

Специальные приложения
Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить. Правила помогают выбирать средства медикаментозного воздействия, определять показания - противопоказания, ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских данных шаблоны, составляющие основу указанных правил.
Молекулярная генетика и генная инженерия
Пожалуй, наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
На развитие генетических исследований выделяются большие средства. В последнее время в данной области возник особый интерес к применению методов Data Mining. Известно несколько крупных фирм, специализирующихся на применении этих методов для расшифровки генома человека и растений.
Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства. Особенно актуальна такая задача при анализе сложных химических соединений, описание которых включает сотни и тысячи структурных элементов и их связей.
Можно привести еще много примеров различных областей знания, где методы Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем, закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей. Данные в указанных областях неоднородны, гетерогенны, нестационарны и часто отличаются высокой размерностью.
Лидеры Data Mining связывают будущее этих систем с использованием их в качестве интеллектуальных приложений, встроенных в корпоративные хранилища данных.
Термин Data Mining, появившийся в 1978 г., оказался удачным и приобрел высокую популярность в современной трактовке примерно с первой половины 90-х годов. Поэтому вполне понятным оказалось стремление разработчиков аналитических приложений, реализующих самые различные методы и подходы, отнести себя к данной категории. Вместе с тем, это не всегда обоснованно.
Например, методы традиционной математической статистики, составляющие основу статистических пакетов, полезны главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP). Главная причина ограниченной эффективности большинства процедур для выявления взаимосвязей в данных, входящих в состав статистических пакетов, – концепция усреднения по выборке, приводящая к операциям над несуществующими величинами (например, средняя температура пациентов по больнице, средняя высота дома на улице, состоящей из дворцов и лачуг и т.п.). Так называемые “многомерные методы” типа дискриминантного, факторного и других подобных видов анализа приходят к конечному результату через операции над фиктивными векторами средних значений, а также ковариационными и корреляционными матрицами. Поэтому, их результаты нередко неточны, грешат подгонкой и отсутствием смысла.
Программные продукты, реализующие нейросетевой подход, также нередко относят к категории Data Mining. Основной недостаток классической нейросетевой парадигмы заключается в том, что нейронная сеть представляет собой “серый” ящик. Во-первых, топология нейросетей здесь задается исходя из эвристических соображений. И, во-вторых, в натренированных нейросетях со сложной топологией веса сотен и тысяч межнейронных связей не поддаются анализу и интерпретации человеком.
Подход, связанный с разработкой так называемых самоорганизующихся (растущих или эволюционирующих) булевых нейросетей, структура которых поддается расшифровке в виде логических высказываний, соответствует целям и задачам Data Mining, но страдает недостатками, в целом присущими эволюционным алгоритмам (они будут охарактеризованы ниже).
Идея систем рассуждений на основе аналогичных случаев (case based reasoning – CBR) на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом “ближайшего соседа” (nearest neighbour). В последнее время распространение получил также термин “memory based reasoning”, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Системы CBR показывают неплохие формальные результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, — в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы. Другой, более серьезный минус заключается в произволе, который допускают системы CBR при выборе меры “близости”. От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза. Кроме того, безосновательным выглядит распространение общей меры близости на выборку данных в целом.
В наибольшей мере требованиям Data Mining удовлетворяют методы поиска логических закономерностей в данных. Их результаты, чаще всего выражаются в виде IF-THEN1 и WHEN-ALSO правил. С помощью таких правил решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных “скрытых” знаний, интерпретации данных, установления ассоциаций в БД и др. Логические методы работают в условиях разнородной информации. Их результаты эффективны и прозрачны для восприятия.
Кратко охарактеризуем подходы, которые применяются для поиска логических правил в данных. При этом сконцентрируем внимание на проблемах, требующих своего решения. Для иллюстрации воспользуемся двумя тестовыми задачами.
Задачи
Задача 1 – “Умение решать простейшие задачи”
Д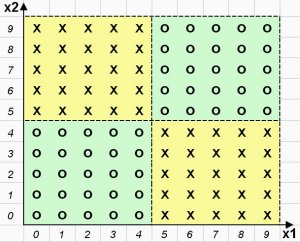 ля
поиска логических закономерностей
предлагается таблица данных, содержащая
100 объектов (строк) и 2 количественных
признака (столбца) Х1, Х2. Таблица разделена
ровно пополам на два класса объектов.
