

5. Подходы к решению задач обработки речевого сигнала в системах распознавания речи
Векторное квантование (ВК), Линейное предсказывающее кодирование (ЛПК) и скрытые Марковские модели (СММ), возможно наряду с процедурой динамического программирования (ДП), оказываются удобными для решения множества проблем в обработке речевого сигнала в традиционной постановке, в том числе – в кодировании, синтезе и распознавании.
Рассмотрим систему для распознавания изолированно произносимых команд ограниченного словаря. В такой системе ДП, или СММ могли бы выполнять роль решателя на уровне слов. Например, СММ можно применять к каждому слову словаря, и таким образом, распознавать их, оценивая вероятность отнесения неизвестного входного речевого паттерна к СММ моделям слов словаря системы. Слово, чья модель имеет наибольшую вероятность, рассматривается как распознанное слово. В такой постановке СММ-решатель имеет такую же точность распознавания как и ДП-решатель.
Векторное квантование используется для кодирования ЛПК-вектора в одну из M* кодовых книг таким образом, что средняя дисперсия квантования минимизируется на некотором типичном обучающем множестве ЛПК-векторов. Для случая использования СММ–решателя, ВК используется как способ кодирования континуального множества ЛПК-векторов ограниченным набором дискретных символов (имеется ввиду, что входное множество ЛПК-векторов с помощью ВК отображается в множество представителей классов, к которым входные векторы относятся).
5.1. Первичная обработка
Первичная обработка на основе линейного предсказания. Линейное предсказывающее кодирование является одним из самых мощных способов эффективного кодирования речевого сигнала. ЛПК кодер дает хорошее качество восстановленной речи при скоростях передачи от 1.2 до 2.4 кбит/сек.
При скорости 2.4 - 9.6 кбит/сек. он соизмерим со стандартными способами кодирования: 64 кбит/сек. ИКМ-кодированием и 32 кбит/сек АДИКМ-кодированием. ЛПК речь часто характеризуется как очень разборчивая, но не высшего качества.
Кодер с линейным предсказанием анализирует временную форму речевого сигнала и восстанавливает модель возбуждения речевого тракта и его передаточную функцию, определяемую конфигурацией речевого тракта. Синтезатор воссоздает речевой сигнал путем пропускания полученного возбуждения через модель речевого тракта. ЛПК синтезатор имеет вид.
Модель речевого тракта описывается выражением:
![]() ,
,
где
![]() – n-й
дискрет на выходе,
– n-й
дискрет на выходе,
![]() – k-й
коэффициент предсказания, G
– коэффициент усиления,
– k-й
коэффициент предсказания, G
– коэффициент усиления,
![]() –
ошибка предсказания, p
– порядок модели.
–
ошибка предсказания, p
– порядок модели.
Выходной сигнал представлен в виде суммы входного сигнала в настоящий момент времени и линейной комбинации p предыдущих выходных отсчетов речевого сигнала. Для каждого последовательного отрезка речи определяется свое семейство коэффициентов. При определении коэффициентов предсказания минимизируется среднее квадратичное значение ошибки.
Передается информация о типе возбуждения, о периоде основного тона, коэффициент усиления (ошибка) и коэффициенты предсказания.
Коэффициенты предсказания вычисляются различными методами, но всегда решается система из p линейных уравнений с p неизвестными коэффициентами. Порядок системы обычно принимается от 6 до 12.
В системах распознавания речи для уменьшения вариативности описания речевого сигнала используется некоторая дополнительная априорная информация, помимо той, которая содержится в самом сигнале. Это информация о психоакустических особенностях человеческого восприятия речи. Так метод перцептивного линейного предсказания (ПЛП) [106,108,109] 5-го порядка, позволяет получить формантные кривые такие же гладкие, как и стандартный ЛПК-кодер 14 порядка.
Преобразования, используемые в методе ПЛП, удобно разделить на две части - получение психоакустически сглаженного спектра и получение параметров голосового тракта, порождающего такой спектр.
Психо-акустическое сглаживание спектра. К основным свойствам психо-акустического восприятия человека относятся следующие два. Во-первых, нелинейная деформация физических шкал частоты и интенсивности в перцептивные шкалы барков и громкости. Во-вторых, разделение непрерывного спектра на небольшое число полос с интеграцией значений спектра в этих полосах [108,109]. Эти свойства и реализуются для получения сглаженного спектра ПЛП.
Спектр исходного сигнала в области частот от 0 до 5 кГц преобразуется в значения выходов восемнадцати фильтров, каждый из которых интегрирует значения спектра во всем диапазоне, взвешенные особой функцией с максимумом на центральной частоте фильтра и убывающей к краям.
Центральные частоты фильтров распределены неравномерно по шкале частот и расстояния между ними увеличиваются с увеличением частоты:
![]() (7.1)
(7.1)
Это
преобразование шкалы частот в шкалу
барков, являющуюся линейной для восприятия
речи. Диапазону
![]() на ней соответствует диапазон
на ней соответствует диапазон
![]() .
