должен быть частью первичного ключа дочернего объекта (находящегося над линией).
Дочерняя сущность, уникальность которой зависит от атрибута внешнего ключа, называется зависимой сущностью. В примере (рис.8) ИГРОК является зависимой сущностью потому, что его идентификация зависит от сущности КОМАНДА. В IDEF1X зависимые сущности представлены в виде закругленных прямоугольников.
Зависимые сущности далее классифицируются на сущности, которые не могут существовать без родительской сущности (зависимость существования, existence dependent) и сущности, которые не могут быть идентифицированы без использования ключа родителя (сущности, зависящие от идентификации). Сущность ИГРОК принадлежит ко второму типу зависимых сущностей, так как ИГРОКИ могут существовать и без КОМАНДЫ.
Напротив, существуют ситуации в которых сущность зависит от существования другой сущности. Рассмотрим две сущности: ЗАКАЗ, используемый для отслеживания заказов покупателей, и ЭЛЕМЕНТ СПИСКА, который отслеживает отдельные элементы в ЗАКАЗе. Зависимость между этими двумя объектами может быть выражена в качестве ЗАКАЗА <содержащего> один или несколько ЭЛЕМЕНТОВ СПИСКА. В этом случае, ЭЛЕМЕНТ СПИСКА зависит от существования ЗАКАЗА.
Объекты, не зависящие при идентификации от других объектов в модели, называются независимыми объектами. В вышеописанном примере объект КОМАНДА можно считать независимым объектом. В IE и IDEF1X независимые объекты представлены в виде прямоугольников.

9. Не идентифицирующая взаимосвязь в IDEF1X (вверху) и IE (внизу).
Идентификация связей
В IDEF1X концепция зависимых и независимых сущностей усиливается типом взаимосвязей между двумя сущностями. Если вы хотите, чтобы внешний ключ передавался в дочернюю сущность (и, в результате, создавал зависимую сущность), то можете создать идентифицирующую взаимосвязь между родительской и дочерней сущность.
Идентифицирующие взаимосвязи обозначаются сплошной линией между сущностями.
В IDEF1X, как показано на рис.7, в конце линии со стороны дочернего объекта ставится точка. В IE в конце линии со стороны дочернего объекта ставится “куриная лапка”.
Примечание: В стандарте IE нет закругленных углов на объектах. Это IDEF1X символ, добавленный ERwin’ом в стандарт IE для совместимости.
Как вы могли заметить при обсуждении независимых и зависимых сущностей, правила, обозначающие то, что связь является идентифицирующей, определяются идентификацией дочерней сущности за счет использования идентификатора родительской сущности. В нашем примере ФИЛЬМОВ и КОПИЙ ФИЛЬМОВ для идентификации копии мы могли выбрать ее собственный уникальный номер. Однако, мы решили использовать идентификатор ФИЛЬМА и добавить вторую часть (номер копии) для того, чтобы отличить одну копию от другой.
Примечание: Как вы можете обнаружить, существует несколько преимуществ при передачи ключей дочерней сущности за счет идентификации связей, связанных с тем, что при этом упрощаются некоторые запросы к физической системе. Однако существуют и некоторые недостатки. С точки зрения реляционной теории предполагается, что передача ключей не должна происходить таким образом. Вместо этого, каждый сущность должен быть идентифицирована не только при помощи своего первичного ключа, но и при помощи логического дескриптора (handle) или дополнительного ключа, невидимого для пользователя системы. У этой теории существует убедительное доказательство и интересующиеся могут обратиться к работе E.F.Codd и C.J.Date на эту тему.
Неидентифицирующие связи
Неидентифицирующие связи, являющиеся уникальными для IDEF1X, также связывают родительский сущность с дочерней. Неидентифицирующие связи используются для отображения другого типа передачи атрибутов внешних ключей – передача в область данных дочерней сущности (под линией).
Неидентифицирующие связи отображаются пунктирной линией между объектами. Если вы свяжите объекты КОМАНДА и ИГРОК посредством неидентифицирующей связи, то модель будет выглядеть как показано на рис. 9.
Так как переданные ключи в неидентифицирующей связи не являются составной частью первичного ключа дочерней сущность, то этот вид связи не проявляется ни в одной идентифицирующей зависимости. В этом случае и КОМАНДА, и ИГРОК рассматриваются как независимые сущности.
Тем не менее взаимосвязь может отражать зависимость существования, если бизнес правило для взаимосвязи определяет то, что внешний ключ не может принимать значение NULL. Если внешний ключ должен существовать, то это означает, что запись в дочерней сущности может существовать только при наличии ассоциированной с ним родительской записи.
Примечание: Идентифицирующие и неидентифицирующие связи не являются особенностью IE метода. Однако, эта информации включена в вашу ERwin диаграмму в виде сплошной линии связи или пунктирной линии связи для обеспечения совместимости между IE и IDEF1X методами.
