

Часть 2: Построение нечетко-логического алгоритма распознавания голосовых команд
Целью второй части домашнего задания является ознакомление с алгоритмом сравнения слов, построенном на основе аппарата нечеткой логики, а также разработка модели распознавания в системе Fuzzy Logic toolbox и анализ полученной модели.
2.1 Общие сведения
Технология нечеткого моделирования в последнее время начала обширно использоваться при решении задач управления и системного анализа и показала хорошие результаты. В основе метода нечеткой логики лежит использование нечетких множеств, об элементах которого можно не просто сказать, принадлежат они данному множеству, или нет, но и оценить степень принадлежности элемента данному множеству. Другими словами, для нечеткой модели предполагается обработка неточных входных значений. Поэтому нечеткую логику целесообразно использовать в задачах, где присутствует некоторая неопределенность, исключающая использование точных количественных методов и подходов, или дающая низкий результат при их использовании.
Предлагаемая
модель будет сравнивать вектор признаков
записанного слова
![]() с векторами признаков базы знаний.
Каждая компонента сравнивается с
соответствующей компонентой каждого
из слов базы. В результате система
сформирует набор векторов соответствий,
в которых будут содержаться значения
в интервале от 0 до 1. По этим значениям
программа будет покомпонентно сравнивать
каждое слово из базы с искомым. В
завершении программа рассчитает,
насколько искомое слово в целом похоже
на каждое из слов базы.
с векторами признаков базы знаний.
Каждая компонента сравнивается с
соответствующей компонентой каждого
из слов базы. В результате система
сформирует набор векторов соответствий,
в которых будут содержаться значения
в интервале от 0 до 1. По этим значениям
программа будет покомпонентно сравнивать
каждое слово из базы с искомым. В
завершении программа рассчитает,
насколько искомое слово в целом похоже
на каждое из слов базы.
Для составления нечеткой модели распознавания будем использовать пакет Fuzzy Logic toolbox системы моделирования Matlab.
2.2 Ознакомление с главным окном программы FuzzyLogictoolbox
Запустите систему Matlab. (Версии 7.0 и выше). Для входа в программу Fuzzy logic toolbox введите в командной строке слово fuzzy и нажмите ввод. Появится главное окно программы FIS editor (рис. 11):
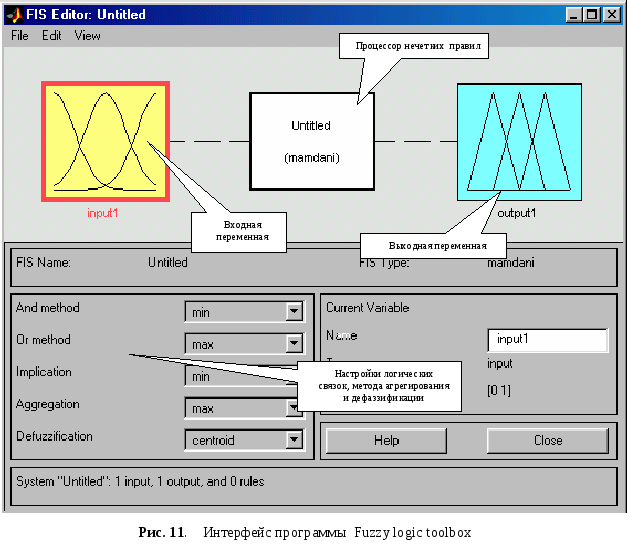
График на желтом фоне – входная переменная, пока одна (в данном задании их семь: в этих переменных будут содержаться значения разности амплитуд двух соседних точек). Каждая входная переменная будет обозначать соответствующую амплитуду. Затем для каждого слова построим график функции принадлежности, представляющий собой относительное значение амплитуды слова в данной точке. Щелчком мыши по серому прямоугольнику вызываем редактор базы правил, с помощью которых будет строиться конечный вывод. Справа - выходная переменная (для нашего случая их не одна, а шесть, по одной для каждого слова); значения этих переменных будут характеризовать похожесть введенного слова на каждое из базовых. Каждой переменной можно присвоить имя, щелкнув мышью по ее рисунку, а затем ввести имя в поле Name. Необходимо сразу изменить значение поля defuzzification на значение som и And Method на prod. Остальные поля не трогаем, они предназначены для настроек нечеткой дизъюнкции, импликации и других параметров.
