

14. Проверка значимости уравнения регрессии
F-тест – оценивание качества уравнения регрессии – состоит в проверке гипотезы H0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы
где n – число единиц совокупности;
m – число параметров при переменных x.
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл< Fфакт, то H0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл> Fфакт, то H0 – гипотеза не отклоняется и признается статистическая незначимость, надежность уравнения регрессии.
Один из наиболее часто используемых вариантов проверки заключается в следующем. Для полученного уравнения регрессии определяется F-статистика – характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения F-статистики в случае многомерной регрессии имеет вид:
 где:
где:
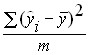 –
объясненная дисперсия – часть дисперсии
зависимой переменной Y
которая объяснена уравнением регрессии;
–
объясненная дисперсия – часть дисперсии
зависимой переменной Y
которая объяснена уравнением регрессии;



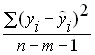 –
остаточная дисперсия
– часть дисперсии зависимой переменной
Y
которая не объяснена уравнением
регрессии, ее наличие является следствием
действия случайной составляющей
–
остаточная дисперсия
– часть дисперсии зависимой переменной
Y
которая не объяснена уравнением
регрессии, ее наличие является следствием
действия случайной составляющей
Как видно из приведенной формулы, дисперсии определяются как частное от деления соответствующей суммы квадратов на число степеней свободы. Число степеней свободы это минимально необходимое число значений зависимой переменной, которых достаточно для получения искомой характеристики выборки и которые могут свободно варьироваться с учетом того, что для этой выборки известны все другие величины, используемые для расчета искомой характеристики.
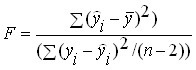 парная регрессия
парная регрессия
Адекватность регрессионной модели оценим с помощью средней ошибки аппроксимации – среднее отклонение расчетных значений от фактических:
Допустимый предел
значений – не более 8-10%.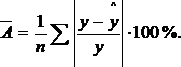
5. Виды нелинейных 1. регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам:
§ полиномы разных
степеней
![]()
§ равностороння
гипербола
![]()
2. регрессии, нелинейные по оцениваемым параметрам. Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
§ степенная
![]()
§ показательная
![]()
§ экспоненциальная
![]()
Этот класс моделей делится на два вида:
а) нелинейные модели, внутренне линейные. Модель может быть сведена к линейному виду (используется МНК)
б) нелинейные модели,
внутренне нелинейные. Они не могут быть
сведены к линейному виду, поэтому
используется логарифмирование. Пример:
![]()
\
36-37Идентификация эконометрических уравнений.
При переходе от приведенной формы модели к структурной исследователь сталкивается с проблемой идентификации. Идентификация – единственность соответствия между структурной и приведенной формами модели.
Параметры структурной формы модели по оценкам приведенных коэффициентов можно определить не всегда. Для этого необходимо, чтобы модель была идентифицируемой.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
Выделяют:
1) Точно идентифицируемая модель – все ее уравнения точно идентифицированы. То есть все структурные коэффициенты определяются однозначно (единственным способом) по коэффициентам приведенной формы модели. И число параметров структурной модели равно числу параметров приведенной формы.
2) Неидентифицируемая модель – число приведенных коэффициентов меньше числа структурных коэффициентов. Оценки всех структурных параметров невозможно найти по коэффициентам приведенной модели.
3) Сверхидентифицируемая модель – число приведенных коэффициентов больше числа структурных коэффициентов (на основе приведенной формы можно получить 2 и более значений одного структурного коэффициента). Практически решаема, но требует применения специальных методов.
На идентификацию проверяются все уравнения модели. Модель считается идентифицируемой, если все уравнения идентифицируемы; сверх – если хоть одно сверхидентифицируемо, а остальные точно идентифицируемы. Если среди всех уравнений модели есть хотя бы одно неидентифицированное, то вся модель считается неидентифицированной.
Правила идентификации
Введем следующие обозначения:
М- число экзогенных (предопределенных) переменных в модели;
т- число экзогенных (предопределенных) переменных в данном уравнении;
К - число эндогенных переменных в модели;
k - число эндогенных переменных в данном уравнении.
А) Необходимое (но недостаточное) условие идентификации.
Для того чтобы
уравнение модели было идентифицируемо,
необходимо, чтобы число предопределенных
переменных, отсутствующих в данном
уравнении, было не меньше «числа
эндогенных переменных, входящих в
уравнение минус 1», т.е.:
![]()
Если
![]() ,
уравнение точно идентифицировано.
,
уравнение точно идентифицировано.
Если , уравнение сверхидентифицировано.
Либо D+1=H (H – число эндогенных переменных в уравнении; D – число отсутствующих экзогенных переменных).
Эти правила следует применять к структурной форме модели.
