


174 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B. Amedro et al. |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig. 10.6 Performance over Grid5000, Amazon EC2, and resource mix
execution over Grid5000; even with the balance of load by the partitioner, processes running on EC2 presented lower performance. Using both Grid5000 resources and Extra Large EC2 instances has proved to be more advantageous, presenting, on average, only 15% of overhead for such inter-domain execution when compared with the average of the best single domain ones. This is mainly due to high-latency communication and message tunneling, but this overhead could be further softened because of the possibility of adding extra resources to/from the grid/Cloud.
From a cost-performance point of view, previous performance evaluations of Amazon EC2 [10] showed that MFlops obtained per dollar spent decreases exponentially with increasing computing cores, and the cost for solving a linear system increases exponentially with the problem size. Our results indicate the same when using Cloud resources exclusively. Mixing resources, however, seems to be more feasible since a trade-off between performance and cost can be reached by the inclusion of in-house resources in computation.
10.5 Dynamic Mixing of Clusters, Grids, and Clouds
As we have seen, mixing Cloud and private resources can provide performance close to that of a larger private cluster. However, doing so in a static way can lead to a waste of resources if an application does not need the computing power during its complete lifetime. We will now present a tool that enables the dynamic use of Cloud resources.
10.5.1 The ProActive Resource Manager
The ProActive Resource Manager is a software for resource aggregation across the network, developed as a ProActive application. It delivers compute units represented
10 An Efficient Framework for Running Applications on Clusters, Grids, and Clouds |
175 |
by ProActive nodes (Java Virtual Machines running the ProActive Runtime) to a scheduler that is in charge of handling a task flow and distributing tasks or accessible resources. Owing to the deployment framework, presented in the Section 3.2, it can retrieve computing nodes using different standards such as SSH, LSF, OAR, gLite, EC2, etc. Its main functions are:
•Deployment, acquisition, and release of ProActive nodes to/from an underlying infrastructure
•Supplying ProActive Scheduler with nodes for task executions, based on required properties
•Maintaining and monitoring the list of resources and managing their states
Resource Manager is aimed at abstracting the nature of a dynamic infrastructure and simplifying effective utilization of multiple computing resources, enabling their exploitation from different providers within a single application. In order to achieve this goal, the Resource Manager is split into multiple components.
The core is responsible for handling all requests from clients and delegating them to other components. Once the request for getting new nodes for computation is received, the core “redirects it to a selection manager.” This component finds appropriate nodes in a pool of available nodes based on criteria provided by clients, such as a specific architecture or a specific library.
The pool of nodes is formed by one or several node aggregators. Each aggregator (node source) is in charge of node acquisition, deployment, and monitoring from a dedicated infrastructure. It also has a policy defining conditions and rules of acquiring/releasing nodes. For example, a time slot policy will acquire nodes only for a specified period of time.
All platforms supported by GCMD are automatically supported by the ProActive Resource Manager. When exploiting an existing infrastructure, the Resource Manager takes into account the fact that it could be utilized by local users, and provides fair resource utilization. For instance, Microsoft Compute Cluster Server has its own scheduler and the ProActive deployment process has to go through it instead of contacting cluster nodes directly. This behavior makes possible the coexistence of ProActive Resource Manager with others without breaking their integrity.
As we mentioned earlier, the node source is a combination of infrastructure and a policy representing a set of rules driving the deployment/release process. Among several such predefined policies, two have to be mentioned. The first addresses a common scenario when resources are available for a limited time. The second is a balancing policy – the policy that holds the number of nodes depending on the user’s needs. One such balancing policy is implemented by the Proactive Resource Manager, which acquires new nodes dynamically when the scheduler is overloaded and releases them as soon as there is no more activity in the scheduler.
Using node sources as building blocks helps to describe all resources at your disposal and the way they are used. Pluggable and extensible policies and infrastructures make it possible to define any kind of dynamic resource aggregation scenarios. One of such scenario is Cloud bursting.
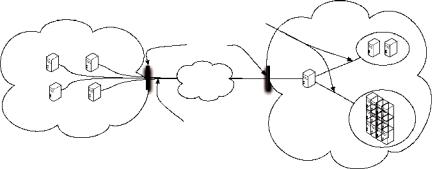
176 |
B. Amedro et al. |
10.5.2 Cloud Bursting: Managing Spike Demand
Companies or research institutes can have a private cluster or use Grids to perform their daily computations. However, the provisioning of these resources is often done based on average usage for cost management reasons. When a sudden increase in computation arises, it is possible to offload some of them to a Cloud. This is often referred to as Cloud bursting.
Figure 10.7 illustrates a Cloud bursting scenario. In our example, we have an existing local network that is composed of a ProActive Scheduler with a Resource Manager. This resource manager handles computing resources such as desktop machines or clusters. In our figure, these are referred to as local computing nodes.
A common kind of application for a scheduler is a bag of independent tasks (no communication between the tasks). The scheduler will retrieve a set of free computing nodes through the resource manager to run pending tasks. This local network is protected from Internet with a firewall that filters connections.
When the scheduler experiences an uncommon load, the resource manager can acquire new computing nodes from Amazon EC2. This decision is based on a scheduling loading policy, which takes into account the current load of the scheduler and the Service Level Agreement provided. These parameters are directly set in the resource manager administrator interface. However, when offloading tasks to the Cloud, we have to pay attention to the boot delay that implies a waiting time of few minutes between a node request and its availability for the scheduler.
The Resource Manager is capable of bypassing firewalls and private networks by any of the approaches presented in Section 3.3.3.
10.5.3 Cloud Seeding: Dealing with Heterogeneous Hardware and Private Data
In some cases, a distributed application, composed of dependent tasks, can perform a vast majority of its tasks on a Cloud, while running some of them on a local
|
RMI Connections |
Local network |
|
|
|
Amazon EC2 |
Firewalls |
|
|
INTERNET |
Local computing |
|
nodes |
|
|
|
ProActive |
EC2 computing |
|
Scheduler & |
|
Resource Manager |
|
instances |
HTTP Connections |
Fig. 10.7 Example of a Cloud bursting scenario