

160 |
L. Shang et al. |
|
6000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
No fault |
|
|
|
|
|
|
|
|
5000 |
|
|
|
10% fault |
|
|
|
|
|
|
|
|
|
|
|
|
20% fault |
|
|
|
|
|
|
|
|
4000 |
|
|
|
|
|
|
|
|
|
|
|
Time |
|
|
|
|
|
|
|
|
|
|
|
|
Elapsed |
3000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
|
|
|
|
|
|
02 |
2.5 |
3 |
3.5 |
4 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
|
|
|
|
|
|
|
|
q |
|
|
|
|
|
Fig. 9.10 |
Schedule mechanism in YML-PC |
|
|
|
|
|
|
|||||
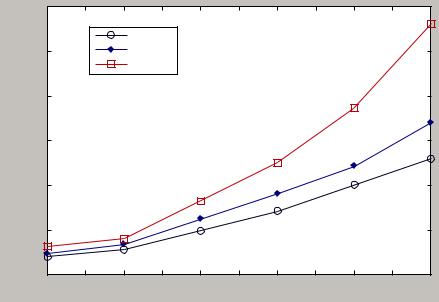
faults happen on the computing nodes. In other words, the trust model is totally correct. ‘10% faults’ stands for 10% of computing nodes in cloud platform fail during the process of program execution. In other words, the accurate rate of trust model is 90%. ‘20% faults’ stands for 20% of computing nodes in cloud platform failing during program execution. In other words, the accurate rate of trust model is 80%.
Figure 9.10 tells us that choosing appropriate computing resources to execute tasks is very important. Improper match-making between computing resources and tasks will decrease efficiency greatly. So, monitoring the computing resources in cloud computing is very important and we had better find the regularity behind its appearance through monitoring. Trust model in paper [25] can be utilized in cloud platform and it can be improved by adopting a better behavior model to describe users’ behavior regularity.
9.5 Conclusion and Future Work
Cloud computing has gained great success for search engines, social e-networks, e-mail, and e-commercial. Amazon can provide different levels of computing resources to users by the way of pay-by-use. Many research institutes, such as the University of Berkeley, Delft University of Technology, and so on, have made
9 A Reference Architecture Based on Workflow for Building Scientific Private Clouds |
161 |
evaluations on Amazon cloud platform. At the same time, Kondo et al try to evaluate the cost-benefits of public Clouds and Desktop Grid platform and conclude that Desktop Grid platform is promising and can be the base of cloud platform. So, based on the research mentioned above and real situation of non-big enterprises and research institutes in China, this paper extended the YML framework and presented YML-PC, which is a workflow-based framework for building scientific private Clouds. The project YML-PC will be divided into three steps: (1) Build private Clouds based on YML through harnessing dedicated computing resources and volunteer computing resources and make them work together with high efficiency. (2) Extend YML to support Hadoop and run Hadoop on cluster-based virtual machines. (3) Combining step 1 and step 2, build a hybrid Cloud based on YML. This paper focused on step 1. To improve the efficiency of YML-PC, “trust model” and “data persistence mechanism” are introduced in this paper. Simulations demonstrate that our idea is appropriate for building YML-PC.
Future work will focus on developing components to make YML-PC a reality. Then, more users’ behavior models will be researched to improve the accuracy of prediction on available “time slot” of volunteer computing nodes. Fault-tolerant-based schedule mechanism is another key issue of our future work. A new idea, which is to deploy virtual tool (Xen, VMware for example) on volunteer computing resources and form several virtual machines on volunteer computing node, is also to be evaluated.
References
1.Ostermann S et al Early cloud computing evaluation. http://www.pds.ewi.tudelft.nl/_iosup/
2.Armbrust M, Fox A, Griffith R, Joseph A, Katz R, Konwinski A, Lee G, Patterson D, Rabkin A, Stoica I, Zaharia M (2009, Feb 10) Above the clouds: a Berkeley view of cloud computing. Technical Report, University of California, Berkley, USA
3.Garfinkel SL (Aug 2007) An evaluation of Amazon’s grid computing services: EC2, S3 and SQS. Technical Report TR-08-07, Harvard University
4.de Assuncao MD, di Costanzo A, Buyya R (2009) Evaluating the cost-benefit of using cloud computing to extend the capacity of clusters. HPDC ‘09, ACM, pp 141–150
5.Ibrahim S, Jin H, Lu L, Qi L, Wu S, Shi X (2009) Evaluating MapReduce on virtual machines: The Hadoop case. CloudCom 2009, pp 519–528
6.David P (2006) Anderson, Gilles Fedak: the computational and storage potential of volunteer computing. CCGRID 2006, pp 73–80
7.Heien EM, Anderson DP (2009) Computing low latency batches with unreliable workers in volunteer computing environments. J Grid Comput 7(4):501–518
8.Javadi B, Kondo D, Vincent JM, Anderson DP (Sept 2009) Mining for statistical models of availability in large scale distributed systems: an empirical study of SETI@home. 17th IEEE/ ACM MASCOTS 2009, London, UK
9.Ma X, Vazhkudai SS, Zhang Z (December 2009) Improving data availability for better access performance: a study on caching scientific data on distributed desktop workstations. J Grid
Comput 7(4):419–438
10. Kondo D, Javadi B, Malecot P, Cappello F, Anderson DP (2009) Cost-benefit analysis of Cloud Computing versus desktop grids. ipdps, pp 1–12
11.Andrzejak A, Kondo D, Anderson DP (2010) Exploiting non-dedicated resources for cloud computing. In the 12th IEEE/IFIP (NOMS 2010), Osaka, Japan, 19–23 April 2010
162 |
L. Shang et al. |
12. Domingues P, Araujo F, Silva L (2009) Evaluating the performance and intrusiveness of virtual machines for desktop grid computing, IPDPS, 23–29 May 2009, pp 1–8
13. Vincenzo D (2009) Cunsolo, Salvatore Distefano, Antonio Puliafito, Marco Scarpa: Cloud@ Home: bridging the gap between volunteer and cloud computing. ICIC (1):423–432