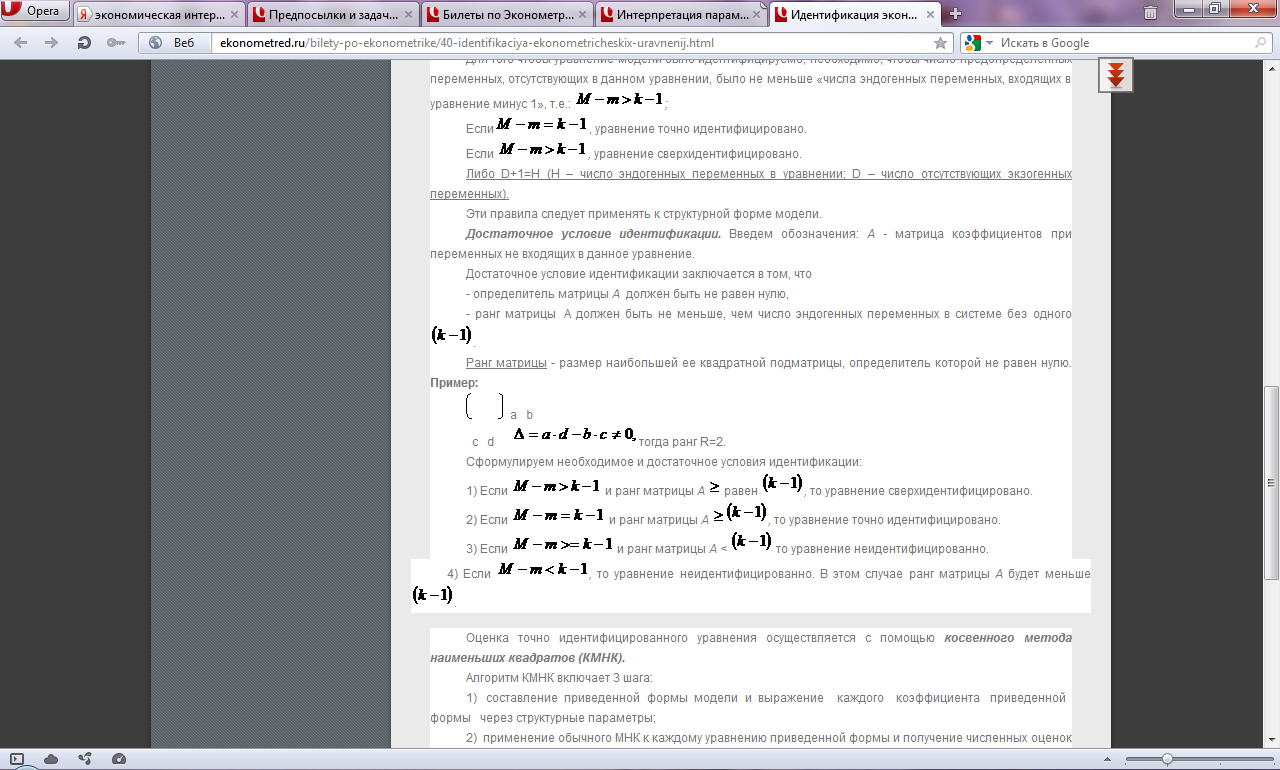
Достаточное условие идентификации. Введем обозначения: А - матрица коэффициентов при переменных не входящих в данное уравнение.
Достаточное условие идентификации заключается в том, что
- определитель матрицы А должен быть не равен нулю,
- ранг матрицы А
должен быть не меньше, чем число эндогенных
переменных в системе без одного![]() Ранг
матрицы - размер наибольшей ее квадратной
подматрицы, определитель которой не
равен нулю
Ранг
матрицы - размер наибольшей ее квадратной
подматрицы, определитель которой не
равен нулю
Оценка точно идентифицированного уравнения осуществляется с помощью косвенного метода наименьших квадратов (КМНК).
Алгоритм КМНК включает 3 шага:
1) составление приведенной формы модели и выражение каждого коэффициента приведенной формы через структурные параметры;
2) применение обычного МНК к каждому уравнению приведенной формы и получение численных оценок приведенных параметров;
3) определение оценок параметров структурной формы по оценкам приведенных коэффициентов, используя соотношения, найденные на шаге 1.
Оценка сверхидентифицированного уравнения осуществляется при помощи двухшагового метода наименьших квадратов.
Алгоритм двухшагового МНК включает следующие шаги:
1) составление приведенной формы модели;
2) применение обычного МНК к каждому уравнению приведенной формы и получение численных оценок приведенных параметров;
3) определение расчетных значений эндогенных переменных, которые фигурируют в качестве факторов в структурной форме модели;
4) определение структурных параметров каждого уравнения в отдельности обычным МНК, используя в качестве факторов входящие в это уравнение предопределенные переменные и расчетные значения эндогенных переменных, полученные на шаге 1 .