

3 Towards a Taxonomy for Cloud Computing from an e-Science Perspective |
51 |
The architecture characteristics of the environment chosen to execute the experiment should also be taken into account. Scientific experiments need to be monitored and controlled by scientists. This way, the chosen cloud environment should provide characteristics such as monitoring, as well as individual control of an experiment execution independent from others’ executions. Also, in many scenarios the execution of a whole experiment requires running programs in different technological platforms (operational systems, database servers), requiring that the cloud computing environment deals with heterogeneity.
Another important aspect is related to performance. These experiments usually need high-performance computational environments to run. Even using these environments, experiments may need days, weeks, or even months to finish. It is important to know (and classify) the technology infrastructure involved with the experiment to discover if this technology is able to offer the necessary computational resources to execute the entire experiment.
Another important topic is related to how scientists access the cloud environment to run experiments. The in silico scientific experiment must be able to access cloud environments in different ways. For example, in a specific experiment, results must be provided in a web page through a web browser; in another experiment, there must be an API to control the execution of the experiment, and so on.
In silico scientific experiments should be based on standards, ideally already used on the experiment domain or recommended by entities such as W3C [29]. These standards are important when modeling an in silico scientific experiment. Scientific experiments are usually based on open standards. The next section presents the proposed taxonomy for cloud computing that takes into account the aspects listed in this section.
3.3 A Taxonomy for Cloud Computing
A taxonomy [4] is a particular classification arranged in a hierarchical structure. It is typically organized by a parent–child relationship. Originally the term “taxonomy” referred only to the classification of living organisms. However, it has become popular in certain domains of science to apply the term in a wider, more general sense, where it may refer to a classification of things or concepts.
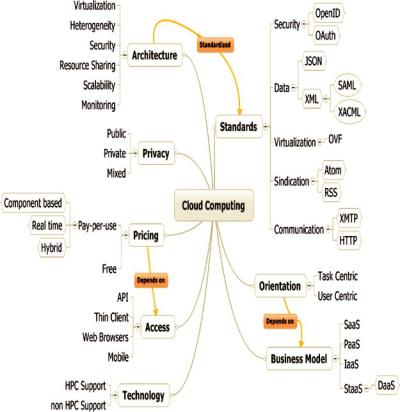
The cloud computing taxonomy presented in this chapter provides the classification of the components of the cloud computing domain into categories based on different aspects of this field and the requirements of a scientific experiment. This section describes a cloud computing taxonomy (presented in Fig. 3.2), which is decomposed into eight subtaxonomies.
The proposed taxonomy classifies the characteristics of cloud computing in terms of architectural characteristics, business model, technology infrastructure, privacy, standards, pricing, orientation, and access. Many of the classes of the taxonomy are interrelated. In Fig. 3.2, these relations are represented in orange arrows. Each one of these relations is explained throughout the chapter.
52 |
D. de Oliveira et al. |
Fig. 3.2 Cloud computing taxonomy
3.3.1 Business Model
According to the business model adopted, clouds are usually classified into three major categories [18] (Fig. 3.3): Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS), creating a model named SPI [34].
In SaaS, the software is deployed by a service provider (just like an application to end-users) for commercial or free use as a service on demand. In IaaS, the provider delivers a computational infrastructure (such as a supercomputer) to the end-user on the web. In IaaS, the end-user is usually responsible for configuring the environment to use. PaaS is the delivery of a programming environment as a Service. The process of delivering platforms as services facilitates the deployment of applications into the cloud.
However, these three categories are too generic. More classification levels are indeed needed. For example, in the e-Science field, the generated data is one of the
3 Towards a Taxonomy for Cloud Computing from an e-Science Perspective |
53 |
Fig. 3.3 Business model subtaxonomy
most valuable resources. This classification does not take into account services that are based on storage or databases.
Thus, the business model subtaxonomy should include the following areas: Storage as a Service (StaaS) and Database as a Service (DaaS), which are fundamental for e-Science and scientific workflows. We may define Storage as a Service as a service that provides structured ways to access and maintain a storage facility that is remotely located. However, this kind of business model provides only the space and structure to store data. In scientific experiments, the scientists usually need a database to store provenance data, because a database provides features such as indexing and concurrency control, that a simple storage does not provide.
This way, Database as a Service (DaaS) provides operations and functions of a remotely hosted database, sharing it with other users, and having it logically function as if the database were local. This way, we may see the Database-as-a-Service as one specialization of Storage-as-a-Service.
The business model directly influences the orientation of the cloud environment. For example, an IaaS business model allows a user-centric environment, since the user is in control. On the other hand, an SaaS business model does not. This class of the taxonomy is essential to guarantee the reproducibility of scientific experiments. The business model directly defines if the cloud environment offers data, infrastructure, or application as a service, essential to guarantee reproducibility. For example, there should be a way to store provenance data to be further analyzed, thus the cloud computing environment should follow DaaS to allow data storage.
3.3.2 Privacy
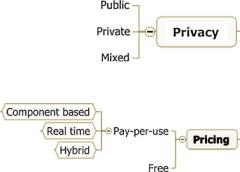
According to the privacy aspect, we may classify cloud environments as private, public, and mixed (Fig. 3.4). Public clouds may be considered as the most traditional of all types. In this kind of cloud, the various resources are dynamically provided over the Internet, via web applications or web services, to any user. Private clouds are environments that emulate cloud computing on private networks, inside a corporation or a scientific institution.
A mixed cloud environment is one that is composed by multiple public and/or private clouds. The concept of mixed cloud is still dubious. Some authors call a mixed cloud also as hybrid [25]. Although this term is not wrong, it is also used to
54 |
D. de Oliveira et al. |
Fig. 3.4 Privacy subtaxonomy
Fig. 3.5 Pricing subtaxonomy
define clouds that are implemented by different technologies [35], which may cause confusion.
This class of the taxonomy is important for e-Science because of the importance of privacy levels in scientific experiments. Programs and data are usually not public and scientists may prefer not to install programs or store data in public environments.
3.3.3 Pricing
Since it is important for the scientific experiments to deal with costs, we must classify cloud environment according to a pricing criterion. This subtaxonomy (Fig. 3.5) is composed of three main types of pricing. Free pricing is the pricing model applied when you are using your own cloud environment, where the resources are freely available for authorized users. The pay-per-use model is the one where the user pays a specific value related to his resource utilization. Also, it can be specialized to a component-based pricing, where each component (storage, CPU, and so on) has a different price and the real-time bill broken down by exact usage of components. These pay-per-use models are usually applied in both commercial clouds and scientific clouds. Science users pay for cloud usage in the same way as commercial users do. To our knowledge, there are no scientific institutions that share their resources at no cost.
Pricing is influenced by access characteristics. Since a cloud environment offers more access methods, each one of them is a component that can be priced by the provider.
3.3.4 Architecture
This subtaxonomy (Fig. 3.6) classifies the main architectural characteristics of a cloud computing environment. One fundamental architectural aspect of a cloud is