14. Delannoy O, Emad N, Petiton SG (2006) Workflow global computing with YML. In: The 7th IEEE/ACM international conference on grid computing, pp 25–32
15. Delannoy O (Sept 2008) YML: a scientific workflow for high performance computing. Ph.D. thesis, Versailles
16. Delannoy O, Petiton S (2004) A peer to peer computing framework: design and performance evaluation of YML. In: third international workshop on HeterPar 2004, IEEE Computer Society Press, pp 362–369
17. Choy L, Delannoy O, Emad N, Petiton SG (2009) Federation and abstraction of heterogeneous global computing platforms with the YML framework, cisis, pp 451–456. In: The international conference on complex, intelligent and software intensive systems, 2009
18. Caron E, Desprez F, Loureiro D, Muresan A (2009) Cloud computing resource management through a grid middleware: a case study with DIET and eucalyptus. Cloud, pp 151–154
19. Sato M, Boku T, Takahashi D (2003) OmniRPC: a Grid RPC system for parallel programming in cluster and grid environment. In: the 3rd IEEE international symposium on cluster computing and the grid, pp 206–213
20.Germain C, eri VN¢, Fedak G, Cappello F (2000) Xtremweb: building an experimental platform for global computing. In: Buyya R, Baker M (eds) GRID, ser. lecture notes in Computer Science, vol 1971. Springer, Heidelberg, pp 91–101
21. Wang L, Tao J, Kunze M, Castellanos AC, Kramer D, Karl W (2008) Scientific cloud computing: early definition and experience. In the 10th IEEE international conference on HPCC, pp 825–830
22. Foster I, Zhao Y, Raicu I, Lu S (2008) Cloud computing and grid computing 360-degree compared. In Grid computing environments workshop, pp 1–10
23. Vecchiola C, Pandey S, Buyya R (2009) High-performance cloud computing: a view of scientific applications. In the 10th international symposium on pervasive systems, algorithms and networks (I-SPAN 2009), Kaohsiung, Taiwan, December 2009
24. Jha S, Merzky A, Fox G ( June 2009) Using clouds to provide grids with higher levels of abstraction and explicit support for usage modes. Concurr Comput Pract Exper 21(8): 1087–1108
25. Shang L, Wang Z, Zhou X, Huang X, Cheng Y (2007) Tm-dg: a trust model based on computer users’ daily behavior for desktop grid platform. In CompFrame ’07: proceedings of the 2007 symposium on component and framework technology in high-performance and scientific computing, ACM, New York, USA, pp 59–66
26. Smets P (1990) The transferable belief model and other interpretations of Dempster-Shafer’s model. In the proceedings of the sixth annual conference on uncertainty in artificial intelligence, pp 375–384, 27–29 July 1990
27. Shang L, Wang Z, Petiton SG (2008) Solution of large scale matrix inversion on cluster and grid. In proceedings of the 2008 seventh international conference on grid and cooperative computing (GCC), 24–26 October 2008, pp 33–40
28. Shang L, Petiton S, Hugues M (2009) A new parallel paradigm for block-based Gauss-Jordan algorithm (gcc). In the eighth international conference on grid and cooperative computing, pp 193–200
29. Cappello F et al (2005) Grid’5000: a large scale and highly reconfigurable grid experimental testbed. In the 6th IEEE/ACM international conference on grid computing, pp 99–106

Chapter 10
An Efficient Framework for Running Applications on Clusters, Grids, and Clouds
Brian Amedro, Françoise Baude, Denis Caromel, Christian Delbé, Imen Filali, Fabrice Huet, Elton Mathias, and Oleg Smirnov
Abstract Since the appearance of distributed computing technology, there has been a significant effort in designing and building the infrastructure needed to tackle the challenges raised by complex scientific applications that require massive computational resources. This increases the awareness to harness the power and flexibility of Clouds that have recently emerged as an alternative to data centers or private clusters. We describe in this chapter an efficient high-level Grid and Cloud framework that allows a smooth transition from clusters and Grids to Clouds. The main lever is the ability to move application infrastructure-specific information away from the code and manage them in a deployment file. An application can thus easily run on a cluster, a grid, or a cloud, or any mix of them without modification.
10.1 Introduction
Traditionally, HPC relied on supercomputers, clusters, or more recently, computing grids. With the rise of cloud computing and effective technical solutions, questions such as “is cloud computing ready for HPC” or “does a computing cloud constitute a relevant reservoir of resources for parallel computing” are around. This chapter gives some concrete answers to such questions. Offering a suitable middleware and associated programming environment to HPC users willing to take advantage of cloud computing is also a concern that we address in this chapter. One natural solution is to extend a grid computing middleware in such a way that it becomes able to harness cloud computing resources. A consequence is that we end up with a middleware that is able to unify resource acquisition and usage of grid and Cloud resources. This middleware was specially designed to cope with HPC computation and communication requirements, but its usage is not restricted to this kind of application.
B. Amedro (*)
OASIS Research Team, INRIA Sophia Antipolis, 2004 route des lucioles – BP 93, 06902 Sophia-Antipolis, France
e-mail: brian.amedro@sophia.inria.fr
N. Antonopoulos and L. Gillam (eds.), Cloud Computing: Principles, |
163 |
Systems and Applications, Computer Communications and Networks,
DOI 10.1007/978-1-84996-241-4_10, © Springer-Verlag London Limited 2010