

1.
Системы управления базами данных (СУБД)
используются для упорядоченного хранения
и обработки больших объемов информации.
В процессе упорядочения информации
СУБД генерируют базы данных, а в процессе
обработки сортируют информацию и
осуществляют ее поиск.
Информация в базах данных структурирована
на отдельные записи, которыми называют
группу связанных между собой элементов
данных. Характер связи между записями
определяет два основных типа организации
баз данных: иерархический и
реляционный.
В иерархической базе данных записи
упорядочиваются в определенную
последовательность, как ступеньки
лестницы, и поиск данных может
осуществляться последовательным
«спуском» со ступени на ступень.
Иерархическая база данных по своей
структуре соответствует структуре
иерархической файловой системы.
Реляционная база данных, по сути,
представляет собой двумерную таблицу.
Под записью здесь понимается строка
двумерной таблицы, элементы которой
образуют столбцы таблицы. В зависимости
от типа данных столбцы могут быть
числовые, текстовые или содержать дату.
Строки таблицы нумеруются.
Работа с СУБД начинается с создания
структуры базы данных, т. е. с
определения:
• количества столбцов;
• названий столбцов;
• типов столбцов (текст/число/дата);
• ширины столбцов.
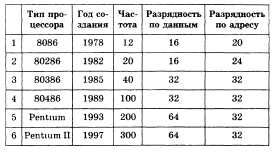
Рассмотрим структуру базы данных на
примере базы данных Процессоры.
Количество столбцов — 5.
Названия и типы столбцов: Тип процессора
(текст), Год создания (дата), Частота
(число), Разрядность по данным (число),
Разрядность по адресу (число). Ширина
каждого столбца устанавливается
пользователем в соответствии с удобством
представления данных на экране.
Структура созданной базы данных может
быть впоследствии изменена (добавлены/удалены
столбцы, изменены их названия и т.
д.).
![]() В созданную «пустую» базу данных
необходимо занести записи и при
необходимости их редактировать. Обычно
предусмотрены следующие режимы:
• добавление записи;
• удаление записи;
• редактирование записи.
Внесем в базу шесть записей, характеризующих
технические характеристики различных
процессоров Каждая запись состоит из
пяти данных различных типов
В созданную «пустую» базу данных
необходимо занести записи и при
необходимости их редактировать. Обычно
предусмотрены следующие режимы:
• добавление записи;
• удаление записи;
• редактирование записи.
Внесем в базу шесть записей, характеризующих
технические характеристики различных
процессоров Каждая запись состоит из
пяти данных различных типов
 Занесенную в базу данных информацию
можно обрабатывать, а именно — осуществлять
следующие операции:
• сортировка по любому столбцу (по
возрастанию/ убыванию чисел, символьных
строк, дат);
• поиск по любому столбцу с различными
условиями (равно, больше, меньше и т.
д.).
Так, в результате выполнения сортировки
по убыванию по столбцу Год создания
порядок записей изменится на
противоположный.
Могут осуществляться вложенные
сортировки, т. е. сортировка 1 уровня по
одному столбцу, в ней сортировка 2 уровня
по другому столбцу и т. д.
В результате выполнения операции поиска
по столбцу Разрядность по данным с
условием "= 32" будут найдены две
записи (80386 и 80486).
Могут осуществляться операции сложного
поиска, когда задаются несколько условий
по разным столбцам. В результате будут
найдены записи, удовлетворяющие всем
заданным условиям.
Созданные базы данных можно
записывать/считывать с диска и
распечатывать на принтере. Это же
относится к результатам операций
сортировки и поиска.
Вид представления записей на экране
-может быть не только табличным, но и
картотечным. В последнем случае каждая
запись выводится в виде определенной
формы. Структура формы одинакова для
всех записей, причем название полей
соответствует названиям столбцов
табличной формы представления базы
данных, а их расположение задается
пользователем.
Занесенную в базу данных информацию
можно обрабатывать, а именно — осуществлять
следующие операции:
• сортировка по любому столбцу (по
возрастанию/ убыванию чисел, символьных
строк, дат);
• поиск по любому столбцу с различными
условиями (равно, больше, меньше и т.
д.).
Так, в результате выполнения сортировки
по убыванию по столбцу Год создания
порядок записей изменится на
противоположный.
Могут осуществляться вложенные
сортировки, т. е. сортировка 1 уровня по
одному столбцу, в ней сортировка 2 уровня
по другому столбцу и т. д.
В результате выполнения операции поиска
по столбцу Разрядность по данным с
условием "= 32" будут найдены две
записи (80386 и 80486).
Могут осуществляться операции сложного
поиска, когда задаются несколько условий
по разным столбцам. В результате будут
найдены записи, удовлетворяющие всем
заданным условиям.
Созданные базы данных можно
записывать/считывать с диска и
распечатывать на принтере. Это же
относится к результатам операций
сортировки и поиска.
Вид представления записей на экране
-может быть не только табличным, но и
картотечным. В последнем случае каждая
запись выводится в виде определенной
формы. Структура формы одинакова для
всех записей, причем название полей
соответствует названиям столбцов
табличной формы представления базы
данных, а их расположение задается
пользователем.
2. Информационные ресурсы сети Интернет: электронная почта, телеконференции, файловые архивы. Всемирная паутина. Глобальная сеть Интернет привлекает пользователей своими информационными ресурсами и сервисами (услугами). В настоящее время услугами Интернета пользуются несколько сотен миллионов человек. Электронная почта. Электронная почта — наиболее распространенный сервис Интернета, так как она является исторически первой информационной услугой компьютерных сетей и не требует обязательного наличия высокоскоростных и качественных линий связи. Любой пользователь Интернета может получить свой «почтовый ящик» на одном из почтовых серверов Интернета (обычно на почтовом сервере провайдера), в котором будут храниться передаваемые и получаемые электронные письма. Чтобы электронное письмо дошло до адресата, оно, кроме текста послания, обязательно должно содержать электронный адрес получателя письма. Адрес электронной почты записывается по определенной форме и состоит из двух частей: имя_пользователя@имя_сервера Имя_пользователя имеет произвольный характер и задается самим пользователем; имя_сервера жестко связано с выбором пользователем сервера, на котором он разместил свой почтовый ящик. Например, имя почтового сервера компании МТУ-Интел — mtu-net.ru. Соответственно имена почтовых ящиков пользователей будут иметь вид: username@mtu-net.ru Чтобы отправить электронное письмо, отправитель должен подключиться к Интернету и передать на свой почтовый сервер сообщение. Почтовый сервер сразу же отправит это письмо через систему почтовых серверов Интернет на почтовый сервер получателя, и оно попадет в его почтовый ящик. Однако получатель получит письмо только после того, как соединится с Интернетом и «скачает» почту из своего почтового ящика на собственный локальный компьютер. Телеконференции. В Интернете существуют десятки тысяч конференций или групп новостей (news), каждая из которых посвящена обсуждению какой-либо проблемы. Любой конференции выделяется свой почтовый ящик на серверах Интернета, поддерживающих работу этой телеконференции. Пользователи могут посылать свои сообщения на любой из этих серверов. Серверы периодически синхронизируются, т. е. обмениваются содержимым почтовых ящиков телеконференций, поэтому материалы конференций в полном объеме доступны пользователю на каждом таком сервере. Принцип работы в телеконференциях мало чем отличается от принципа работы с электронной почтой. Пользователь имеет возможность посылать свои сообщения в любую телеконференцию и читать сообщения, посланные другими участниками. Файловые архивы. Большое количество серверов Интернета содержат файловые архивы. Программное обеспечение, размещаемое на таких серверах, можно разделить на две большие группы: свободно распространяемое программное обеспечение freeware и условно бесплатное программное обеспечение shareware. Многие производители программного обеспечения и компьютерного оборудования заинтересованы в широком бесплатном распространении программного обеспечения. К таким программным средствам можно отнести новые недоработанные (бета) версии программных продуктов, драйверы к новым устройствам или улучшенные драйверы к уже существующим и т. д. В рекламных целях на файловых серверах фирмы часто размещают также условно бесплатное программное обеспечение (программы с ограниченным сроком действия или программы с ограниченными функциональными возможностями). Для работы с серверами файловых архивов можно использовать браузеры, однако удобнее пользоваться специальными программами, которые называются менеджерами загрузки файлов. Всемирная паутина. Всемирная паутина — это десятки миллионов серверов Интернета, содержащих Web-страницы, в которых применяется технология гипертекста. Всемирная паутина — это вольный перевод английского словосочетания World Wide Web, которое часто обозначается как WWW или Web. В основу этой технологии положена технология гипертекста, распространенная на все компьютеры, подключенные к сети Интернет. Суть технологии гипертекста состоит в том, что текст структурируется, т. е. в нем выделяются слова-ссылки. При активизации ссылки (например, с помощью щелчка мышью) совершается переход на фрагмент текста, заданный в ссылке. Чтобы начать путешествие по Всемирной паутине, необходимо подключиться к Интернету и запустить какой-нибудь браузер. После загрузки начальной (домашней) страницы можно поступать различными способами: • воспользоваться ссылками загруженной Web-страницы браузера; • в строку Адрес ввести адрес (URL) интересующей Web-страницы; • работать с «закладками» Web-страниц.
3. Информация и информационные процессы в природе, обществе, технике
К
![]() концу XX в. стала складываться, сначала
в рамках кибернетики, а затем информатики,
информационная картина мира. Информационная
картина мира рассматривает окру-жающий
мир под особым, информационным, углом
зрения, при этом она не противопоставляется
вещественно-энергетической картине
мира, но дополняет ее. Строение и
функционирование сложных систем
различной природы (биологических,
социальных, технических) оказалось
невозможным объяснить, не рассматривая
общих закономерностей информационных
процессов.
