

Лекция 25. Элементы регрессионного и корреляционного анализов
К наиболее простым зависимостям тапа Y = f(X) (такие зависимости в литературе еще называют парными) относится подавляющее большинство формул, используемых в естественнонаучных и технических дисциплинах. Такие формулы, как правило, строятся по результатам экспериментов, применяя метод наименьших квадратов. Однако только сейчас с использованием вычислительной техники стало возможным строить парные зависимости оптимальной (в смысле адекватности) формы.
Пусть имеется n пар наблюдений значений зависимой переменной yi – функции отклика, полученных при фиксированных значениях независимой переменной xi – фактора.
xi |
x1 |
x2 |
… |
xn |
yi |
y1 |
y2 |
… |
yn |
Пары (xi, yi) на плоскости можно представить в виде точек с координатами (xi ,yi) (рис.1).
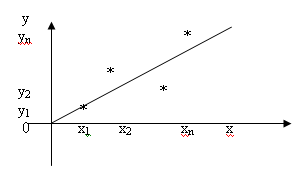
Рис.1
Задача
регрессионного анализа состоит в том,
чтобы, зная положение точек на плоскости,
так провести линию регрессии, чтобы
сумма квадратов отклонений
![]() вдоль оси 0Y
этих точек от проведенной линии была
минимальной. Для проведения регрессионного
анализа к выдвигаемой гипотезе (к форме
уравнения регрессии) выдвигается
требование, чтобы это уравнение было
линейным по параметрам или допускало
линеаризацию. Рассмотрим
сначала процедуру построения линейной
зависимости между фактором и откликом.
вдоль оси 0Y
этих точек от проведенной линии была
минимальной. Для проведения регрессионного
анализа к выдвигаемой гипотезе (к форме
уравнения регрессии) выдвигается
требование, чтобы это уравнение было
линейным по параметрам или допускало
линеаризацию. Рассмотрим
сначала процедуру построения линейной
зависимости между фактором и откликом.
Уравнение
прямой линии на плоскости имеет вид
![]() ,
где
,
где
![]() и
и
![]() – неизвестные постоянные. Тогда задачу
метода наименьших квадратов можно
сформулировать следующим образом –
минимизировать функционал U
по параметрам
и
– неизвестные постоянные. Тогда задачу
метода наименьших квадратов можно
сформулировать следующим образом –
минимизировать функционал U
по параметрам
и
![]() .
(1)
.
(1)
Решение задачи сводится к вычислению значений параметров и , доставляющих функционалу (1) минимальное значение. Необходимое условие экстремума запишем в виде системы (2)
![]() .
(2)
.
(2)
После нахождения производных получим так называемую систему нормальных уравнений (3)
![]() .
(3)
.
(3)
Для нахождения решения системы можно воспользоваться соотношениями (4)
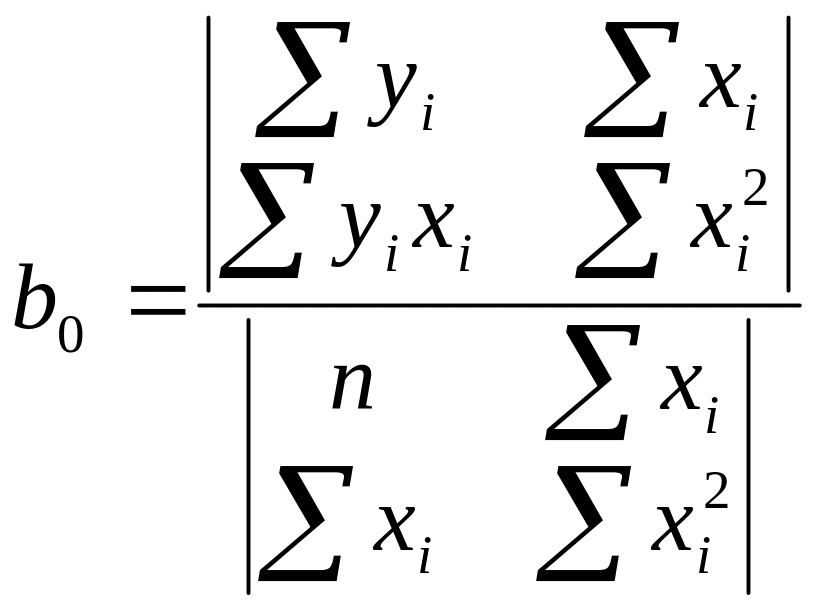 и
и
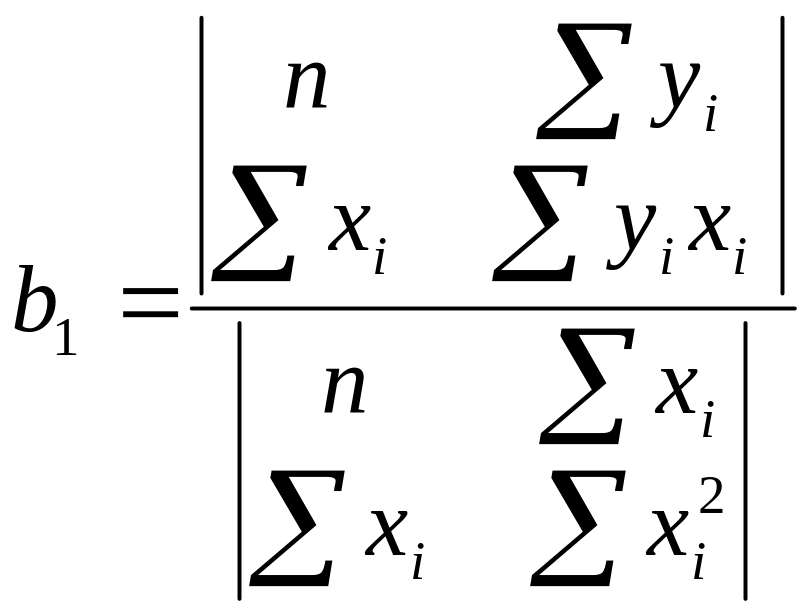 .