2.3 Создание входных переменных
Для создания входных и выходных переменных используется следующая последовательность действий: edit -> add variable, далее input для создания входной переменной, и output – для выходной. Создайте еще 6 входных, и пять выходных переменных. (Таким образом, всего будет сформировано 13 переменных). Далее, необходимо присвоить имена переменным: входным – a1, a2... a7, выходным соответственно имена тех слов, с которыми работаете (например, «odin», «dva», и т.д.). Далее, сделайте двойной щелчок на первой входной переменной a1. Появится такое окно редактора переменных (рис. 12):
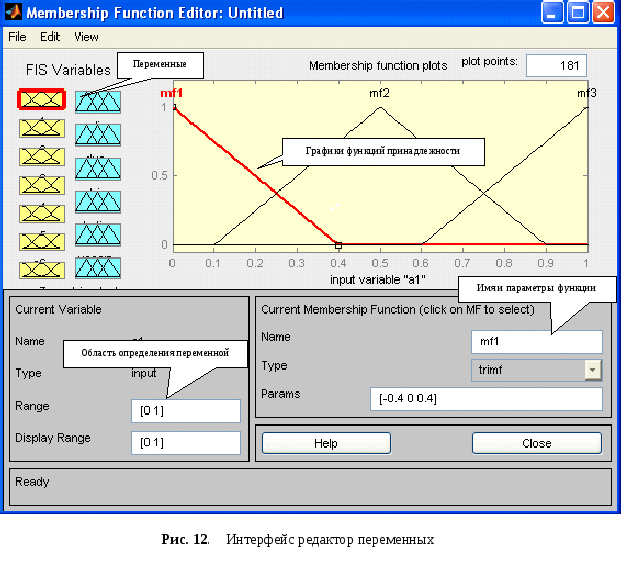
Слева представлены сами переменные: желтые-входные, синие-выходные. В поле «range» будем формировать область определения переменной. Рассмотрим порядок редактирования входной переменной. Она имеет пока три функции принадлежности (mf1, mf2, mf3). Создайте еще три (в меню «edit» выберите «add mfs»), в появившемся окне в поле «number of mfs» установится значение 3. Нажмите ОК. Теперь их 6 - по одной для каждого слова. Данные функции будут показывать значения амплитуды в конкретной точке (переменная – сама точка, функции принадлежности – ее значение с некоторым разбросом). Зададим значения для этих функций. Для этого слева в окне редакторе должна быть выделена первая входная переменная. Вернемся к нашей базе относительных значений, сформированной в первой части домашнего задания. В область первой переменной будем заносить значения из столбика A2-A1 нашей базы. Для этого сначала зададим область определения переменной. Взгляните на 1 столбик базы, затем посмотрите, какое слово имеет минимальное значение в данной точке. Зададим некоторый разброс, например, 40 и вычтем его из значения переменной. Введем получившееся значение в поле «range» и получим нижний предел области определения. Затем в то же поле через пробел введем самое большое значение переменной, плюс 40. Это значение соответствует верхнему пределу области определения.
После того, как область определения задана, приступим к функциям принадлежности. Для этого выберите функцию mf1, щелкнув мышью на ее графике. В поле «name» должно отобразиться ее название. Далее переименуйте его, заменив первым словом из базы (например, «odin»). Итак, у нас выделен график слова «один». Введем его значение. Для этого в поле «params» следует очистить содержимое квадратных скобок, затем ввести в это поле значение из базы (это будет значение, которое на 100 % принадлежит слову «odin» в данной точке). Смысл проводимых действий заключается в том, что с помощью нечеткой модели мы будем судить о принадлежности значения в данной точке тому или иному слову с некоторой вероятностью, а затем, анализируя все точки, определим степени принадлежности введенных значений тому или иному слову. Слева и справа в этом поле через пробел нужно ввести значения, при которых мы будем считать, что функция принадлежности не принадлежит данному слову. Разброс возьмем произвольный, но совсем малый. (Кстати, в качестве дополнительного задания можете подумать, как вычислить это значение экспериментально при большем количестве частот для каждого слова, базируясь на таблицах из первой части домашнего задания). Таким образом, если в базе значение слова в данной точке равно 20, то поле «params» будет выглядеть следующим образом: [-20 20 60]. Те же действия необходимо проделать со всеми функциями принадлежности данной переменной, а также с другими входными переменными, занеся в них значения из соответствующих столбцов базы. Таким образом, вся наша таблица из первой части работы окажется заполненной в программе Fuzzy Logic. Данная процедура получила название фаззификации переменных (т.е. «внесения нечеткости» в значения переменных).
Если все прошло благополучно, то можно приступить к оформлению выходных переменных.