Получение
и преобразование информации является
условием жизнедеятельности любого
организма. Даже про-стейшие одноклеточные
организмы постоянно воспринимают и
используют информацию, например, о
температуре и химическом составе среды
для выбора наиболее благоприятных
условий существования. Биологи образно
говорят, что «живое питается информацией»,
создавая, накапливая и активно ис-пользуя
ее.
Любой
живой организм, в том числе человек,
является носителем генетической
информации, которая передается по
наследству. Генетическая информация
хранится во всех клетках организма в
молекулах ДНК, которые состоят из
отдельных участков (генов). Каждый ген
«отвечает» за определенные особенности
строения и функционирования организма
и определяет как его возможности, так
и предрасположенность к различным
наследственным болезням.
Чем
сложнее организм, тем большее количество
генов содержится в молекуле ДНК. Работы
по расшифровке генома человека, который
содержит более 20 тысяч различных генов,
проводились с использованием компьютерных
технологий и были в основном закончены
в 2000 г.
Человек
воспринимает окружающий мир (получает
информацию) с помощью органов чувств
(зрения, слуха, обоняния, осязания,
вкуса). Чтобы правильно ориентироваться
в мире, он запоминает полученные сведения
(хранит информацию). В процессе достижения
каких-либо целей человек принимает
решения (обрабатывает информацию), а в
процессе общения с другими людьми —
передает и принимает информацию. Человек
живет в мире информации.
Процессы,
связанные с получением, хранением,
обработкой и передачей информации,
называются информационными
процессами.
Человеческое
мышление можно рассматривать как процесс
обработки информации. Человек является
носителем очень большого объема
информации в виде зрительных образов,
знания различных фактов и теорий и т.
д. Весь процесс познания является
процессом получения и накопления
информации. Для обмена информацией
между людьми служат языки. Хранение
информации осуществляется с помощью
книг, а в последнее время все больше
посредством электронных
носителей.
Информационные
процессы характерны не только для живой
природы, человека и общества, но и для
техники. Чело-веком разработаны
технические устройства, в частности
ком-пьютеры, которые специально
предназначены для автоматической
обработки информации. Создание глобальной
компьютерной сети Интернет позволило
обеспечить для каждого человека
потенциальную возможность быстрого
доступа ко всему объему информации,
накопленному чело-вечеством за всю его
историю.
Информационный
подход к исследованию мира реализуется
в рамках информатики, комплексной науки
об информации и информационных процессах.
концу XX в. стала складываться, сначала
в рамках кибернетики, а затем информатики,
информационная картина мира. Информационная
картина мира рассматривает окру-жающий
мир под особым, информационным, углом
зрения, при этом она не противопоставляется
вещественно-энергетической картине
мира, но дополняет ее. Строение и
функционирование сложных систем
различной природы (биологических,
социальных, технических) оказалось
невозможным объяснить, не рассматривая
общих закономерностей информационных
процессов.
Получение
и преобразование информации является
условием жизнедеятельности любого
организма. Даже про-стейшие одноклеточные
организмы постоянно воспринимают и
используют информацию, например, о
температуре и химическом составе среды
для выбора наиболее благоприятных
условий существования. Биологи образно
говорят, что «живое питается информацией»,
создавая, накапливая и активно ис-пользуя
ее.
Любой
живой организм, в том числе человек,
является носителем генетической
информации, которая передается по
наследству. Генетическая информация
хранится во всех клетках организма в
молекулах ДНК, которые состоят из
отдельных участков (генов). Каждый ген
«отвечает» за определенные особенности
строения и функционирования организма
и определяет как его возможности, так
и предрасположенность к различным
наследственным болезням.
Чем
сложнее организм, тем большее количество
генов содержится в молекуле ДНК. Работы
по расшифровке генома человека, который
содержит более 20 тысяч различных генов,
проводились с использованием компьютерных
технологий и были в основном закончены
в 2000 г.
Человек
воспринимает окружающий мир (получает
информацию) с помощью органов чувств
(зрения, слуха, обоняния, осязания,
вкуса). Чтобы правильно ориентироваться
в мире, он запоминает полученные сведения
(хранит информацию). В процессе достижения
каких-либо целей человек принимает
решения (обрабатывает информацию), а в
процессе общения с другими людьми —
передает и принимает информацию. Человек
живет в мире информации.
Процессы,
связанные с получением, хранением,
обработкой и передачей информации,
называются информационными
процессами.
Человеческое
мышление можно рассматривать как процесс
обработки информации. Человек является
носителем очень большого объема
информации в виде зрительных образов,
знания различных фактов и теорий и т.
д. Весь процесс познания является
процессом получения и накопления
информации. Для обмена информацией
между людьми служат языки. Хранение
информации осуществляется с помощью
книг, а в последнее время все больше
посредством электронных
носителей.
Информационные
процессы характерны не только для живой
природы, человека и общества, но и для
техники. Чело-веком разработаны
технические устройства, в частности
ком-пьютеры, которые специально
предназначены для автоматической
обработки информации. Создание глобальной
компьютерной сети Интернет позволило
обеспечить для каждого человека
потенциальную возможность быстрого
доступа ко всему объему информации,
накопленному чело-вечеством за всю его
историю.
Информационный
подход к исследованию мира реализуется
в рамках информатики, комплексной науки
об информации и информационных процессах.
4. Сети и протоколы
На первых порах, когда разные сети базировались на разных вычислительных платформах, т.е. использовали несовместимые технические и программные средства, когда еще не были приняты стандарты на передачу данных, межсетевое общение было затруднено. Серьёзный сдвиг в преодолении этих барьеров произошел в 1974 , когда был разработан межсетевой протокол обмена информацией TCP/IP (Transmission Control Protocol/Internet Protocol). Однако прошло ещё почти 10 лет, пока этот протокол не был принят в обязательном порядке на всех узловых компьютерах сети Arpanet. К тому моменту к Arpanet присоединилось несколько сотен других сетей, и набор услуг вычислительного характера начал постепенно вытесняться услугами информационного плана. Протокол TCP/IP не является единственным стандартом на передачу данных в сетях. Поэтому между двумя сетями, использующими для внутреннего общения разные протоколы, организуются серверы-посредники, называемые шлюзами. Ситуация напоминает смену колес у вагонов на границе двух стран, железнодорожные пути в которых имеют разную ширину колеи.
Любой протокол обмена информацией между двумя абонентами представляет собой набор соглашений, в которых оговариваются различные технические характеристики и программные средства, участвующие в приёме/ передаче данных. В состав этих характеристик входят скорость передачи данных, средства контроля и устранения ошибок, форматы заголовков и способы адресации абонентов, методы сжатия и распаковки информации и многое другое. Часть таких соглашений обеспечивается аппаратными возможностями модемов, другие - обслуживающими программами. Два ПК, оборудованные модемами и снабжённые соответствующим программным обеспечением, могут связаться друг с другом, подобно абонентам, разговаривающим по телефону. Организации такой связи может предшествовать обычный телефонный разговор между владельцами ПК, оговаривающими время связи, скорость передачи информации и прочие параметры протокола. После установления связи между компьютерами по телефонному каналу можно передавать файлы точно так же, как и по «прямому проводу». К услугам подобной связи прибегают абоненты электронной доски объявлений BBS (Bulletin Board System). К существенным недостаткам такого общения между компьютерами относятся непредвиденная занятость телефонной линии, низкая пропускная способность каналов связи, высокая плата за междугородние контакты, необходимость ручного управления сеансом связи со стороны владельца принимающего ПК (клиента), сложность предварительной оценки полезности информации, извлекаемой из сервера BBS.
В начале 70-х годов Министерство обороны США приступило к разработке системы связи, которая должна была соединить между собой компьютеры всех центров противоракетной обороны страны. К надежности системы предъявлялись высокие требования: выход из строя любых ее составляющих (то есть компьютеров и линий связи) не должен был сказаться на качестве и скорости связи между остальными участниками информационного обмена. Так появилась сеть ARPAnet (Advanced Research Projects Agency - Бюро перспективных исследований Министерства обороны США; слово "net" по-английски означает "сеть"). Передача данных в сети была организована на основе протокола Internet - IP. Протокол IP - это правила и описание работы сети. Этот свод включает правила налаживания и поддержания связи в сети, правила обращения с IP-пакетами и их обработки, описания сетевых пакетов семейства IP (их структура и т.п.). Сеть задумывалась и проектировалась так, чтобы от пользователей не требовалось никакой информации о конкретной структуре сети. Для того чтобы послать сообщение по сети, компьютер должен поместить данные в некий "конверт", называемый, например, IP ,указать на этом "конверте" конкретный адрес в сети и передать получившиеся в результате этих процедур пакеты в сеть.
На протяжении почти десятилетия развитие сетевых технологий шло малозаметно для широкой публики: услугами сетей в основном пользовались программисты и военные. Но затем, опираясь на их опыт, многие организации стали создавать системы компьютерной связи между своими подразделениями, предприятиями, разнесенными на большие расстояния. К примеру, в конце 80-х годов Национальный научный фонд США (NFS) организовал 5 вычислительных центров, базирующихся на супер-ЭВМ, и сотням научных лабораторий и университетов, которым потребовался доступ к этим компьютерам и которые уже имели свои локальные, сети, пришлось объединится в единую сеть, используя опыт и технологию сети ARPAnet.