Центры шестнадцати фильтров выбираются
равноотстоящими на шкале барков и все
дальнейшие значения частот берутся по
ней.
.
Центры шестнадцати фильтров выбираются
равноотстоящими на шкале барков и все
дальнейшие значения частот берутся по
ней.
Весовая
функция![]() k-го фильтра отличается для различных
фильтров, и ее ширина растет при увеличении
центральной частоты, т.е., при увеличении
k:
k-го фильтра отличается для различных
фильтров, и ее ширина растет при увеличении
центральной частоты, т.е., при увеличении
k:
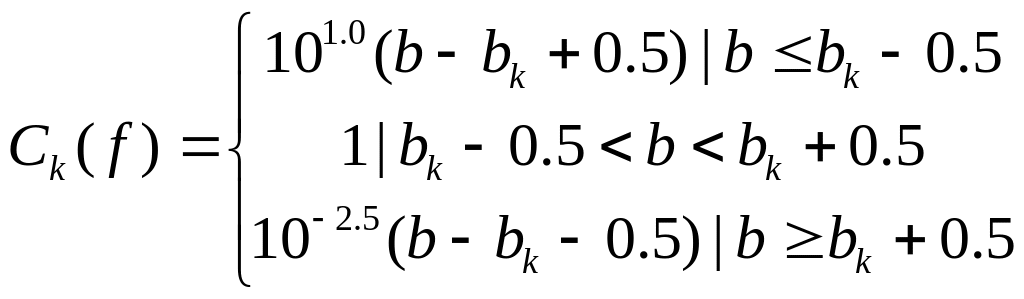 (7.2)
(7.2)
Выходы фильтров умножаются на коэффициенты, получаемые на основе, так называемой, кривой равной громкости и подвергаются извлечению кубического корня, что учитывает различия в восприятии амплитуды сигнала на различных частотах и преобразует шкалу интенсивности в шкалу громкости.
Кривая равной громкости имеет вид:
![]() (7.3)
(7.3)
В
целом выходу k-го фильтра соответствует
следующее преобразование спектра
мощности сигнала
![]() :
:
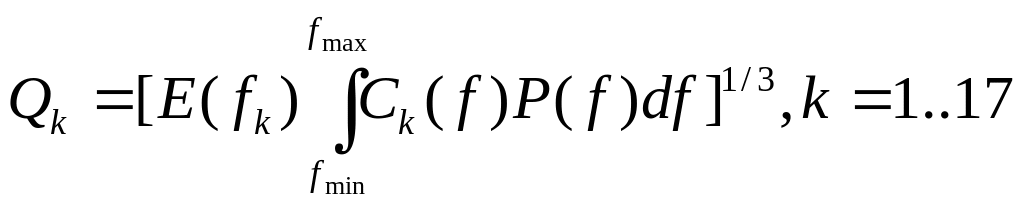 (7.4)
(7.4)
Перцептивно сглаженный спектр мощности сигнала восстанавливается затем при помощи линейной интерполяции между выходами фильтров:
![]() (7.5)
(7.5)
для
![]()
Вычисление
параметров голосового тракта. Можно
представить модель речевого тракта как
цифровой фильтр с конечной импульсной
характеристикой, возбуждаемый сигналами
трех типов - гармоническими колебаниями,
белым шумом и одиночными импульсами
[34,53]. Первые вызывают на выходе фильтра
колебания, соответствующие вокализованным
звукам (гласным), вторые - фрикативным
согласным и третьи - взрывным согласным.
Выход фильтра формируется как результат
свертки входного колебания с импульсной
характеристикой фильтра
![]() .
При этом полагается, что
.
При этом полагается, что
![]() медленно изменяется со временем и на
коротком участке длины
медленно изменяется со временем и на
коротком участке длины
![]() может считаться постоянной.
может считаться постоянной.
Z-преобразование
импульсной характеристики
-
передаточная функция фильтра
![]() может быть приближенно вычислена при
помощи метода кодирования на основе
линейного предсказания [34,53].
может быть приближенно вычислена при
помощи метода кодирования на основе
линейного предсказания [34,53].
Передаточная функция аппроксимируется многополюсной полиноминальной моделью вида:
![]() ,
(7.6)
,
(7.6)
где n-порядок модели.
Такая
модель лишь приближенно интерполирует
реальную передаточную функцию голосового
тракта и позволяет достаточно качественно
моделировать только гласные, поскольку
модель для согласных должна была бы
учитывать еще и нули H(z), т.е. иметь
некоторый полином в числителе. Выбор
такой упрощенной модели (15) продиктован
возможностью легкого вычисления
коэффициентов
![]() .
Коэффициенты
соответствуют коэффициентам линейного
предсказания отсчета сигнала x(t) по n
предшествующим отсчетам:
.
