

Системы с распределенной памятью – mpp.
Примером системы с распределенной памятью может служить массивно-параллельная архитектура – MPP15. Массивно-параллельные системы состоят из однородных вычислительных узлов, каждый из которых включает в себя:
-
один или несколько процессоров
-
локальную память, прямой доступ к которой с других узлов невозможен
-
коммуникационный процессор или сетевой адаптер
-
устройства ввода/вывода
Схема MPP системы, где каждый вычислительный узел (ВУ) имеет один процессорный элемент (например, RISC-процессор, одинаковый для всех ВУ), память и коммуникационное устройство, изображена на рисунке.
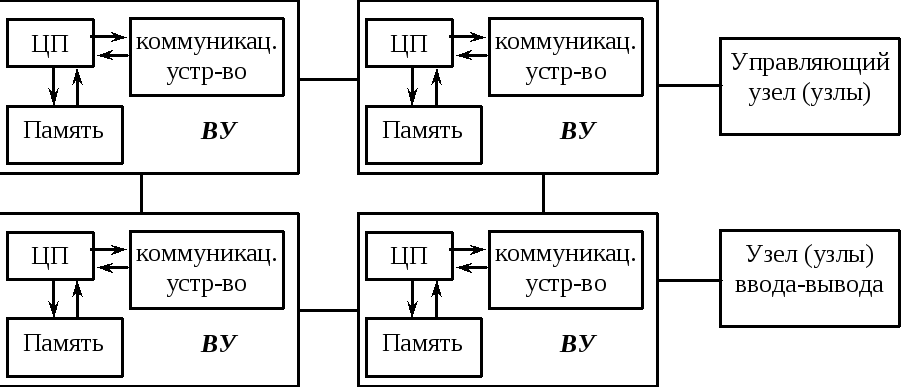
Рис. 22 Архитектура MPP.
Помимо вычислительных узлов, в систему могут входить специальные узлы ввода-вывода и управляющие узлы. Узлы связаны между собой посредством высокоскоростной среды передачи данных определенной топологии. Число процессоров в MPP-системах может достигать нескольких тысяч.
Поскольку в MPP-системе каждый узел представляет собой относительно самостоятельную единицу, то, как правило, управление массивно-параллельной системой в целом осуществляется одним из двух способов:
-
На каждом узле может работать полноценная операционная система, функционирующая отдельно от других узлов. При этом, разумеется, такая ОС должна поддерживать возможность коммуникации с другими узлами в соответствии с особенностями данной архитектуры.
-
«Полноценная» ОС работает только на управляющей машине, а на каждом из узлов MPP-системы работает некоторый сильно «урезанный» вариант ОС, обеспечивающий работу задач на данном узле.
В массивно-параллельной архитектуре отсутствует возможность осуществлять обмен данными между ВУ напрямую через память, поэтому взаимодействие между процессорами реализуется с помощью аппаратно и программно поддерживаемого механизма передачи сообщений между ВУ. Соответственно, и программы для MPP-систем обычно создаются в рамках модели передачи сообщений.
Системы с общей памятью – smp.
В качестве наиболее распространенного примера систем с общей памятью рассмотрим архитектуру SMP16 – симметричную мультипроцессорную систему. SMP-системы состоят из нескольких однородных процессоров и массива общей памяти, который обычно состоит из нескольких независимых блоков. Слово «симметричный» в названии данной архитектуры указывает на то, что все процессоры имеют доступ напрямую (т.е. возможность адресации) к любой точке памяти, причем доступ любого процессора ко всем ячейкам памяти осуществляется с одинаковой скоростью. Общая схема SMP-архитектуры изображена на Рис. 23.

Рис. 23 Архитектура SMP
Процессоры подключены к памяти либо с помощью общей шины, либо с помощью коммутатора. Отметим, что в любой системе с общей памятью возникает проблема кэширования: так как к некоторой ячейке общей памяти имеет возможность обратиться каждый из процессоров, то вполне возможна ситуация, когда некоторое значение из этой ячейки памяти находится в кэше одного или нескольких процессоров, в то время как другой процессор изменяет значение по данному адресу. В этом случае, очевидно, значения, находящиеся в кэшах других процессоров, больше не могут быть использованы и должны быть обновлены. В SMP-архитектурах обычно согласованность данных в кэшах поддерживается аппаратно.
Очевидно, что наличие общей памяти в SMP-архитектурах позволяет эффективно организовать обмен данными между задачами, выполняющимися на разных процессорах, с использованием механизма разделяемой памяти. Однако сложность организации симметричного доступа к памяти и поддержания согласованности кэшей накладывает существенное ограничение на количество процессоров в таких системах – в реальности их число обычно не превышает 32 – в то время, как стоимость таких машин весьма велика. Некоторым компромиссом между масштабируемостью и однородностью доступа к памяти являются NUMA-архитектуры, которые мы рассмотрим далее.