Информационное обслуживание
Развитие сферы сетевых услуг привело к массовому появлению серверов, ориентированных на предоставлении информации по определённой тематике. Появились, например, информационные центры в крупных зарубежных библиотеках, которые перевели большую часть своих фондов в электронный формат и продолжают оперативно вносить в эти архивы новые поступления. Это особенно ценно для наших читателей, т.к. многие отечественные библиотеки влачат жалкое существование. Но библиотечное дело - только капля в информационном океане. Перечень услуг, предоставляемых серверами Internet, достигает нескольких тысяч наименований. С международными источниками вы можете познакомиться по книге Х.Хана «Желтые страницы Internet»[1]. В книге А.Сигалова с таким же названием, изданной тем же издательством, содержится около 2000 адресов с источниками информации в нашей стране.
Глобальная сеть Internet
Несколько десятков тысяч компьютерных сетей, связанных между собой и объединяющих несколько миллионов пользователей, образуют всемирную паутину World Wide Web (сокращённо WWW). Организационному становлению Web содействовало появление универсальных сетевых навигаторов - браузеров (от англ. browse - пролистывать), таких как Netscape Navigator или Microsoft Internet Explorer. Браузер — это программа, которая запускается на вашем компьютере и обеспечивает работу с сетью Internet. Браузеры обеспечивают доступ к любому пункту сети по 2-разрядному адресу IP, который для удобства разделяют на байтовые компоненты - 192.34.101.23. Так как человеку числовыми адресами пользоваться неудобно, то в навигаторах адрес источника информации задаётся символьным кодом URL (Uniform Resource Locator), по которому сама сеть Internet осуществляет поиск адреса IP. Существует довольно много разных форматов URL: http://www.sportsnetwork.com ftp://ftp.unt.edu/library gopher://ulkyvm.loisville.edu
Начало URL соответствует используемому протоколу передачи данных. В частности, сокращение http происходит от HyperText Transmission Protocol - протокол передачи гипертекстовых документов.
Для подробного знакомства с услугами Internet, спецификой подключения к сети и технологией поиска нужной информации можно рекомендовать книгу С.Карпенко и И.Шишигина «Internet в вопросах и ответах»[2].
Гипертекст
Пользователи Internet получают информацию в виде гипертекста, являющегося основным способом представления данных. Термин Гипертекст, применяемый в последнее время в сочетании с прилагательным мультимедийный, означает документ, содержащий текстовые, звуковые и изобразительные фрагменты. Особенностью такого документа является наличие выделенных ключевых слов, всякого рода кнопочек и иконок, щелчки по которым воспроизводят соответствующие фрагменты, которые могут и не входить в состав данного документа, а находиться в памяти другого компьютера. Выделенные поля, активизация которых вызывает отображение следующих кадров, представлены в гипертекстовом документе ссылками на соответствующий фрагмент в пределах файловой системы данного компьютера или адресами URL для вызова недостающих компонентов из сети. Идеи гипертекста в том или ином виде присутствуют в различных справочных системах, в частности в системе помощи Windows всех версий (Help-система). Для описания гипертекстовых документов в Internet используется специальный язык HTML - HyperText Markup Language. Таким образом, можно сказать, что гипертекст - это многостраничная информация различного вида, связанная в различных страницах многочисленными ссылками.
Несмотря на то, что современные навигаторы «понимают» наиболее распространённые протоколы, в сетях постоянно возникают новые изобразительные средства. Навигаторы начинают разбухать, но угнаться за валом этих нововведений они не могут. Поэтому в 1994 возникла идея создания алгоритмического языка интерпретирующего типа, на котором можно было бы писать «проигрыватель» документа любого формата. Так в мае 1995 в компании Sun Microsystems появился язык Java, интерпретаторы с которого были реализованы на большинстве вычислительных платформ сети Internet. На этом языке пишутся приложения для Internet - апплеты, которые могут исполняться на любом компьютере, снабжённом Java-интерпретатором.
В настоящее время Internet не является отдельной сетью – на самом деле это сообщество сетей (именно поэтому Internet называют "сетью сетей"), в которое сейчас входит более 2 миллионов компьютеров во всем мире. И если вы подключены к сети, являющейся частью Internet, то вы имеете доступ к ресурсам любого из них.
Сервис в Internet
Internet - не говоря уже о том, что его появление ознаменовало новую эпоху в развитии коммуникации - позволяет человеку расширить свои познания в любой, даже самой немыслимой, сфере деятельности или исследований. А так как развитию Internet, с одной стороны, способствовали коммерческие организации, фирмы, использующие Сеть для обмена деловой информации и публикации рекламы, а с другой - студенты, помещающие на всеобщее обозрение множество материалов развлекательного характера, то здесь много полезного для себя найдут все – от бизнесменов до любителей со вкусом отдохнуть.
Спектр услуг в Internet к настоящему времени стал просто необозрим, поэтому начнем с самых известных и доступных.
Электронная почта - письмо без конверта
Один из видов информационных услуг, которые предоставляют компьютерные сети, — электронная почта (E-mail). В этом случае оба абонента — отправитель и получатель — имеют дело с посредниками (провайдерами), выполняющими функции местных отделений почтовой связи. Сервер посредника включен постоянно и на его винчестере официально зарегистрированным абонентам выделены «почтовые ящики» для временного хранения входящей и исходящей переписки.
Серверы. Для обеспечения функционирования локальной сети часто выделяется специальный компьютер — сервер, или несколько таких компьютеров. На дисках серверов располагаются совместно используемые программы, базы данных и т.д. Остальные компьютеры локальной сети часто называются рабочими, станциями. На тех рабочих станциях, где требуется обрабатывать только данные на сервере (например, вводить сведения в совместно используемую базу данных о заказах и продажах), часто для экономии (или по соображениям безопасности) не устанавливают жестких дисков. В сетях, состоящих более чем из 20-25 компьютеров, наличие сервера обязательно — иначе, как правило, производительность сети будет неудовлетворительной. Сервер необходим и при совместной интенсивной работе с какой-либо базой данных.
Иногда серверам назначается определенная специализация (хранение данных, программ, обеспечение модемной и факсимильной связи, вывод на печать и т.д.). Серверы, как правило, не используются в качестве рабочих мест пользователей. Серверы, обеспечивающие работу с ценными данными, часто размещаются в изолированном помещении, доступ в которое имеют только специально уполномоченные люди (как в банковское хранилище).
Замечание. Многие серверы стоят значительно дороже (в 10-20 и более раз) обычных компьютеров. Не удивительно — ведь они не только являются весьма мощными компьютерами с большим количеством оперативной и дисковой памяти, но в них вдобавок обеспечиваются исключительная надежность, высокая производительность ввода-вывода, дублирование устройств и хранимых данных, средства контроля над состоянием сервера, средства обеспечения бесперебойной работы при отказе некоторых устройств и т.д.
Программное обеспечение. Операционные системы Windows for Workgroups, Windows 95, Windows NT Workstation имеют встроенные возможности по организации локальных сетей без выделенного сервера (часто такие сети называются одноранговыми, поскольку в них все компьютеры равноправны). Так что при использовании этих ОС никакое дополнительное программное обеспечение не требуется. А в локальных сетях с выделенным сервером на сервере используются специальные операционные системы — Novell NetWare, Windows NT Server и др., — обеспечивающие надежную и эффективную обработку многих запросов от рабочих мест пользователей. На рабочих станциях такой локальной сети может использоваться любая операционная система, например DOS, Windows и т.д., и должен быть запущен программный драйвер, обеспечивающий доступ к локальной сети.
Для эффективной работы пользователей в локальной сети применяется вспомогательное программное обеспечение, которое иногда поставляется вместе с сетевой ОС, а иногда его надо покупать отдельно:
Местный сервер, как правило, располагает достаточно качественными каналами связи с одним из узлов сети, входящей в состав Internet. Посредник взимает со своих абонентов небольшую ежемесячную плату и выписывает дополнительный счёт, пропорциональный объёму передаваемой информации (в пределах страны и за её границами действуют разные тарифы).
Одновременно с регистрацией в местном «почтовом отделении» абоненту сообщается уникальный (с точки зрения местного сервера) электронный адрес и выдаётся специально настроенное программное обеспечение, которое позволяет автоматически установить связь с посредником, за несколько минут получить поступившую в ваш адрес корреспонденцию и отправить заранее подготовленные вами сообщения. На сеанс связи с провайдером можно выйти в любое удобное для вас время. Но длительно не востребованные поступления сервер возвратит отправителю.
Взаимодействие с программой обслуживания почты очень напоминает работу в текстовом редакторе. Заголовок электронного письма включает три обязательные раздела. Во-первых, это адрес отправителя, который располагается вслед за символами «From:». Такая строка автоматически включается в состав письма почтовой программой. Во-вторых, за ключевым словом «То:» необходимо набрать электронный адрес получателя. В некоторых сетях используются свои форматы для представления адреса. Наиболее распространённый формат электронного адреса в Internet предполагает задание пяти компонент:
Код_Получателя_Код_ПК.Код_Организации. Код_Города.Код_Страны
Однако и этот формат допускает отклонения. Например, вместо обычного двухсимвольного кода страны можно встретить код принадлежности к группе учебных заведений (.edu). Также вместо кода страны можно встретить коды принадлежности к коммерческим организациям (.сот)', американским правительственным учреждениям (.gov); американским военным организациям (.mil)', к прочим организациям.
Третья компонента в заголовке, располагаемая вслед за ключевым словом Subject, раскрывает тематику письма. Иногда её используют как дополнение к электронному адресу получателя. Обнаружив, например, в письме строку «Subject: to Sergey», получатель понимает, что в его почтовый ящик положили письмо для приятеля по имени Сергей, который не имеет собственного электронного адреса.
Письмо, переданное провайдеру, немедленно обрабатывается, и специальная программа-маршрутизатор определяет оптимальный путь передачи послания следующему компьютеру сети. От пользователя скрыты такие внутренние детали, как разбивка передаваемой информации на порции — пакеты, присоединение к пакетам служебной информации, сжатие данных, контроль за передаваемой порцией и повторная её посылка в случае обнаружения неустранимой ошибки и т.п.