(4)
.
(4)
В
общем случае между X
и Y
может быть два вида связи – функциональная
и стохастическая. Первая имеет место,
если точки наблюдения эксперимента
расположены точно на линии регрессии.
При наличии погрешностей измерения –
связь стохастическая. Для функциональной
связи понятие корреляции r
не имеет смысла (коэффициент корреляции
равен 1 при линейной зависимости). Для
стохастической связи вычисление
корреляции между X
и Y
и его оценка – важная статистическая
процедура, которая позволяет судить о
тесноте связи между X
и Y.
Коэффициент корреляции r
может изменяться от –1 до +1. Чем ближе
r
к единице, тем связь между откликом и
фактором теснее. Если X
и Y
имеют нормальное распределение, то
равенство r
нулю означает независимость X
и Y.
X
и Y
имеют две линии регрессии. Одна определяет
зависимость Y
от X,
а вторая – зависимость X
от Y.
Прямые регрессии пересекаются в «центре
тяжести» (![]() )
и образуют «ножницы». Чем уже «ножницы»,
тем ближе стохастическая связь к
функциональной. Это означает, что
уравнение регрессии
)
и образуют «ножницы». Чем уже «ножницы»,
тем ближе стохастическая связь к
функциональной. Это означает, что
уравнение регрессии
![]() не является
алгебраическим, из которого можно
выразить X
через Y.
не является
алгебраическим, из которого можно
выразить X
через Y.
Коэффициент парной корреляции можно определить по формуле (5)
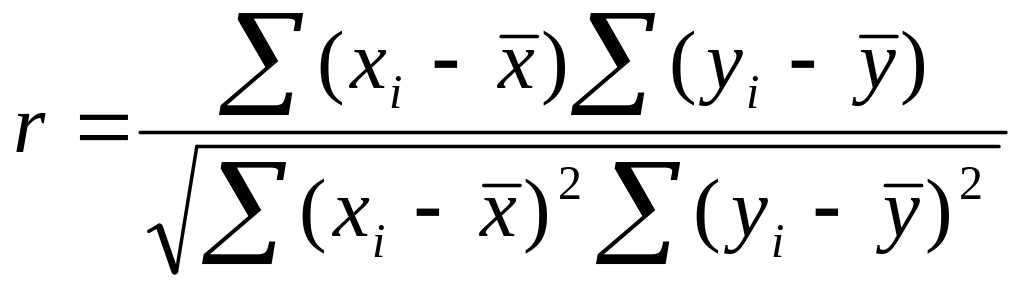 ,
(5)
,
(5)
где и – выборочные средние.
После определения коэффициентов уравнения регрессии и коэффициента корреляции необходимо оценить их статистическую значимость.
