

142
(MB/s) |
100 |
|
|
|
|
Average |
80 |
|
60 |
|
|
|
|
|
Throughout |
40 |
|
0 |
0 |
|
|
20 |
|
(MB/s) |
100 |
|
|
|
|
Average |
80 |
|
60 |
|
|
|
|
|
Throughout |
40 |
|
0 |
0 |
|
|
20 |
|
F. Pamieri and S. Pardi
50 |
100 |
150 |
200 |
250 |
300 |
350 |
400 |
450 |
500 |
|
|
|
|
Trials |
|
|
|
|
|
50 |
100 |
150 |
200 |
250 |
300 |
350 |
400 |
450 |
500 |
|
|
|
|
Trials |
|
|
|
|
|
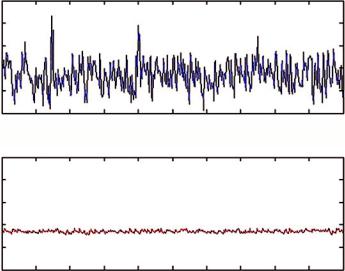
Fig. 8.6 Connection-stability comparison
We also examined the end-to-end connection stability by copying the same data volumes (500 GB) between the SANs, both in the presence of a virtual connection and without it. In the following graphs (Fig. 8.6), we have compared the average throughput observed in the first best-effort transfer operation (where an average throughput of 300 Mbps is achieved) and when the same bandwidth is reserved across the cloud sites. In both the sessions, we were able to transfer the whole 500 GB of data in approximately the same time (about 4 h) with an average throughput of 34 MB/s (about 272 Mbit/s versus the theoretical 300 Mbit/s), but with a standard deviation equal to 1.13 against a value of 12.0 of the best-effort case.
This demonstrated the much higher stability of the virtual circuit arrangement exhibiting a guaranteed bandwidth within a 10% range.
8.6 Related Work
To the best of our knowledge, few experiences about network-empowered cloud infrastructures can be found in the literature. One of the most interesting approaches [14] focuses on the migration of virtual machines and proposes a scheduling model to minimize the migration-related risks of network congestions with respect to bandwidth-demand fluctuations. A more experimental approach is presented in [15], where an effective large-scale cloud testbed called the Open Cloud Testbed (OCT) is proposed. In contrast with other cloud testbeds spanning small geographic areas and communicating through commodity Internet services, the OCT is
8 Enhanced Network Support for Scalable Computing Clouds |
143 |
a wide-area testbed based on four data centers that are connected with a highperformance 10-Gbps network, based on a foundation of dedicated lightpaths. However, such an infrastructure, even if empowered by a high-performance network, does not provide dynamic bandwidth allocation mechanisms driven by the application requirements, and its network-management facilities are limited to basic monitoring. Other interesting issues regarding the benefits of a networkaware approach can be found in [16], where the authors present the performance improvements obtained through network resource engineering in running bioinformatics application such as Lattice-Boltzmann simulations and DNA analysis. Other examples of the introduction of a network-aware philosophy in high-performance distributed computing systems are described in [17–21]. Finally, there is an active open discussion about “End-to-end Network Service Level agreements (SLAs)” within the EGEE project [22] exploring several strategies for advanced networkservices provision and analyzing the benefits of using specific SLAs for the most demanding applications.
8.7 Conclusions
We introduced a new network-centric cloud architecture in which the traditional resource-management facilities can be extended with enhanced end-to-end connectivity services that are totally under the control of the cloud control logic. Such framework enables simple and affordable solutions that facilitate vertical and horizontal communication, achieved through proper interfaces and software tools between the existing network control plane and provisioning systems and the applications requiring dynamic provisioning of high bandwidth and QoS. Accordingly, we proposed and developed a new service-oriented abstraction based on the existing web services architecture and built on the WSRF framework,which introduces a new network control layer between the cloud customers and the network infrastructure, decoupling the connection service provisioning from the underlying network implementation. Such a control layer provides the necessary bridge between the cloud and its data-transfer facilities so that the capabilities offered by the combination of the features of modern network and distributed computing systems greatly enhance the ability to deliver cloud services according to specific SLAs and strict QoS requirements.