Для передачи электронных писем в Internet используются три протокола. Старейший из них - SMTP - Simple Mail Transfer Protocol (Протокол передачи простой почты) был разработан еще в 1982. Спустя пару лет появился Протокол Почтового Отделения POP - Post Office Protocol (Протокол почтового отделения). С появлением в Internet почтовых сообщений, содержащих звуки и изображения, возник протокол MIME - Multipurpose Internet Mail Extension.
В некоторых сетях используется программное обеспечение с поддержкой национальной версии языка. Тогда можно набрать текст письма, используя, например, русский алфавит. Но в большинстве случаев приходится ограничиваться первой половиной набора ASCII, и тогда письма, адресованные за рубеж русским абонентам, могут иметь вид: «Privet, Sereja! Ja poluchil tuoe poslanie ot 25.03.97... ».
Следует обратить внимание на оперативность и дешевизну электронной почты по сравнению с традиционными средствами общения — телеграммами, междугородними телефонными разговорами, обычными письмами. Электронная почта доходит до абонента, расположенного в любой точке земного шара за считанные минуты. Скорость передачи информации между серверами достигает 3600 символов в секунду, что эквивалентно примерно 2 страницам текста. В отличие от обычных почтовых отделений, E-mail не теряет свои письма.
Телеконференции
Другой вид информационных сетевых услуг под названием «телеконференции» напоминает подписку на электронную газету, в которой появляются сведения по определенной тематике — новости, заметки, ответы на вопросы, отклики на предшествующие публикации и т.п. Авторами этой весьма разнообразной и сверхоперативной информации являются сами пользователи сети, объединённые общими интересами. Многие провайдеры предоставляют своим абонентам перечень конференций, в которых можно участвовать за умеренную плату. При этом вы будете регулярно получать электронные письма с заголовками статей по соответствующей тематике. Заголовки сопровождаются идентификационными номерами, объёмом статьи и, иногда, краткой аннотацией в 1-2 строки. За дополнительную плату, пропорциональную размеру статьи, вы можете заказать нужную публикацию. Только делать это нужно оперативно, т.к. сервер хранит содержимое очередного выпуска порядка 10 дней.
Телеконференции по оформлению и способу работы очень похожи на электронную почту с тем лишь отличием, что ваше письмо может прочитать огромное количество людей, а в свою очередь сможете поинтересоваться тем, что пишут вам совершенно незнакомые люди. Конференции подразделяются по темам, название конференции состоит из нескольких слов, разделенных точками, каждое последующее из которых сужает тему. Вот стандартное обозначение некоторых групп телеконференций Usenet: comp - конференции, где обсуждается все, что связано с компьютерами и программированием; news - обмен новостями, вопросы развития системы телеконференций; rec - отдых, хобби, увлечения; sci - все, что связано с наукой; soc - вопросы общественной жизни; talk - группа для любителей поспорить или просто поговорить на любую тему.
Начиная работать с какой-либо группой, в первую очередь нужно прочитать правила работы в ней, которые регулярно помещаются в эти группы человеком, добровольно взявшим на себя обязанности координатора группы (модератора). На самом деле, группы новостей бывают двух типов - модерируемые и обычные. Сообщения, появляющиеся в модерируемых группах, прежде чем быть разосланными по сети, просматриваются модератором. Это, конечно, является своего рода цензурой, но в таком огромном сообществе, как Usenet, невозможно поддерживать порядок без подобных строгостей.
Сегодня всякий компьютер, полноценно подключенный к Интернет, имеет доступ к новостям Usenet, но новости Usenet распространяются и по другим сетям, применяясь столь же широко, как и электронная почта. Способы и удобство работы с новостями сильно зависят от того, каким образом Вы получаете их. В Интернет Ваша программа-клиент напрямую получает новости с сервера Usenet, и между просмотром списка сообщений, содержащихся в группе, и чтением этих сообщений нет задержки. Если Вы пользуетесь новостями через электронную почту, то Вы сначала получаете список статей, а уже потом принимаете по электронной почте статьи из списка, отдельно Вами заказанные.
File Transfer Protocol (FTP) – передача файлов
FTP сервис Интернет - сервис, который дает максимальную нагрузку на каналы связи. Расшифровывается эта аббревиатура как протокол передачи файлов, но при рассмотрении ftp как сервиса Интернет имеется в виду доступ к файлам на удаленных компьютерах и в файловых архивах. FTP - стандартная программа, работающая по протоколу TCP, как правило, поставляющаяся с операционной системой. Ее исходное предназначение - передача файлов между разными компьютерами, работающими в сетях TCP/IP: на одном из компьютеров работает программа-сервер, на втором пользователь запускает программу- клиента, которая соединяется с сервером и передает или получает файлы. Тут предполагается, что пользователь зарегистрирован на обоих компьютерах и соединяется с сервером под своим именем и со своим паролем на этом компьютере. Протокол FTP, разумеется, оптимизирован для передачи файлов.
Данная черта и послужила причиной того, что программы FTP стали частью отдельного сервиса Интернет. Дело в том, что сервер FTP можно настраивается таким образом, что соединиться с ним можно не только под своим именем, но и под условным именем anonymous. Тогда Вам становятся доступна не вся файловая система компьютера, но некоторый набор файлов на сервере, которые составляют содержимое FTP-сервера anonymous - публичного файлового архива. Итак, если кто-то хочет предоставить в публичное пользование файлы с информацией, программами и прочим, то ему достаточно организовать на своем компьютере, включенном в Интернет, FTP сервер.
Если Вы, например, хотите представить миру демо-версию Вашего программного продукта - использование FTP сервера является удачным решением такой задачи. Если, с другой стороны, Вы хотите найти, скажем, последнюю версию Вашей любимой свободно распространяющейся программы, то искать ее нужно именно на серверах FTP.
Несмотря на распространенность, у FTP есть и множество недостатков. Программы-клиенты FTP могут быть не всегда удобны и просты в использовании. Не всегда можно понять, а что это за файл перед Вами. Нет простого и универсального средства поиска на серверах FTP – хотя для этого и существует специальный сервис ARCHIE, но это независимая программа, неуниверсальная и не всегда применимая. Описания файлов на сервере выдаются в формате операционной системы сервера, а список файлов операционной системы UNIX может привести в недоумение пользователя DOS. Проблема тут в том, что со списком файлов выдается лишняя информация, а слишком много знать вредно.
Серверы FTP нецентрализованы, и это несет свои проблемы. FTP - сервис прямого доступа, требующий полноценного подключения к Интернет, но возможен и доступ через электронную почту – большая часть FTP серверов может прислать свои файлы по E-mail, а так же существуют серверы, которые могут прислать Вам по электронной почте файлы с любых FTP серверов. Однако это не всегда удобно, ибо такие серверы сильно загружены, и Ваш запрос может долго ждать своей очереди. Кроме того, большие файлы при отсылке делятся сервером на части ограниченного размера, пос 1000 ылаемые отдельными письмами - и если одна часть из сотни потеряется или повредится при передаче, то остальные 99 тоже окажутся ненужными.
Internet Real Chat
(реальное общение в Интернете)
Это можно перевести как "параллельные беседы" в Internet или "переключаемый треп". Представьте себе десятки тысяч людей, которые собрались в Internet поговорить. С друзьями и незнакомыми людьми. Обсудить определенные темы или просто потрепаться. И все это происходит в реальном времени. Для того чтобы поучаствовать в беседе, вам нужно просто подключиться к выбранному каналу. Каждый канал имеет название, которое более или менее отражает тему разговоров (например, на канале warez идет обмен ворованными программами), а иногда и нет.
Гипертекстовая система GOPHER
Одним из достаточно известных и распространенных сервисов Интернет является GOPHER (правда устаревшим). Хотя сейчас он уже практически не развивается, или, во всяком случае, развивается гораздо медленнее прочих сервисов похожего назначения, но тем не менее через GOPHER доступно довольно-таки большое количество информации - в первую очередь, по историческим причинам - был период, когда GOPHER был лучшим средством публичного доступа к информации. Современные средства работы с информацией в Интернет (например, WWW просмотрщики) обеспечивают в том числе доступ к серверам GOPHER, поэтому специальных программам-клиентов GOPHER в настоящий момент не используется. Что касается использования сервера GOPHER для предоставления новой информации в публичный доступ - вряд ли целесообразно использовать морально устаревший сервис GOPHER.
GOPHER - это распределенная система экспорта структурированной информации. При работе с GOPHER Вы находитесь в системе вложенных меню, из которых доступны файлы различных типов - как правило, простые тексты, но это может быть и графика, и звук и любые другие виды файлов. Таким образом, в публичный доступ экспортируются файлы с информацией, но не в виде файловой системы, как в FTP, а в виде аннотированной древовидной структуры. GOPHER - сервис прямого доступа и требует, чтобы и сервер, и клиент были полноценно подключены к Интернет.
Основное преимущество Gopher состоит в том, что вам не нужно запоминать адрес или название ресурса и последовательность команд, необходимую для доступа к нему: двигаясь по меню программы, вы на самом деле перемещаетесь по разным компьютерам, подключенным к Сети. Однако сегодня Gopher, по всей видимости, доживает последние дни, потому что появился новый сервис, гораздо более удобный.
Другие сетевые информационные ресурсы
Несмотря на то, что Интернет, несомненно , самое мощное средство к сетевой информации, существуют и другие источники, многие из которых предвосхитили взрывообразное увеличение использования Интернет. В их число входят компьютерные доски объявлений и коммерческие информационные службы.
