-
Замещение страниц. Алгоритм «Часы».
Следующая группа алгоритмов позволяют учитывать более адекватно старение и использование страниц и, соответственно, осуществлять выбор страницы для откачки.
Алгоритм LRU (Least Recently Used — «наименее недавно» – наиболее давно используемая страница) основан на достаточно сложной аппаратной схеме и действует по следующей схеме.
Пускай имеется N страниц. Для решения задачи в компьютере имеется битовая матрица, размером N × N, которая изначально обнуляется. Когда происходит обращение к i-ой странице, то все биты i-ой строки устанавливаются в 1, а весь i-ый столбец обнуляется. Соответственно, когда понадобится выбрать страницу для откачки, то выбирается та страница, для которой соответствующая строка хранит наименьшее двоичное число.
Рассмотренный алгоритм хорош тем, что достаточно адекватно учитывает интенсивность использования страниц, но этот алгоритм требует сложной аппаратной реализации.
Альтернативой указанному алгоритму может служить алгоритм NFU (Not Frequently Used — редко использовавшаяся страница), основанный на использовании программных счетчиков страниц.
Данный алгоритм подразумевает, что с каждой физической страницей с номером i ассоциирован программный счетчик Counti. Изначально для всех i происходит обнуление счетчиков. А затем, по таймеру происходит увеличение значений всех счетчиков на величину интенсивности использования, т.е. на величину R-признака: Counti = Counti + Ri. Иными словами, если за последний таймаут было обращение к странице, что значение счетчика возрастает, иначе — не изменяется. Соответственно, для откачки выбирается страница с минимальным значением счетчика Counti.
Данная модель также является достаточно адекватной, но она имеет ряд важных недостатков. Первый связан с тем, что счетчик хранит историю: например, какая-то страница в некоторый период времени интенсивно использовалась, и значение счетчика стало настолько большим, что при прекращении работы с данной страницей значение счетчика достаточно долго не даст откачать эту страницу. А второй недостаток связан с тем, что при очень интенсивном обращении к странице возможно переполнение счетчика.
Чтобы сгладить указанные недостатки, существует модификация данного алгоритма, основанного на том, что каждый раз по таймеру значение счетчика сдвигается на 1 разряд влево, после чего последний (правый) разряд устанавливается в значение R-признака.
-
Сегментное распределение
Недостатком страничного распределения памяти является то, что при реализации этой модели процессу выделяется единый диапазон виртуальных адресов: от нуля до некоторого предельного значения. С одной стороны, ничего плохо в этом нет, но это свойство оказывается неудобным по следующей причине. В процессе есть команды, есть статические переменные, которые, по сути, являются разными объединениями данных с различными характеристиками использования. Еще большие отличия в использовании иллюстрируют существующие в процессе стек и область динамической памяти, называемой также кучей. И модель страничной организации памяти подразумевает статическое разделение единого адресного пространства: выделяются область для команд, область для размещения данных, а также область для стека и кучи. При этом зачастую стек и куча размещаются в единой области, причем стек прижат к одной границе области, куча — к другой, и растут они навстречу друг другу. Соответственно, возможны ситуации, когда они начинают пересекаться (ситуация переполнения стека). Или даже если стек будет располагаться в отдельной области памяти, он может переполнить выделенное ему пространство. Итак, вот основные недостатки страничного распределения памяти.
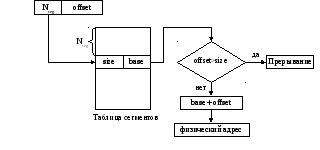
Избавиться от указанных недостатков на концептуальном уровне призвана модель сегментного распределения памяти (Рис. 131.). Данная модель представляет каждый процесс в виде совокупности сегментов, каждый из которых может иметь свой размер. Каждый из сегментов может иметь собственную функциональность: существуют сегменты кода, сегменты статических данных, сегмент стека и т.д. Для организации работы с сегментами может использоваться некоторая таблица, в которой хранится информация о каждом сегменте (его номер, размер и пр.). Тогда виртуальный адрес может быть проинтерпретирован, как номер сегмента и величина смещения в нем.