References
1.Amazon: Amazon elastic compute cloud. http://aws.amazon.com/ec2/. Accessed Dec 2009
2.Amazon: Amazon simple storage service. http://aws.amazon.com/s3/. Accessed Dec 2009
3.Rosen E, Viswanathan A, Callon R (2001) Multiprotocol label switching architecture. IETF RFC 3031
4.Mannie E (2004) Generalized multi-protocol label switching (GMPLS) architecture. IETF RFC 3945
5.Jamoussi B et al (2002) Constraint-based LSP setup using LDP. IETF RFC 3212
144 |
F. Pamieri and S. Pardi |
6.Berger L (2003) Generalized multi-protocol label switching signaling resource ReserVation Protocol-Traffic Engineering (RSVP-TE) extensions. IETF RFC 3473
7.Czajkowski K, Ferguson DF, Foster I, Frey J, Graham S, Maguire T, Snelling D, Tuecke S (2004) From open grid services infrastructure to WS-resource framework: refactoring & evolution. http://www-106.ibm.com/ developerworks/library/ws-resource/ogsi_to_wsrf_1.0.pdf. Accessed Dec 2009
8.Rajagopalan B et al (ed) (2000) User Network Interface (UNI) 1.0 signaling specification. OIF2000.125.3
9.gLite: Lightweight middleware for grid. http://glite.web.cern.ch/glite/. Accessed Dec 2009
10.OpenNebula: The open source toolkit for cloud computing. http://www.opennebula.org/. Accessed Dec 2009
11.Dean J, Ghemawat S (2004) MapReduce: simplified data processing on large clusters. Proceedings of 6th symposium on operating system design and implementation (OSDI), pp 137–150
12.Hadoop: The Hadoop Project. http://hadoop.apache.org/core/. Accessed Dec 2009
13.eyeOS: The open source cloud’s web desktop. http://eyeos.org/. Accessed Dec 2009
14.Stage A, Setze T (2009) Network-aware migration control and scheduling of differentiated virtual machine workloads, Proceedings of the ICSE workshop on software engineering challenges of cloud computing, IEEE Comsoc
15.Grossman RL, Gu Y, Michal Sabala M, Bennet C, Seidman J, Mambretti J (2009) The open cloud testbed: a wide area testbed for cloud computing utilizing high performance network services. CoRR abs/0907.4810
16.Coveneya PV, Giupponia G, Jhab S, Manosa S, MacLarenb J, Picklesc SM, Saksenaa RS, Soddemannd T, Sutera JL, Thyveetila M, Zasadaa SJ (2009) Large scale computational science on federated international grids: the role of switched optical networks. Future Gen Comput Syst 26(1):99–110
17.Hao F, Lakshman TV, Mukherjee S, Song H (2009) Enhancing dynamic cloud-based services using network virtualization. Proceedings of VISA ‘09: the 1st ACM workshop on Virtualized infrastructure systems and architectures, Barcelona, Spain
18.Bradley S, Burstein F, Gibbard B, Katramatos D et al. (2006) Data sharing infrastructure for peta-scale computing research. Proceedings of CHEP, Mumbai, India
19.Nurmi D, Wolski R, Grzegorczyk C, Obertelli G, Soman S, Youseff L, Zagorodnov D (2008) Eucalyptus: a technical report on an elastic utility computing architecture linking your programs to useful systems. UCSB CS Technical Report #2008–2010
20.Palmieri F (2006) GMPLS-based service differentiation for scalable QoS support in all-optical GRID applications, Elsevier. Future Gen Comp Syst 22(6):688–698
21.Palmieri F (2009) Network-aware scheduling for real-time execution support in data-intensive optical Grids. Future Gen Comp Syst 25(7):794–803
22.The EGEE Project: Advanced Services: End-to-end Network Service Level agreements (SLAs). http://technical.eu-egee.org/index.php?id=352. Accessed Dec 2009

Chapter 9
YML-PC: A Reference Architecture
Based on Workflow for Building
Scientific Private Clouds
Ling Shang, Serge Petiton, Nahid Emad, and Xiaolin Yang
Abstract Cloud computing platforms such as Amazon EC2 provide customers flexible, on-demand resources at low cost. However, while the existing offerings are useful for providing basic computation and storage resources, they fail to consider factors such as security, custom, and policy. So, many enterprises and research institutes would not like to utilize those public Clouds. According to investigations on real requirements from scientific computing users in China, the project YML-PC has been started to build private Clouds and hybrid Clouds for them. In this paper, we will focus on the first step of YML-PC to present a reference architecture based on the workflow framework YML for building scientific private Clouds. Then, some key technologies such as trust model, data persistence, and schedule mechanisms in YML-PC are discussed. Finally, some experiments are carried out to testify that the solution presented in this paper is more efficient.
9.1 Introduction
Cloud computing, as a term for internet-based services, was launched by famous IT enterprises (e.g. Google, IBM, Amazon, Microsoft, Yahoo, etc.). It promises to provide on-demand computing power in the manner of services with quick implementation, little maintenance, and lower cost. Clouds aim at being dynamically scalable and offer virtualized resources to end-users through the internet. Solutions deployed in Clouds can be characterized as easy-to-use, pay-by-use, less time to solution, and lower cost. Clouds can be divided into three types: public Clouds, private Clouds, and hybrid Clouds. Generally speaking, public Clouds refer to entities that can provide services to external parties, such as Amazon and Google. Private Clouds are used to provide services to internal users who would not like to
L. Shang (*)
MAP Team, Lifl, Laboratoire d’Informatique Fondamentale de Lille (LIFL), University of Sciences and Technology of Lille, France
e-mail: ling.shang@lifl.fr
N. Antonopoulos and L. Gillam (eds.), Cloud Computing: Principles, |
145 |
Systems and Applications, Computer Communications and Networks,
DOI 10.1007/978-1-84996-241-4_9, © Springer-Verlag London Limited 2010
146 |
L. Shang et al. |
utilize public Clouds for some issues that span over security, custom, confidence, policy, law, and so on. Hybrid Clouds share resources between public Clouds and private Clouds through a secure network.