Всемирная паутина (World Wide Web или WWW)
На сегодняшний день это наиболее продвинутый и интересный ресурс - гипертекстовая система навигации в Internet. От обычного гипертекста WWW отличается главным образом тем, что позволяет устанавливать ссылки не только на соседний файл, но и на файл, находящийся на компьютере в другом полушарии Земли. От вас же не требуется никаких усилий - компьютер установит связь самостоятельно.
В WWW, как и в Gopher, к ресурсам можно обращаться, непосредственно указывая их адрес. В этом случае приходится сталкиваться с сокращением URL - Uniform Resourse Locator, универсальный способ обозначения ресурса Internet. Обозначение URL состоит из двух частей: первая указывает тип связи, который следует установить с нужным вам источником, вторая - имя требуемого сервера. Типы связи соответствуют стандартным услугам Internet. Вот основные из них: http - HiperText Transfer Protocol,основа WWW, - тип связи, необходимый при обращении к любому WWW-серверу; ftp - используется при обращении к FTP-серверам; gopher - предназначен для взаимодействия с Gopher; telnet - предназначен для получения терминального доступа к удаленной машине; news - открывает доступ к телеконференциям.
Информация на WWW может включать в себя текст, рисунки, таблицы, звук, мультипликацию и многое другое. Благодаря своим широким возможностям, красоте и простоте в использовании "всемирная паутина" завоевала огромную популярность во всем мире. Информационная навигация в сети InterNet: Введение в инструментальные системы нового поколения - "Навигаторы" системы WWW.
Если Вы когда-либо имели возможность изумляться возможностям сети InterNet, то Вы уже знаете о феноменальном объеме информации - все от баз данных, текстовых файлов, документов, имидж- аудио- видео- файлов до готовых программ. При таком гигантском объеме данных в сети необходимо иметь развитые инструментальные системы, которые делают информационный поиск более эффективным. До 1991 года в сети InterNet были разработаны простые инструментальные системы и навигаторы первого и второго поколения. Но затем начался новый этап координированных разработок. Именно в том году, в CERN, в Женеве, были разработаны системы, ныне называемые World Wide Web ( WWW/3W или просто "Web" - по-нашему "Паутинка").
Эта же система является попыткой интегрировать разнообразные инструментальные системы и данные с помощью общего формата данных на базе концепции гипертекста. Результат этих разработок был чрезвычайно успешным. Фактически, они сформировали к настоящему времени лицо сети InterNet . Система Web базируется на методе связывания слов и фраз в документе для ссылки к соответствующей информации в этом же или другом документе. Поскольку другие документы могут быть на разных серверах, эти ссылки образуют своеобразную "паутину" взаимных связей, которая пронизывает сеть IntеrNet.
Но что же можно делать с этой технологией на Вашей локальной сети? Web-технология может использоваться и в том случае, если Ваше сеть не включена в InterNet. Все компоненты этой технологии доступны для многих платформ как FreeWare.
Ряд ведуших программных фирм срочно реализуют первые коммерческие инструментальные системы для этой новой сетевой Web-технологии. Они ориентированы на более оптимальную интеграцию Web-технологии в среду рабочих станций и будут более удобными с точки зрения системного сопровождения и администрирования. Для понимания сути Web-технологии и используемых программных средств, следует напомнить об основных навигационных и инструментальных средствах, доступных пользователям сети InterNet. Самыми простые средства - FTP и Telnet. Ftp - это программа, которая использует TCP/IP File Transport Protocol для передачи файлов между компьютерами. Telnet - это программа для доступа к удаленному компьютеру в режиме эмуляции локального терминала.
Хотя эти программы работают безотказно, они являются "слепыми", поскольку обрабатывают только те данные, размещение которых уже известны Вам и предназначены для выполнения только основных операций. Фактически они были инструментальными средствами первого поколения в сети InterNet. Следующее поколение инструментальных средств - "навигационные" - ориентировалось на проблему поиска требуемых информационных ресурсов.
Гипертекстовая система Hyper-G
WWW не была единственной попыткой создать глобальную гипермедийную распределенную информационную систему. Другой такой системой является Hyper- G. Этот сервис Интернет менее известен, но весьма интересен. Hyper-G значительно моложе WWW (хотя темпы роста и не указывают на то, что Hyper-G сможет когда-либо сравниться по популярности с WWW) и это академическая разработка - плод стараний технологического университета в Граце (Graz), Австрия. Система эта вряд ли окажется практически полезной для Вас, но заслуживает внимания как очень интересная технология, и ее рассмотрение позволяет многое добавить в картину сервисов Интернет и их развития. С общих позиций Hyper-G аналогична WWW, преследуя те же идеи и повторяя многие принципы. Есть клиенты и есть серверы, которые предоставляют информацию в виде коллекций документов. По принципам организации информации в пределах одного сервера Hyper-G является чем-то средним между WWW и GOPHER. Документы доступны из иерархического меню, но сами документы являются гипермедийными. Клиент Hyper-G общается не со множеством серверов, как в случае WWW, но исключительно со "своим" сервером, регистрируясь на нем при подключении. Получение документов с других серверов Hyper-G происходит через "свой" сервер, что позволяет создать более интегрированную систему серверов, чем в случае с WWW. Регистрация же клиента позволяет определить уникальным образом не только ресурсы и сервисы Интернет, но и клиентов, что значительно облегчает обеспечение авторизованного доступа и удаленного управления документами. К чертам, препятствующим распространению Hyper-G, следует отнести недостаточно хорошую реализацию программ-клиентов, не полностью свободный доступ к серверной части программного обеспечения, централизованность проекта и отсутствие альтернативных реализаций программного обеспечения, слишком твердую структуру организации документов на сервере, сложность системы. Серверы Hyper-G весьма немногочисленны, следовательно, информации в Hyper-G хранится немного. Отсутствует доступ посредством электронной почты, хотя серверы Hyper-G могут также выполнять роль серверов gopher и WWW.
Поисковая система WAIS
WAIS - еще один сервис Интернет, сегодня почти не использующийся, или, по крайней мере, практически не развивающийся. WAIS расшифровывается как информационная система широкого профиля, но на самом деле это комплекс программ, предназначенных для индексирования больших объемов неструктурированной, как правило просто текстовой, информации, поиска по таким документам и их извлечения. Существуют программы для индексирования, для локального поиска по полученным индексам, а также серверная и клиентская программа, общающиеся между собой по специальному протоколу Z39.50. Задача поиска по большим объемам неструктурированной информации весьма нетривиальна и сегодня еще не существует общепринятого ее решения. WAIS во многих случаях является приемлемым вариантом поисковой системы, и коль скоро она имеет свободно распространяемую программную реализацию, то получила достаточную известность как один из сервисов Интернет. На самом деле, она почти не используется сегодня самостоятельно, но во многих случаях применяется как вспомогательное средство, например, для индексирования документов, хранящихся на WWW-сервере. В некоторых случаях она также используется как средство работы со словарями, или для поиска по архивам сетевых новостей Usenet. Если перед Вами стоит задача по индексированию больших объемов неструктурированной информации, то, возможно, WAIS окажется адекватным ее решением. Однако, нужно иметь в виду, что свободно распространяемая реализация системы далека от совершенства, что система достаточна сложна для понимания и изучения, и, что хуже всего, практически не развивается. Поддержкой и развитием свободной версии занимались последовательно несколько организаций, но ни одна из них не довела продукт до приемлемого для реальной работы состояния.
"Навигация" в сети Internet
При обширном информационном богатстве, которое возникало в каждом "углу" InterNet, подобно грибам на лесной поляне, главным требованием к новым инструментальным средствам была эффективность при поиске требуемых сетевых ресурсов.
Ввиду большого многообразия имеющихся ресурсов в сети InterNet, информационный поиск - сложная проблема, особенно с точностью до абсолютного сетевого номера (для примера, имеются сотни сложных баз данных, и десятки тысяч архивных серверов со свободным доступом). Фактически каждый час в сети появляются все новые и новые источники, что и делает обычный поиск практически безнадежным занятием. В настоящее время имеются следующие "навигационные" средства:
- система Archie;
- СУБД для поиска файлов в открытых для доступа архивах;
- Wide Area Information Server, который может использоваться для поиска в большом числе баз данных и документальных архивах.
Имеется также системы типа Gopher с интерфейсом в виде текстовых экранных форм-меню, которые ссылаются на распределенные по сети информационные источники, образуя тем самым "паутину" связей - так называемые Gopher-пространства. Система Veronica предназначена для поиска объектов в этом Gopher-пространстве. Эти навигационные "прилады" (средства) до сих пор широко используются. Но, обеспечивая эффективную навигацию по InterNet, они все имеют дело с простым форматом командного файла и манипулируют с ограниченным типом данных.
Стало ясно, что необходимы более совершенные системы с развитыми сервисными функциями и с возможностями обработки более разнообразных форматов данных. И одним из источников разнообразных данных стала сама Web-сеть, послужившая основой для следующего поколения инструментальных средств InterNet - Web-"навигаторов.
Модификация Web
Гипертекстовые ссылки системы Web действуют как указатели на другие части единого документа, или на совершенно разные документы, или на другие доступные по сети сервисы. Хотя во многом это кажется несколько абстрактным в теории, на практике - очень эффективно и удобно. Если Вы когда-либо использовали подсистему Help для Windows, Вы уже имели практические навыки работы с гипертекстом. Любое слово, фраза, или пиктограмма в документе "Help" может быть описана как самостоятельный объект. Когда Вы выбираете этот объект, происходит переход на соответствующую часть документа. Навигаторы Web расширяют эту идею, обеспечивая связи между документами, размещенными в разных узлах сети, и доступ к разнообразным сервисам типа FTP и Gopher-пространствам. Для примера, в описании сетей может быть ссылка на Ethernet. Если слово "Ethernet" поддержано гипертекстовой ссылкой, при его выборе, Вы получите переход на описание этой сетевой технологии. В этом описании, в свою очередь, может быть ссылка на документ о поставщиках оборудования Ethernet и выбор какого-то из них обеспечит переход на документ, описывающий все поставляемое им оборудование. Более того, в этом описании может быть список всех драйверов для поставляемых адаптеров сети Ethernet.