Распределение объектов на плоскости
двух признаков Х1 и Х2 приведено на рис.
2. Объекты 1-класса обозначены крестиком,
а объекты второго класса – ноликом.
ля
поиска логических закономерностей
предлагается таблица данных, содержащая
100 объектов (строк) и 2 количественных
признака (столбца) Х1, Х2. Таблица разделена
ровно пополам на два класса объектов.
Распределение объектов на плоскости
двух признаков Х1 и Х2 приведено на рис.
2. Объекты 1-класса обозначены крестиком,
а объекты второго класса – ноликом.
Рисунок 2. Распределение объектов на плоскости анализируемых признаков
Решение представленной тестовой задачи очевидно. Каждый класс описывается двумя логическими правилами (всего 4 правила):
IF (X1 > 4) и (X2 < 5) THEN Класс 1 – крестики
IF (X1 < 5) и (X2 > 4) THEN Класс 1 – крестики
IF (X1 < 5) и (X2 < 5) THEN Класс 2 – нолики
IF (X1 > 4) и (X2 > 4) THEN Класс 2 – нолики
Как видно, этот простейший тест окажется “неподъемным” для многих известных коммерческих алгоритмов поиска логических закономерностей в данных.
Задача2 – “Умение находить наиболее полные и точные правила”
Принцип формирования этого и подобных тестов следующий.
Матрица объект-признак размера N? p (N – число объектов, р – количество признаков) заполняется нулями и единицами (или любыми другими символами) со случайным равномерным распределением. В этой матрице выбираются участки строк различной длины (комбинации значений признаков), каждый из которых дублируется в матрице определенное число раз строго по вертикали. Тем самым создаются подгруппы объектов, для которых известно логическое правило, описывающее их полностью со 100 % точностью. Наборы подгрупп объединяются в классы, подлежащие распознаванию. Для большей чистоты эксперимента столбцы и строки общей матрицы переупорядочиваются случайным образом. Ставится задача найти в матрице данных введенные известные правила.
В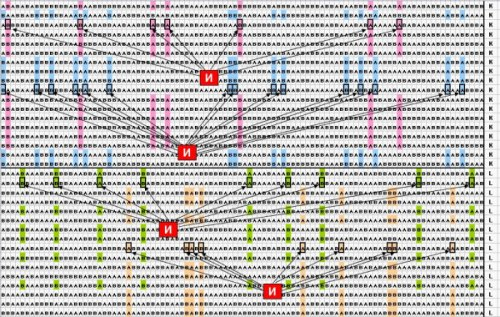 конкретной задаче 2 таблица данных имеет
следующие характеристики: количество
объектов 400 (из них 100 объектов принадлежит
1 классу и 100 – второму, 200 объектов –
случайным образом распределенные
значения), 100 бинарных признаков,
принимающих значения А или В. Требуется
найти 4 известных логических правила,
по 2 правила на каждый класс. Эти правила
представляют собой комбинации от 7 до
15 элементарных логических событий.
Фрагмент таблицы данных приведен на
рис. 3.
конкретной задаче 2 таблица данных имеет
следующие характеристики: количество
объектов 400 (из них 100 объектов принадлежит
1 классу и 100 – второму, 200 объектов –
случайным образом распределенные
значения), 100 бинарных признаков,
принимающих значения А или В. Требуется
найти 4 известных логических правила,
по 2 правила на каждый класс. Эти правила
представляют собой комбинации от 7 до
15 элементарных логических событий.
Фрагмент таблицы данных приведен на
рис. 3.
Рисунок 3. Небольшой фрагмент бинарных тестовых данных
(выделены искомые комбинации значений признаков)
Задача2 далеко не самая трудная из встречающихся на практике. 100 бинарных признаков появляются в анализе, например, когда мы имеем дело всего с 10 исходными количественными признаками, которые при поиске логических закономерностей разбиваются на 10 интервалов каждый. Реальные задачи нередко содержат сотни и даже тысячи количественных, порядковых и категориальных признаков, а логические закономерности могут представлять собой комбинации из десятков и сотен элементарных событий. Если какая-либо система “не умеет” находить правила неограниченной сложности, покрывающие максимально возможные количества объектов собственного класса, то аналитик рискует утонуть в море “обрывков” логических правил.