

1.4. Построение ачх каждого слова и занесение данных в программу Excel
Для построения АЧХ откроем окно программы Spectra_lab. В меню «Mode» выбираем «Post Process». Для анализа ограничимся частотным диапазоном от 50 Гц до 4 кГц. С этой целью необходимо сделать следующее: щелчком правой кнопки мыши по рабочей области выбрать во всплывающем меню пункт «Properties»: появится некая форма. Укажите стартовую и конечную частоту в левом нижнем углу формы и нажмите OK.
Далее выберите пункты меню «Infinite» и «PeakHold», после чего нажмите кнопку «Run»; появится АЧХ. Для запоминания значений соответствующей АЧХ нажмите любую кнопку от 1 до 4. Чтобы на экране отображались графики только некоторых АЧХ необходимо убрать галочки рядом с кнопками 1– 4. Затем щелчком правой кнопки мыши по рабочей области вызовите всплывающее меню и выберите пункт «copy as text».
Теперь открываем программу Excel. Выделяем первую ячейку первого столбца. Вставляем слово. Теперь проделайте тоже с остальными двумя вариантами первого слова и занесите данные в таблицу. Столбик Freq можно оставить только один остальные удалите. В общем, приведите таблицу к виду, показанному на рис. 5.

Для дальнейших действий необходимо определить АЧХ пустого микрофона, что можно сделать с помощью программы CoolEdit или Spectralab. При использовании программы Spectralab перейдите в режим Recorder и нажмите Rec. Заметим, что чем больше времени занимает запись, тем точнее измерение (достаточно 10…15 сек). Сохраните звуковой файл и занесите данные в таблицу.
Также в таблицу необходимо занести следующие данные:
среднее значение амплитуды на данной частоте (АМП1+АМП2+АМП3)/3;
«чистый сигнал» - вычитание микрофонной амплитуды из амплитуды слова. (Для этого, из среднего значения амплитуды на соответствующей частоте вычитается амплитуда микрофонного сигнала).
Постройте график этого столбца. В итоге у вас должно было получиться нечто подобное (рис. 6).
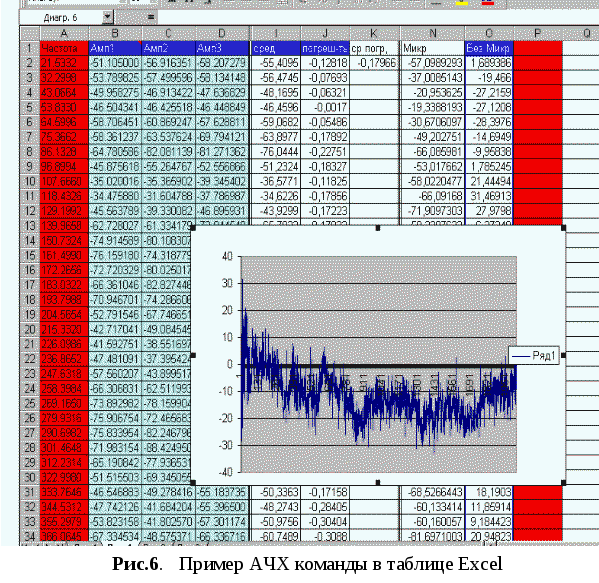
То же самое необходимо проделать с остальными словами. Данные лучше сохранять в одном xls-документе, поместив таблицы на разные листы.
1.5 Построение векторов признаков
Теперь наступила важнейшая часть работы: выделение характерных для каждого слова признаков и помещение их в таблицу. В качестве признаков каждого слова примем амплитуды его АЧХ на восьми частотах. Удобно сделать следующее: завести новый лист в xls-документе, скопировать в него графики АЧХ каждого слова с вырезанным шумом. Расположите их один под другим как на рис. 7.

В общем случае, для получения большего количества признаков для распознавания, следует использовать большее количество частот сравнения. Проведя анализ АЧХ (рис. 7), можно выделить частоты, на которых амплитуды разных слов наиболее различаются. Для удобства проведите перпендикулярно им четкие линии. Теперь возьмите из таблиц численные значения, и занесите их в таблицу, как показано на рис. 8 -9.
Замечание.
Качество распознавания системы зависит от правильного выбора частот, на которых амплитуды разных слов наиболее различаются. После построения АЧХ, визуально трудно определить различия (так как присутствуют высокочастотные шумы), поэтому рекомендуется воспользоваться (или написать самостоятельно) программу, выполняющую высокочастотную фильтрацию.

Отметим, что сравнивать абсолютные значения сигналов бессмысленно, т.к. записанный на другой громкости или сказанный громче/тише звук будет отличаться. Поэтому предлагается составить базу признаков следующим образом: из восьми имеющихся значений для каждого слова составим семь, так, чтобы: Aотн = A(n+1) - An, где Aотн – относительное значение амплитуды слова, взятое из разности значений двух соседних точек абсолютных значений. (Для упрощения можно взять те же частоты, что и в рассмотренном примере - А1 = 646; А2 = 1270.5; А3 = 3757.5; А4 = 2164; А5 = 2939.2; А6 = 1065.9; А7 = 3197.7; А8 = 2228.7 Гц). В результате должно получиться примерно то, что изображено на рис. 9.

После составления векторов признаков, на которых будет происходить распознавание, необходимо построить вектора признаков каждого произнесенного слова. Таким образом, на каждую команду будет приходиться по четыре вектора признаков: один, на котором будет строиться распознавание и три необходимые для тестирования системы.
Первая часть работы на этом заканчивается. Осталось составить базу данных, в которой будут храниться эти векторы признаков, затем написать программу, вычитающую векторы, которая будет сравнивать введенные амплитуды на этих частотах с базой и определять, что это за слово. Пример представлен на рис. 10.

Таким образом, в результате проведенных в первой части работы действий была составлена база знаний, содержащая вектора признаков. (Она представляет собой таблицу, в которой присутствуют значения разности амплитуд двух условных соседних точек сравнения для шести произвольных слов). Более точное распознавание возможно с использованием методов нечеткой логики. Этому посвящена вторая часть домашнего задания.