О! и Вы обнаружили, что появилась самая последняя версия драйвера именно для той карты, которую Вы уже давно используете. И эту версию можно заполучить простым нажатием клавиши Вашей "мышки" для активации соответствующей гипертекстовой ссылки.
Ссылки и документы
Документы в системе Web могут включать, помимо текстов, указания об используемых шрифтах и форматах, ссылки на графические данные и фотоснимки, ссылки на другие данные, документы и сервисы. Все эти документы формируются по правилам Hypertext Markup Language (HTML).
HTML базируется на промышленном стандарте - Standard General Markup Language (SGML) - для создания машинно-независимых документов, с учетом всего многообразия используемых компьютерных платформ. При этом HTML еще более расширяет определение гипертекстовой ссылки. HTML документ состоит из текста, который должен быть выдан на дисплей, и описателей - тэгов (tags), которые определяют, как этот техт должен быть представлен, и как другие типы данных - для примера, видео- и аудио- данные - должны извлекаться и форматироваться, и куда ведет каждая гипертекстовая ссылка. HTML-описатели являются полями в документе, которые размещаются между символами "" и содержат директивы и соответствующие параметрические данные - атрибуты директивы. Например, в поле Hello HTML начальный тэг указывает на начало заголовка, а директива "H" определяет, что следующий за этим тэгом текст следует разместить в этом заголовке. Следующие за директивой атрибуты доопределяют, что эта директива должна фактически сделать. В нашем примере аргумент "1" указывает, что заголовок должен размещаться на первом уровне. Завершающий тэг указывает об окончании этого поля.
Имеются специальные тэги для описания гипертекстовых ссылок (так называемых anchors), заголовков, изображений и других объектов. Создание HTML-документов - занятие не для "слабаков". В настоящее время еще нет истинных HTML-редакторов, работающих режиме "что видите, то и получаете" ( What You See Is What You Get -WYSIWYG). Но уже имеется несколько вариантов для разработки HTML- документов (см. прил. N=1). Уже имеются HTML-ware (но еще не в режиме WYSIWYG) типа Hypercard Editor для PC Macintosh, или WinWord-macros для Microsoft Word. Уже появились почти WYSIWYG-редакторы - один для платформы NeXt Computer,Inc. И один для Windows - HTML Assistant (пока как shareware-программа - альфаверсия).
Можно использовать и трансляторы, которые конвертируют стандартные документы формата Rich Text в формат HTML (эта версия готова для PC Machintosh). Пока все эти программы еще требуют "ручной" доводки выходных документов. Но с другой стороны, создание простых документов можно делать и "вручную".
Что такое URL
Базовое понятие в WWW-навигаторах - Унифицированные Указатели Ресурсов (Uniform Resource Locators - URL). URLs используются для идентификации размещения ресурсов, на которые ссылаются в документах. Например, URL для главного индекса (home page) набора документов в Национальном Центре по Прикладным Программам для Суперкомпьютеров (NCSA) задается следующим способом: http://www.ncsa.uiuc.edu/Genaral/NCSAHome.html Компонента "http:" определяет метод доступа - через сервер HyperText Transfer Protocol (HTTP). Этот протокол определяется его создателем Tim Barners-Lee как " ... простейший и достаточно быстрый для распределенных и взаимодействующих информационных гипермедиа систем. Это общий объектно- ориентированный протокол, который может использоваться для многих схожих проблем, таких как Name Servers и распределенных объектно-ориентированных систем".
Следующая часть URL - "//www.ncsa.uiuc.edu" - описывает, на каком узле размещены данные. Наконец, компонента "/Genaral/" определяет, где размещается файл с документом "NCSAHome.html". Для изучения навигации в системе WWW попробуйте начать с главных страниц на серверах в NCSA и CERN. Если Вы размещаетесь в локальной сети типа NetWare, Вы сможете навигировать по всем информационным ресурсам этой сети через Novell's home page. А информацию о новостях в сети InterNet можно найти на "странице" NCSA's Mosaic "What's New page" (см. прил. N=1) и Навигаторе Глобальной Сети (Global Network Navigator) - прекрасной программной разработке сотрудников издательства O'Reily Press.
"Навигация" в сети Web
Хотя было разработано несколько программ для навигации в сети - например, WWW и Lynx для текстового режима, но только система Mosaic завоевала признательность почти всех пользователей сети InterNet. Она была разработана в NCSA в 1993 году и объединяет на базе единого графического интерфейса как несколько традиционных для сети InterNet инструментальных подсистем, так и возможности новых навигаторов. Другая альтернативная система Cello в среде Windows была создана на Юридическом факультете Корнельского Университета. Mosaic и Cello обеспечивают эффективную программную среду для успешной навигации любого новичка по информационным "сокровищам" вей глобальной сети InterNet. Используя эти "оболочки", не надо тратить время на изучение всех сложных инструментальных средств первого и второго поколения. Из-за удобного и эффективного интерфейса и из-за реализации на многих промышленных платформах, системы Mosaic и Cello стали широко использоваться для информационного сервис в рамках больших компаний.
Заключение
Подводя итоги проделанной работе, подчеркиваю, что Интернет- технологии в использовании информационных ресурсов идут вперед семимильными шагами, и это значительно облегчает поиск и сбор информации по необходимой теме. В то же время есть некоторые недостатки, которые со временем, надеюсь, будут исправлены. К таким недостаткам относится некоторая засоренность сети бесполезной информацией, которая чаще всего мешает при поиске той или иной информации, отсутствие единой систематизирующей информацию и доступ к ней программы также является значительным препятствием. Исходя из вышесказанного, попытаемся заглянуть в будущее Интернет, которое уже близко, но, в то же время, зависит от вчерашнего дня сети.
Internet сегодня и завтра
1. Еще менее года назад поисковый сервер AltaVista (http://www.altavista.digital.com - очень мощная и быстрая поисковая система) компании DEC гордо объявил на фронтальной странице: "Мы отслеживаем изменения более чем на 70 000 серверов во всем мире." На сентябрь 1996 года эта цифра составляет 275 600 и, разумеется, постоянно увеличивается. По некоторым прогнозам, если количество хостов Internet будет расти так же быстро, то к концу первого десятилетия 21-го века существующего пространства адресов просто не хватит на всех желающих. Эту проблему (да и не только эту) призван решить новый стандарт Internet- протокола. Полный список только поисковых и навигационных систем сети будет включать в себя ссылки более чем на 120 независимых серверов.
2. Еще совсем недавно телефон был наиболее популярным и широко используемым средством связи. Сейчас любой человек, подключившись к Internet, может разговаривать со своим собеседником по этой сети. Все, что ему нужно для этого - звуковая карта, микрофон и колонки. Причем переговоры обходятся ему значительно дешевле, чем если бы он разговаривал обычному телефону. Пока это возможно только для абонентов сети, но сегодня очень активно ведется разработка аппаратных и программных средств для создания шлюза Internet - обычный телефон (интересные материалы на эту тему есть на сервере компании Vokaltech - производителя программы iphone, стандарта де-факто для живого общения в сети; адрес документа - http://www.vokaltec.com/gateway.htm).Пока что качество разговора сильно зависит от скорости подключения к Internet - минимальная скорость передачи данных 14400 b/c. Ведутся также разработки, позволяющие снизить необходимую скорость до 2400 b/c.
3. Системы видеоконференций. Они существуют и работают. Наиболее известный свободно распространяемый продукт этого рода - программа Cu- SeeME. Адрес сервера - http://137.142.42.95/CuSeeME.html. Минимальная скорость подключения 14400 b/c. Эта "игрушка" становится достаточно эффективным способом проведения собраний в рамках большого предприятия.
4. Практически каждая более или менее крупная фирма создает свою корпоративную сеть для собственных нужд. Буквально в течении последнего года стало крайне популярным еще одно порождение Internet. Это Intranet- корпоративная сеть, построенная на Internet-технологии. А компании- производители наступают друг другу на пятки, стараясь занять еще одну нишу для своего рынка. В частности упор делается на системы html- верстки и построения Web-узлов, ориентированные на совершенно неподготовленного пользователя.
5. В сфере аудиотехнологий еще одна достаточно интересная "игрушка" - Real Audio (http://www.realaudio.com). Данная система позволяет передавать по сети "живой звук" и может использоваться для широковещательных трансляций.
6. Интерес представляют попытки создания "электронных денег" (например, http://www.cybercash.com) и вообще - система достоверных и безопасных платежей (один из пионеров в этой области - http://www.firstvirtual.com). В настоящий момент, можно сказать, эта проблема решена. Уже сейчас через сеть с помощью кредитной карточки вы можете заказать билет на самолет, забронировать номер в гостинице или просто купить CD-ROM с понравившейся игрой.
7. Еще один хит нынешнего сезона - технологии интерактивного взаимодейсвтия. Два безусловных лидера в этом направлении - платформо- независимая среда Java (http://www.firstvirtual.com) от Sun Microsystems и продолжение технологии OLE - ActiveX(http://www.activex.com),детище Microsoft. Обе технологии, на первый взгляд, направлены на одно и то же, но на самом деле они прекрасно дополняют друг друга. И хотя сейчас, пожалуй, можно оценить только первые шаги в их разработке, как и в их применении и освоении, результаты уже впечатляют.