Scientific computing requires an ever-increasing number of computing resources to deliver for growing sizes of problems in a reasonable time frame, and cloud computing holds promise for the performance-hungry scientific community [1]. Several evaluations have shown that better performance can be achieved at lower cost using Clouds and cloud technology than based on previous technologies. For example, papers [2, 3] make an evaluation of cloud technology on public Clouds (e.g. EC2). Papers [4, 5] evaluate cloud technology based on private Clouds (e.g. clusters in internal research institute). Paper [6] shows the potential to utilize volunteer computing resources to form Clouds. Papers [7–9] present methods to improve the performance of a Desktop Grid platform. Paper [10] analyzes the cost-benefit of cloud computing versus Desktop Grids. Papers [11–13] introduce some Clouds solutions based on volunteer computing resources.
An investigation is made into requirements for building scientific computing environments for non-large enterprises and research institutes in China. Those issues can be summarized as follows: First, most of the enterprises and research institutes have their computing environment, but they suffer from shortage of computing resources. Second, they would not like to spend a lot of money to expand their computing resources. On the other hand, they hope that they can make full use of wasted CPU cycle of individual PCs in labs and offices. Third, they need a high-level programming interface to decrease their costs (time, money) in developing applications that suit computing environments. Last but not least, they would like to utilize their own computing environments for addressing the importance and security of their data. After all, these data are bought from other corporates with high cost and they are required to keep those data secret. To meet these requirements, a project has been started between the University of Science and Technology of Lille, France, and Hohai University, China. Its general goal is to build a private Cloud environment that can provide end-users with a high-level programming interface, and users can utilize computing resources they need without considering where these computing resources come from (i.e. the layer of program interface is independent of the layer of computing resources).
YML [14–16] is a large-scale workflow programming framework, developed by PRiSM laboratories at the university of Versailles and Laboratoire d’Informatique Fondamentale de Lille (LIFL, Grand Large Team, INRIA Futurs) at the University of Science and Technology of Lille. The aim of YML is to provide users with an easy-to-use method to run parallel applications on different distributed computing platforms. The framework can be divided into three parts: end-users interface, YML frontend, and YML backend. End-users interface is used to provide an easy-to-use and intuitive way to submit applications, and applications, can be developed using a workflow-based language, YvetteML. YML frontend is the main part of YML, which includes compiler, scheduler, data repository, abstract component, and implementation component. The role of this
9 A Reference Architecture Based on Workflow for Building Scientific Private Clouds |
147 |
part is to parse parallel programs, into executable tasks and schedule these tasks to appropriate computing resources. YML backend is the layer to connect different Grid and Desktop Grid middleware through different special interfaces, and users can develop these interfaces very easily. The YML is a component-based framework in which components can interact with each other through welldefined interfaces and researchers can add/modify one or several interfaces for other middleware to YML very easily.
Paper [18] presents a method of resource management in Clouds through a grid middleware. Here, we will extend YML to build scientific private Clouds for non-big enterprises and research institutes. We call this project “YML-PC.” Three steps are needed to make this project a reality. The first step is to integrate volunteer computing resources into dedicated computing resources through YML and make them work in co-ordination. Volunteer computing resources can be a supplement to dedicated computing resources and a volunteer computing resources-based platform has the ability to expand computing resource pools dynamically by nature. If dedicated computing resources are not enough for users, volunteer computing resources can be utilized to implement their tasks. But users do not know whether their tasks are run on dedicated computing resources or volunteer computing resources, and they need not know. The key issue of this step is how to allocate tasks to different kinds of computing resources more reasonably and make those computing resources work with high efficiency. The second step is to develop an interface for Hadoop and integrate it into YML. Then, some evaluations will be made on cluster environment + Hadoop. The third step is to try to build a hybrid Clouds environment through combining step one with step two. The solution is that step one can stand for a kind of private Clouds and step two can be deployed on public Clouds, then YML as a workflow-based framework can harness private Clouds and public Clouds.
In this paper, our work focuses on the first step. To do that, our research-in-progress on YML focuses on the following aspects:
•Data flows. Added in the application file. Through adding this flow, data persistence and data replication mechanisms can be realized in YML-PC. Also, it can help to improve the efficiency of the platform greatly.
•Monitor and Trust model. Introduced to monitor the available status of nondedicated computing resources and predict their future status. Also, a method to evaluate expected execution time based on standard virtual machine is adopted. Through this method, heterogeneous computing resources can be changed into homogeneous computing resources and then can be evaluated. According to this evaluation and prediction, tasks can be allocated to appropriate computing resources.
The remainder of this paper is organized as follows: Section 2 is the general introduction of YML. Section 3 describes the design and implementation of the YMLbased private Clouds in detail. In Section 4, some evaluations are made and some related works are discussed. Section 5 gives conclusions and describes future work.