Статистическую значимость уравнения регрессии определяют с использованием критерия Фишера. Вычисляют статистику F-критерия по следующему соотношению (6):
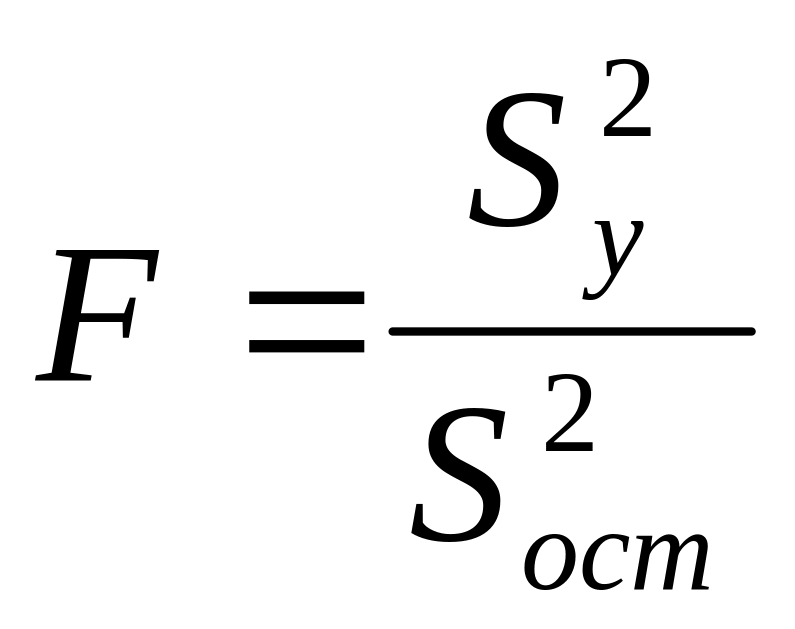 ,
(6)
,
(6)
где
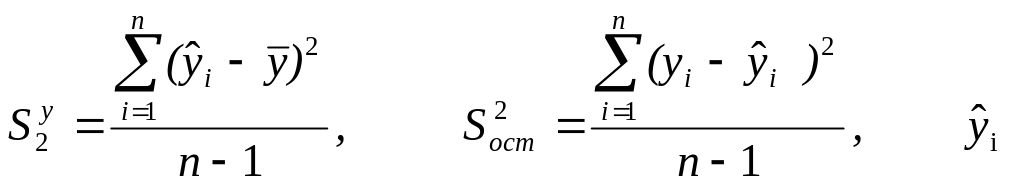
![]() .
.
Далее по таблице приложения находят табличное значение F-критерия при уровне значимости и степенями свободы n – 1, n – 2.
Если F < F(, n – 1, n – 2), то это означает, что уравнение регрессии статистически незначимо и неадекватно описывает результаты эксперимента; в противном случае уравнение регрессии статистически значимо. F-критерий показывает во сколько раз уравнение регрессии предсказывает результаты экспериментов лучше, чем среднее .
Для оценки статистической значимости r используется критерий Стьюдента:
![]() (7)
(7)
Вычисленное
по формуле (7)
![]() сравнивают с табличным – t(n
– 2, ),
если
> t(n
– 2,
),
то нуль гипотезу H0:
r
= 0 отклоняют, т.е. найденное r
статистически значимо отличается от
нуля.
сравнивают с табличным – t(n
– 2, ),
если
> t(n
– 2,
),
то нуль гипотезу H0:
r
= 0 отклоняют, т.е. найденное r
статистически значимо отличается от
нуля.
Статистическую значимость коэффициентов регрессии и также определяют при помощи критерия Стьюдента.
Адекватность модели можно оценить также при помощи коэффициента детерминации:
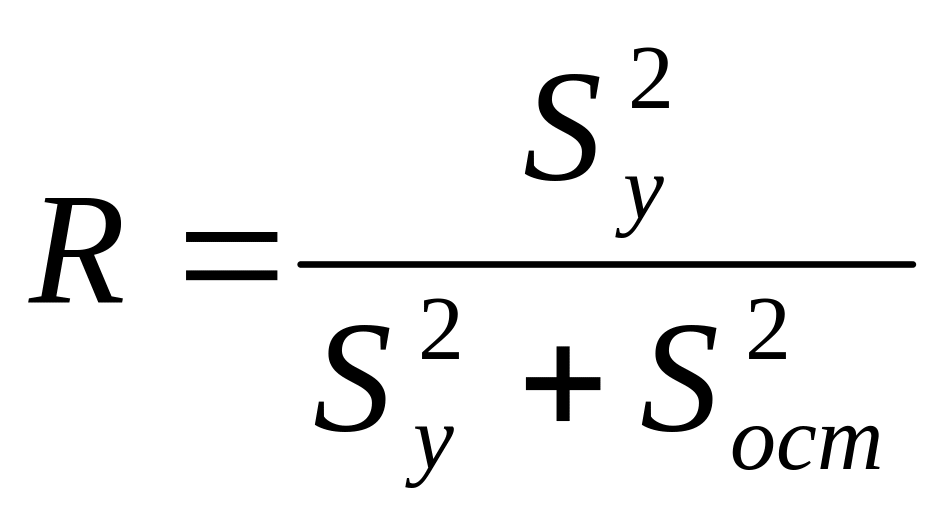 .
(8)
.
(8)
Чем ближе значение R к единице, тем адекватнее уравнение регрессии описывает исследуемый процесс.