Роль (Rolename)
Когда внешние ключи мигрируют от родительской сущности через связь к дочерней сущности, они служат в модели двойную службу. Для понимания обеих ролей, иногда является полезным переименовать передаваемый ключ, для того, чтобы показать, какую он играет роль в дочерней сущности. Имя, назначаемое этому атрибуту, называется ролью.
10. Пример имени
Роли
Внешний ключ ИГРОКа “игрок-команда id.команда id” (рис.10) демонстрирует синтаксис определения и отображения имени роли. Первая половина (перед точкой) – это имя роли. Вторая часть – это собственное имя внешнего ключа, иногда называемое базовым именем.
Примечание: Имена Ролей также используются для совместимости модели с наследуемыми моделями данных, где внешний и первичный ключи имели разные названия.
Роли передаются посредством связи, также, как и другие атрибуты. Например, предположим, что мы расширили пример для того, чтобы показать какие ИГРОКИ забивали голы в различных матчах в сезоне. Имя роли “Игрок-команда-id” передается в сущность РЕЗУЛЬТАТИВНАЯ ИГРА (вместе с любым другим первичным ключом из родительской сущности), как показано ниже.

Диаграмма, показывающая миграцию FK атрибута, имеющего ролевое имя
Определение Сущностей и Атрибутов
Нужно запомнить важное правило о том, что названия объектов должны быть только в единственном числе.
Названия атрибутов тоже должны быть в единственном числе.
Определение сущностей в вашей логической модели – это хороший способ определить назначение сущности и уточнить, какие данные должны войти в эту сущность.
Важно также, чтобы модель была как можно более ясной. Неопределенные сущности или атрибуты могут быть неверно истолкованы.
Составление хорошего определения не такая простая задача, как может показаться с первого взгляда.
Все знают кто такой ПОТРЕБИТЕЛЬ, не правда ли? Попробуйте составить определение сущности ПОТРЕБИТЕЛЬ так, чтобы к нему нельзя было придраться. Самые лучшие определения составляются после анализа точек зрения различных пользователей из области бизнеса и функциональных групп внутри предприятия. Определения, прошедшие под пристальным взором большого количества пользователей, имеют следующие преимущества:
Ясны всему предприятию.
Однозначно определяют цели и задачи, решаемые сущностями.
Упрощают идентификацию “категорий”, групп сущностей, являющихся уникальными, но решающих схожие задачи или управляющих схожими данными.
Описания
Описание должно быть четким и кратким выражением, которое сообщает о том является ли объект именно тем что вы хотели бы определить. Чаще всего такие описания могут быть довольно короткими. Остерегайтесь, однако того, чтобы описания не оказались слишком общими, и не использовали терминов, которые не были определены.
Приведем пару примеров, хорошего описания и спорного.
”ТОВАР – это нечто, имеющее стоимость, определяемую при обмене.”
Это хорошее определение, так как после его прочтения вы понимаете что ТОВАР это то, что можно было бы обменять на что-либо другое. Если, к примеру, кто-нибудь хотел бы дать нам три орешка и пластинку жвачки в обмен на мраморный шарик, то мы бы тогда знали, что шарик является ТОВАРОМ.
”Покупатель – это некто, покупающий что-то в нашей компании”.
Это не очень удачное описание. Вы можете перестать понимать кто такой “некто” если узнаете, что компания продает продукты другим компаниям. С другой стороны, с точки зрения бизнеса, может понабиться привлечение потенциальных покупателей, т. е. не только тех, которые уже покупали что-то в фирме. Стоит также подробнее раскрыть понятие “что-то”, чтобы определить - услуги это, товары, или некая их комбинация.
Комментарии
Вы также можете внести общие комментарии о том, кто ответственен за данное определение, в каком оно находится состоянии, и когда оно последний раз изменялось как часть описания. В некоторых случаях вам также может понадобиться объяснить, чем отличаются имена этого объекта и связанного с ним объекта. Например, ПОКУПАТЕЛЬ может отличаться от ПРЕДПОЛАГАЕМОГО КЛИЕНТА.
Определения Атрибутов
Атрибуты, также как и сущности, должны быть четко определены. Используются те же правила – сравнивая объект с его определением, мы должны понять, подходит ли ему это определение. Однако, вы должны остерегаться таких вещей как “день-открытия-счета”, определенный как “Дата открытия СЧЕТА”. Далее вам может понадобиться пояснить, что подразумевается под словом “открытие”, чтобы сделать определение более четким и законченным.
Определения атрибутов, в общем случае, должны иметь такую же базовую структуру как и определения сущностей. Определения также должны, где только возможно, содержать правила, определяющие возможные значения атрибутов.
Правило подтверждения достоверности (validation rule) определяет набор значений, которые разрешены для использования атрибутом, ограничивает или запрещает домен допустимых значений. Эти значения имеют как абстрактный смысл, так и смысл с точки зрения бизнеса. Вы можете определить любые правила подтверждения достоверности или допустимые значения для атрибута в качестве части атрибута. ERwin может также назначить эти правила для атрибута, использующего домен. Поддерживаемые домены включают в себя текст, номер, дату и BLOB.
.
Пример модели данных