Все это имеется уже сейчас, а за рамками осталось еще много разного и интересного.
5. Информация в биологии. В биологии понятие информация связывается с целесообразным поведением живых организмов. Такое поведение строится на основе получения и использования информации об окружающей среде. Понятие информация в биологии применяется также в связи с исследованиями механизмов наследственности. Генетическая информация передается по наследству и хранится во всех клетках живых организмов. Гены представляют собой сложные молекулярные структуры, содержащие информацию о строении живых организмов. Последнее обстоятельство позволило проводить научные эксперименты по клонированию, т. е. созданию точных копий организмов из одной клетки. Информация в кибернетике. В кибернетике (науке об управлении) понятие информация используется для описания процессов управления в сложных системах (живых организмах или технических устройствах). Жизнедеятельность любого организма или нормальное функционирование технического устройства связано с процессами управления. Процессы управления включают в себя получение, хранение, преобразование и передачу информации. Информация и знания. Человек получает информацию из окружающего мира с помощью органов чувств, анализирует ее и выявляет существенные закономерности посредством мышления, хранит полученную информацию в памяти. Процесс систематического научного познания окружающего мира приводит к накоплению информации в форме знаний (фактов, научных теорий и т. д.). Только при условии, что информация полезна, дискуссия приобретает практическую ценность. Бесполезная информация создает информационный шум, который затрудняет восприятие полезной информации. Примерами передачи и получения бесполезной информации могут служить некоторые конференции и чаты в Интернете. Широко известен термин «средства массовой информации» (газеты, радио, телевидение), которые доводят информацию до каждого члена общества. Обязательно, чтобы такая информация была достоверной и актуальной. Недостоверная информация вводит членов общества в заблуждение и может стать причиной возникновения социальных потрясений. Неактуальная информация бесполезна, и поэтому никто, кроме историков, не читает прошлогодних газет. Чтобы человек мог правильно ориентироваться в окружающем мире, ему нужна полная и точная информация. Задача получения полной и точной информации стоит перед наукой. Человек получает полную и точную информацию о природе, обществе и технике в процессе обучения. Единицы измерения количества информации. За единицу количества информации принимается такое количество информации, которое содержит сообщение, уменьшающее неопределенность знаний т два раза. Такая единица названа бит. Следующей по величине единицей измерения количества информации является байт, причем 1 байт = 2^3 бит = 8 бит. Кратные байту единицы измерения количества информации вводятся следующим образом:
6. Процесс обработки текста
Обработка (преобразование) текста -- это процесс изменения формы представления текста или его содержания.
Обработка текста всегда осуществляется с какой-либо целью.
Процессы изменения формы представления текста часто сводятся к процессам его кодирования и декодирования и проходят одновременно с процессами сбора и передачи информации.
Процесс изменения содержания текста включает в себя такие процедуры, как численные расчеты, редактирование, упорядочивание, обобщение, систематизация и т.д.
Систему, в которой наблюдателю доступны лишь входные и выходные величины, а структура и внутренние процессы неизвестны, называют черным ящиком [3, c. 87].
Обработка текста по принципу “черного ящика” - процесс, в котором пользователю важна и необходима лишь входная и выходная информация, но правила, по которым происходит преобразование, его не интересуют и не принимаются во внимание.
Если правила преобразования текста строго формализованы и имеется алгоритм их реализации, то можно построить устройство для автоматизированной обработки текста.
Возможность автоматизированной обработки текста основывается на том, что преобразование текста по формальным правилам не подразумевает его осмысления.
В вычислительной технике устройством обработки текста является процессор.
Обработка текста - это процесс, происходящий во времени.
Если он подчиняется заданному темпу поступления входной информации и допустимому пределу задержки в выработке информации на выходе, то говорят об обработке в реальном масштабе времени.
Наиболее простой формой обработки текста является последовательная обработка, производимая одним процессором, в котором в любой момент времени происходит не более одного события.
При наличии в системе нескольких процессоров, работающих одновременно, говорят о параллельной обработке текстовой информации.
2. Элементы теории кодирования
Одни и те же сведения могут быть представлены, закодированы в нескольких разных формах и, наоборот, совершенно разные сведения могут быть представлены в похожей форме [5, c. 91].
При любых видах работы с информацией всегда идет речь о ее представлении в виде определенных символьных структур. Наиболее распространены одномерные представления информации, при которых сообщения имеют вид последовательностей символов. Так информация представляется в письменных текстах, при передаче по каналам связи, в памяти ЭВМ. Однако широко используются и многомерные представления информации, причем под многомерностью понимают расположение элементов информации на плоскости или в пространстве (в виде рисунков, схем, графов, объемных макетов и т.д.). Например, информацию могут нести не только значения букв и цифр, но и их цвет, размер, вид шрифта.
Часто термин «кодирование» употребляется в более узком смысле.
Кодирование в узком смысле слова подразумевает представление сообщения в форме, удобной для передачи по некоторому каналу связи.
Информационное сообщение всегда связано с источником информации, приемником информации и каналом передачи.
Чтобы передать информацию, её необходимо предварительно преобразовать.
Кодирование - это преобразование сообщения в форму, удобную для передачи по каналу связи.
Пример: передача сообщения в виде телеграммы. Все символы кодируются с помощью телеграфного кода.
Декодирование - операция восстановления принятого сообщения.
В систему связи необходимо ввести устройства для кодирования и декодирования информации.
При передаче по каналу связи возникают ошибки, связанные с разными причинами, но все они приводят к тому, что получатель принимает искаженную информацию. Для того чтобы организовать нормальную работу информационного канала связи необходимо решить следующие проблемы:
обнаружить ошибки, если они возникают;
исправлять найденные ошибки;
защищать информацию, передающуюся по каналам связи;
ускорять передачу информации по каналу связи [1, c. 37].
Из перечисленных проблем теория кодирования исследует первую и вторую. Третьей проблемой занимается криптография. Четвертая же является прикладной для криптографии и теории кодирования как параметр, с помощью которого определяется качество криптографии и кодирования.
2.1 Понятие о кодировании информации
Информация передается в виде сигналов. Когда мы разговариваем с другими людьми, то улавливаем звуковые сигналы. Если мы смотрим в окно, наш глаз принимает световые потоки, отраженные от объектов окружающей природы. Световой поток -- это тоже сигнал.
А как же информация хранится? Для того чтобы информацию сохранить, ее надо закодировать. Любая информация всегда хранится в виде кодов. Когда мы что-то пишем в тетради, мы на самом деле кодируем информацию с помощью специальных символов. Эти символы всем знакомы -- они называются буквами. И система такого кодирования тоже хорошо известна -- это обыкновенная азбука. Жители других стран те же самые слова запишут по-другому (другими буквами) -- у них своя азбука. Можно сказать, что у них другая система кодирования. В некоторых странах вместо букв используют иероглифы -- это еще более сложный способ кодирования информации.
Можно кодировать и звуки. С одной из таких систем кодирования вы тоже хорошо знакомы: мелодию можно записать с помощью нот. Это не единственная система кодирования музыки. В давние времена на Руси музыку записывали с помощью так называемых «крюков» -- это особая форма записи [4, c. 98].
Хранить можно не только текстовую и звуковую информацию. В виде кодов хранятся и изображения. Если посмотреть на рисунок с помощью увеличительного стекла, то видно, что он состоит из точек -- это так называемый растр. Координаты каждой точки можно запомнить в виде чисел. Цвет каждой точки тоже можно запомнить в виде числа. Эти числа могут храниться в памяти компьютера и передаваться на любые расстояния. По ним компьютерные программы способны изобразить рисунок на экране или напечатать его на принтере. Изображение можно сделать больше или меньше, темнее или светлее, его можно повернуть, наклонить, растянуть. Мы говорим о том, что на компьютере обрабатывается изображение, но на самом деле компьютерные программы изменяют числа, которыми отдельные точки изображения представлены в памяти компьютера.
2.2 Кодирование и декодирование
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком.
Рассмотрим некоторые примеры кодов [3, c. 29].
1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1,2,3):
|
|
|
|
|
|
|
|
|
А |
111 |
H |
132 |
O |
223 |
V |
321 |
|
В |
112 |
I |
133 |
P |
231 |
W |
322 |
|
С |
113 |
J |
211 |
Q |
232 |
X |
323 |
|
В |
121 |
K |
212 |
R |
233 |
Y |
331 |
|
D |
122 |
L |
213 |
S |
311 |
Z |
332 |
|
F |
123 |
M |
221 |
T |
312 |
. |
333 |
|
G |
131 |
N |
222 |
U |
313 |
|
|
|
|
|
|
|
|
|
|
|
|
Код Трисиме является примером, так называемого, равномерного кода (такого, в котором все кодовые комбинации содержат одинаковое число знаков - в данном случае три). Пример неравномерного кода - азбука Морзе.
3. Кодирование чисел знаками различных систем счисления
3. Кодирование текстовой информации байтами
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
Традиционно, для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события):
К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255 [5, c. 92].
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой кодировке. Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Одному и тому же двоичному коду ставится в соответствие различные символы.
|
|
|
|
|
|
|
|
Двоичный код |
Десятичный код |
КОИ8 |
СР1251 |
СР866 |
Мас |
ISO |
|
11000010 |
194 |
б |
В |
- |
- |
Т |
|
|
|
|
|
|
|
|
|
Впрочем, в большинстве случаев о перекодировке текстовых документов заботится на пользователь, а специальные программы - конверторы, которые встроены в приложения.
Начиная с 1997 г. последние версии Microsoft Windows&Office поддерживают новую кодировку Unicode, которая на каждый символ отводит по 2 байта, а, поэтому, можно закодировать не 256 символов, а 65536 различных символов.