Коэффициенты
соответствуют коэффициентам линейного
предсказания отсчета сигнала x(t) по n
предшествующим отсчетам:
![]() ,
(7.7)
,
(7.7)
Где
![]() - ошибка предсказания, уменьшающаяся
при росте порядка предсказания n.
- ошибка предсказания, уменьшающаяся
при росте порядка предсказания n.
N коэффициентов ЛП могут быть вычислены из n значений автокорреляции сигнала путем решения системы уравнений:
![]() (7.8)
(7.8)
Решение такой системы получается по рекурсивным формулам Дарбина:
![]()
![]() (7.9)
(7.9)
![]()
![]() ,
,
где
![]() ,
,
![]() - коэффициенты ЛП.
- коэффициенты ЛП.
На
практике значения автокорреляции обычно
получают обратным преобразованием
Фурье спектра мощности сигнала
![]() .
В нашем случае обратное преобразование
Фурье соответствует вычислению
автокорреляции. Применение формул
Дарбина (10) к пяти первым коэффициентам
автокорреляции дает пять коэффициентов
линейного предсказания.
.
В нашем случае обратное преобразование
Фурье соответствует вычислению
автокорреляции. Применение формул
Дарбина (10) к пяти первым коэффициентам
автокорреляции дает пять коэффициентов
линейного предсказания.
В качестве конечных параметров, используемых для распознавания, используются пять коэффициентов кепстра [53], в которые пересчитываются коэффициенты ЛП по формуле:
![]() (7.10)
(7.10)
Сравнительное исследование различных метрик используемых при распознавании на основе ПЛП параметров показали [108,109], что для дальнейшего сравнения коэффициентов при распознавании наиболее эффективной является взвешенная евклидова метрика:
![]() . (7.11)
. (7.11)
Векторное
квантование. Наибольшим
преимуществом векторного квантования
для кодирования речи является низкая
скорость передачи, составляющая несколько
сот бит в секунду. В этой парадигме
источник сигнала представляется как
несколько (N)
субисточников, каждый из которых
моделируется стационарным процессом.
В каждый момент времени ключ замкнут
на один из N
субисточников таким образом, что
наблюдаемый процесс демонстрирует
характеристики этого субисточника.
Стандартный алгоритм векторного
квантования предполагает переключение
без запоминания таким образом, что
текущее состояние ключа не зависит от
его предыдущего состояния. Алгоритм
обучения восстанавливает параметры,
характеризующие каждый из субпроцессов,
на основе обучающей выборки из речевых
данных таким образом, что минимизируется
средняя дисперсия. Таким образом, если
мы имеем обучающую выборку
![]() ,
где
,
где
![]() - наблюдаемый вектор размерности m
в момент времени t,
тогда кодовая книга
- наблюдаемый вектор размерности m
в момент времени t,
тогда кодовая книга
![]() определяется таким образом, чтобы
минимизировать
определяется таким образом, чтобы
минимизировать
![]() , (7.12)
, (7.12)
Где
![]() . (7.13)
. (7.13)
Очевидно,
скорость такого квантователя равна
![]() и он достигает средней дисперсии
и он достигает средней дисперсии
![]() за время
за время
![]() .
Выходом векторного квантователя (ВК)
является последовательность индексов
кодовых слов, соответствующих правилу
минимальной дисперсии (2).
.
Выходом векторного квантователя (ВК)
является последовательность индексов
кодовых слов, соответствующих правилу
минимальной дисперсии (2).
ВК
формирует из обучающего множества I
ЛПК-векторов
![]() ,
которые предполагаются хорошо
аппроксимирующими все возможное
множество ЛПК-векторов, формируемых на
входе ВК при произнесении всех возможных
вариантов слов словаря системы всеми
дикторами. Обучающий ВК алгоритм
определяет оптимальное множество
кодовых книг ЛПК-векторов:
,
которые предполагаются хорошо
аппроксимирующими все возможное
множество ЛПК-векторов, формируемых на
входе ВК при произнесении всех возможных
вариантов слов словаря системы всеми
дикторами. Обучающий ВК алгоритм
определяет оптимальное множество
кодовых книг ЛПК-векторов:
![]() ,
такое, что средняя дисперсия, получаемая
при замене любого вектора обучающего
множества на его кодовую книгу
,
такое, что средняя дисперсия, получаемая
при замене любого вектора обучающего
множества на его кодовую книгу
![]() ,
является минимальной.
,
является минимальной.
Если
мы определяем
![]() как ЛПК-меру расстояния между ЛПК-векторами
как ЛПК-меру расстояния между ЛПК-векторами
![]() и
и
![]() :
:
![]() , (7.14)
, (7.14)
где автокорреляционная матрица последовательности, сходящейся к ЛПК-вектору , таким образом, целью ВК обучающего алгоритма является нахождение множества кодовых книг таких, что:
![]() . (7.15)
. (7.15)
Здесь
![]() есть (минимальная) средняя дисперсия
ВК с
есть (минимальная) средняя дисперсия
ВК с
![]() кодовыми книгами.
кодовыми книгами.