Чтобы определить числовой код символа можно или воспользоваться кодовой таблицей, или, работая в текстовом редакторе Word. Для этого в меню нужно выбрать пункт "Вставка" - "Символ", после чего на экране появляется диалоговая панель Символ. В диалоговом окне появляется таблица символов для выбранного шрифта. Символы в этой таблице располагаются построчно, последовательно слева направо, начиная с символа Пробел (левый верхний угол) и, кончая, буквой "я" (правый нижний угол).
Для определения числового кода символа в кодировке Windows (СР1251) нужно при помощи мыши или клавиш управления курсором выбрать нужный символ, затем щелкнуть по кнопке Клавиша. После этого на экране появляется диалоговая панель Настройка, в которой в нижнем левом углу содержится десятичный числовой код выбранного символа.
Одним битом можно закодировать два значения: Да или Нет (1 или 0).
Двумя битами можно закодировать уже четыре значения: 00, 01, 10, 11.
Тремя битами кодируются 8 разных значений [1, c. 74].
Добавление одного бита удваивает количество значений, которое можно закодировать. При восьми битах уже можно закодировать 256 разных значений. Нетрудно догадаться, что если бы в байте было 9 битов, то одним байтом можно было бы закодировать 512 разных значений, а если бы в нем было 10 битов, то 1024 и т. д.
|
|
|
|
|
|
|
|
|
|
Биты |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Количество кодируемых значений |
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
|
|
|
|
|
|
|
|
|
|
|
Но все-таки в байте не 9 и не 10 битов, а только 8, и потому с его помощью кодируют 256 разных значений. Много это или мало? Смотря для чего. Давайте посмотрим, как с помощью байтов кодируют текстовую информацию.
В русском языке 33 буквы (символа) -- для их кодирования достаточно 33 различных байтов. Если мы хотим различать прописные (заглавные) и строчные буквы, то потребуется 66 байтов. Для строчных и прописных букв английского языка хватит еще 52 символов -- получается 118. Добавим сюда цифры (от 0 до 9), все возможные знаки препинания: точку, запятую, тире, восклицательный и вопросительный знаки. Добавим скобки: круглые, квадратные и фигурные, а также знаки математических операций: +, -, =, /, *. Добавим специальные символы, например такие, как: %,$,&, @, -- мы видим, что все их можно выразить восемью битами, и при этом еще останутся свободные коды, которые можно использовать для других целей.
Дело осталось за малым: надо всем людям мира договориться о том, каким кодом (от 0 до 255) должен кодироваться каждый символ. Если, например, все люди будут знать, что код 33 означает восклицательный знак, а код 63 -- знак вопросительный, то текст, набранный на одном компьютере, всегда можно будет прочитать и распечатать на другом компьютере.
Такая всеобщая договоренность об одинаковом использовании чего-либо называется стандартом. Стандарт устанавливает таблицу, в которой записано, каким кодом должен кодироваться каждый символ. Такая таблица называется таблицей кодов. В этой таблице должно быть 256 строк, в которых записывается, какой байт какому символу соответствует [3, c. 34].
Но здесь-то и начались проблемы. Дело в том, что символы, которые хороши для одной страны, не подходят для другой. В Греции используются одни буквы, в Турции -- другие. То, что подходит для Америки, не годится для России, а то, что подходит для России, не подходит для Германии.
Поэтому было принято следующее решение. Таблицу кодов разделили пополам. Первые 128 кодов (с 0 до 127) должны быть стандартными и обязательными для всех стран и всех компьютеров, а во второй половине (с кода 128 до кода 255) каждая страна может делать все, что ей угодно, и создавать в этой половине свой стандарт -- национальный.
Первую (международную) половину таблицы кодов называют таблицей ASCII -- ее ввел американский институт стандартизации ANSI. В этой таблице размещаются прописные и строчные буквы английского алфавита, символы чисел от 0 до 9, все знаки препинания, символы арифметических операций и некоторые другие специальные коды.
За вторую половину кодовой таблицы (коды от 128 до 255) стандарт ASCII не отвечает Разные страны могут создавать здесь свои таблицы. Часто бывает, что даже в одной стране в этой половине действуют несколько разных стандартов, предназначенных для разных компьютерных систем. В России, например, содержание этой половины таблицы может подчиняться четырем разным стандартам, каждый из которых действует в какой-то своей, особой области [6, c. 29].
4. Кодировочные таблицы
4.1 Стандартная кодировка ASCII
Для кодирования текстовой информации принят международный стандарт ASCII (American Standard Code for Information Interchange), в кодовой таблице которого зарезервировано 128 7-ми разрядных кодов для кодирования [2, c. 24]:
символов латинского алфавита
цифр
знаков препинания
математических символов
Добавление 8-го разряда позволяет увеличить количество кодов таблицы ASCII до 255. Коды от 128 до 255 представляют собой расширение таблицы ASCII. Эти коды в таблице ASCII использованы для кодирования некоторых символов, отличающихся от латинского алфавита, и встречающихся в языках с письменностью, основанной на латинском алфавите, - немецком, французском, испанском и др. Кроме этого, часть кодов использована для кодирования символов псевдографики, которые можно использовать, например, для оформления в тексте различных рамок и текстовых таблиц.
В русском алфавите буква А имеет первое место, а буква Б - второе. У каждой буквы есть своя позиция. Буква Я имеет позицию номер 33. Мы можем считать, что алфавит -- это таблица для кодирования букв.
Стандарт ASCII -- это тоже как бы «алфавит», только компьютерный. Он тоже определяет номер каждого символа. Но символов больше, чем букв, потому что к ним относятся еще и цифры, и знаки препинания, и некоторые специальные символы [4, c. 24].
Выше мы сказали, что с помощью одного байта можно закодировать 256 разных символов. Еще мы узнали, что стандарт ASCII определяет первую половину кодовой таблицы, то есть, кодировку символов, имеющих номера до 127. Но это не совсем так. На самом деле стандарт ASCII первые 32 кода (от 0 до 31) не определяет. Он оставляет их для так называемых управляющих кодов, которые не используются для представления информации, а применяются для управления компьютерами. Эти коды отданы на усмотрение производителей компьютерных систем (у них есть свои соглашения и свои стандарты по применению этих кодов). Еще несколько лет назад людям, работающим с компьютерами, стоило знать некоторые из этих кодов, но сегодня это уже не требуется.
Самый первый символ стандарта ASCII -- это ПРОБЕЛ. Он имеет код 32.
За ним идут специальные символы и знаки препинания (коды с 33 по 47).
Далее идут десять цифр (коды 48-57).
Коды 58--64 используют некоторые математические символы и знаки препинания.
Самое интересное начинается с кодов 65--90. Ими обозначают прописные английские буква от А до Z
Коды 91--96 используются для специальных символов.
Коды 97--122 -- строчные буквы английского алфавита.
Коды 123-127 -- специальные символы.
Коды верхней половины таблицы символов (128-255) отданы для национальных стандартов. Когда мы узнаем о компьютере немного больше, мы разберемся с несколькими российскими стандартами и посмотрим, как кодируются буквы русского языка.
Имея под рукой кодовую таблицу символов, вы можете легко определить, какие слова закодированы следующими байтами
67 79 77 80 85 84 69 82 99 111 109 112 117 116 101 114
У вас раскодирование информации займет пару минут. Компьютер сделает это за несколько миллионных долей секунды.
Таблица кодов ASCII
Для кодирования символов национальных алфавитов используется расширение кодовой таблицы ASCII, то есть 8-ми разрядные коды от 128 до 255.
В языках использующих кириллический алфавит, в том числе русском, пришлось полностью менять вторую половину таблицы ASCII, приспосабливая ее под кириллический алфавит. Но отсутствие согласованных стандартов привело к появлению различных кодовых таблиц для кодирования русскоязычных текстов, среди которых
альтернативная кодовая таблица CP-866
международный стандарт ISO 8859
кодовая таблица фирмы Microsoft CP-1251 (кодировка Windows)
кодовая таблица, применяемая в ОС Unix KOI 8-r [2, c. 87].
4.2 Кодовая таблица Windows (CP-1251)
4.3 Альтернативная кодовая таблица
Сравните:
в альтернативной кодтровке русский прописной символ А имеет код 128,а в кодировке Windows - 192
Заключение
В результате проделанной работы нами: проведен анализ литературы по теме исследования; рассмотрен процесс обработки текста; рассмотрена сущность понятия кодирования информации; охарактеризован процесс кодирования и декодирования; проанализировано кодирование текстовой информации байтами; выделены основные кодировочные таблицы: стандартная кодировка ASCII, кодовая таблица Windows (CP-1251), альтернативная кодовая таблица.
Приведем основные теоретические результаты работы:
1. Процессы изменения формы представления текста часто сводятся к процессам его кодирования и декодирования и проходят одновременно с процессами сбора и передачи информации.
2. Для кодирования текстовой информации принят международный стандарт ASCII (American Standard Code for Information Interchange), в кодовой таблице которого зарезервировано 128 7-ми разрядных кодов для кодирования
3. В языках использующих кириллический алфавит, в том числе русском, пришлось полностью менять вторую половину таблицы ASCII, приспосабливая ее под кириллический алфавит. Но отсутствие согласованных стандартов привело к появлению различных кодовых таблиц для кодирования русскоязычных текстов, среди которых
альтернативная кодовая таблица CP-866
международный стандарт ISO 8859
кодовая таблица фирмы Microsoft CP-1251 (кодировка Windows)
кодовая таблица, применяемая в ОС Unix KOI 8-r
Таким образом, цель работы, заключающаяся в рассмотрении и анализе процесса кодирования текстовой информации достигнута, задачи выполнены.