

4.2. Сетевая модель данных
Применение сетевой модели данных предполагает наличие сетевой структуры моделируемой предметной области. Вся область рассматривается как совокупность частей, связанных между собой бинарными связями различных типов (рис. 4.2). Допускаются связи между различными уровнями, т.е. сетевая модель представляет собой пересекающиеся иерархии. В сетевой модели потомок может иметь любое число предков.
















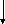






Рис. 4.1. Иерархическая модель данных Рис. 4.2. Сетевая модель данных
Сетевая модель по сравнению с иерархической является более универсальной. В ней возможен доступ по ключу не только к объекту на высшем уровне иерархии, но и к объектам любого уровня. В данной модели возможно обеспечить связи «многие-ко-многим», отсутствие дублирования данных и формирование запросов. Однако ее существенными недостатками является сложность, т.е. обилие понятий, вариантов их взаимосвязей и особенностей реализации. Такие усложнения приводят к необходимости хранения вместе с данными множества указателей, а также допустимость только навигационного принципа доступа к данным. В сетевой модели ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого практического распространения. Типичным представителем сетевых БД является IDMS (Integrated Database Management System) компании Cullinet Software. Другие примеры: db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
4.3. Реляционная модель данных
Описание отображаемой предметной области базируется на гипотезе о том, что моделируемую область можно рассматривать как совокупность нескольких множеств, между элементами которых существуют некоторые отношения.
Основными элементами модели являются реляционные таблицы3 и связи между ними. В каждой таблице содержатся сведения об одной сущности. В исходных таблицах, из которых данные вводятся в таблицы БД, столбцы должны иметь уникальные имена, содержать данные только одного типа (либо числа, либо текст и т.п.), быть неделимыми и не иметь пустых и повторяющихся строк. Структура таблицы определяется составом и последовательностью ее полей с указанием типа элементарного данного, размещаемого в поле. Основными типами данных являются: числовой, текстовый, дата/время, логический. Содержание таблицы заключено в ее записях. Каждая запись содержит данные о конкретном экземпляре сущности. Для однозначного определения каждой записи таблица должна иметь уникальный ключ (ключевое поле или совокупность нескольких полей), называемый первичным ключом. Так в таблице «Заказ» (табл.2.2) ключевым полем может быть «Номер заказа», если нумерация не зависит от даты заказа, и «Номер заказа + Дата заказа», если каждый день вводится новая нумерация (1, 2, …, N). По значению ключа отыскивается единственная запись.
Связи между таблицами дают возможность совместно использовать данные из разных таблиц. Это связи вида «один – к – одному» (1:1) и «один - ко - многим» (1:M). В последнем случае одному значению первичного ключа в одной таблице соответствует несколько записей с таким же значением соответствующего поля (вторичного ключа) в другой. При этом первая таблица называется главной, а вторая подчиненной. Например, при связывании таблиц «Клиент» и «Заказ» (рис. 2.1 и табл. 2.2, табл. 2.3) одной записи со значением поля «Код Клиента», равным 1251, может соответствовать несколько записей с таким же значением поля «Код клиента» 1251 в таблице «Заказ» (один клиент может сделать несколько заказов). Таким образом, связь каждой пары таблиц обеспечивается одинаковыми полями, в них – ключом связи, являющимся первичным ключом главной таблицы. Связь вида M:N («многие - ко - многим») преобразуется с использованием дополнительной таблицы-вставки в две связи вида «один - ко - многим». При этом ключ таблицы-вставки будет совокупностью ключей исходных таблиц.
Операции, производимые над реляционными таблицами, разделяются на традиционные операции над множествами: объединение, пересечение, вычитание, Декартово произведение, и операции реляционной алгебры: выбор, проекция и соединение. Выбор – это представление таблицы в таком виде, когда в нее входят только те записи, которые имеют заданные значения в заданных полях. Например, из таблицы «Клиент» выбираются только те записи, в которых поле «Город» имеет значение Москва. Проекция – это представление таблицы в таком виде, когда в нее включаются не все, а только заданные поля. Например, из таблицы «Заказ» выбираются только поля «Номер заказа», «Дата заказа» и поле «Оплачено». Соединение – это операция над двумя связанными таблицами. Результатом является новая таблица, представляющая собой комбинацию из двух таблиц. Она формируется путем сопоставления значений записей из главной и подчиненной таблиц таким образом, что каждая строка из главной таблицы объединяется со строками из подчиненной, для которых выполняется условие равенства значений ключа связи. Для рассматриваемого примера при соединении таблиц «Клиент» и «Заказ» результирующая таблица может отображать список клиентов и сделанных ими заказов.
Основными ограничениями реляционной модели являются функциональные зависимости между полями реляционных таблиц. Считается, что одно поле в таблице функционально определяет другое, если каждому значению первого поля соответствует единственное значение второго. Иными словами, второе поле функционально зависит от первого. Например, в таблице «Должность» (табл. 4.1), состоящей из полей: «ФИО сотрудника» и «Должность», каждому сотруднику соответствует одна должность, но одна и та же должность (например, экономист) может быть у нескольких сотрудников. Очевидно, что между ключевым полем и не ключевым существует функциональная зависимость.
Таблица 4.1.
Должность

Некоторые виды функциональной зависимости могут приводить к избыточности данных в базе. Для ее устранения (минимизации) при проектировании реляционных БД используется нормализация – процесс преобразования данных от одной нормальной формы к другой, боле высокой. Нормальные формы (НФ) формируются последовательно и по возрастанию (1НФ, 2НФ, 3НФ), и чем больше номер, тем больше ограничений на хранимые значения должно соблюдаться в соответствующей реляционной таблице. Любая реляционная таблица находится в первой нормальной форме (1НФ).
Во второй нормальной форме (2НФ) в таблице не должно быть полей, зависящих только от части составного ключа (а не от него целиком). Так, например, в таблице «Булочная» (табл. 4.2), содержащей поля «Хлебозавод», «Продукт», «Цена» и «Количество», цена на одинаковые продукты разных заводов может быть назначена одна. В этом случае ключом будет совокупность полей «Хлебозавод + Продукт». Так как батоны нарезные хлебозаводов «Пекаря», «Кушелевского» и «Каравая» будут стоить одинаково, поле «Цена» будет зависеть только от части ключа – от поля «Продукт». Для устранения неполной функциональной зависимости необходимо разделить исходную таблицу на две. В первой таблице будут поля «Хлебозавод», «Продукт» и «Количество», а во второй – «Продукт» и «Цена».
Таблица может соответствовать второй нормальной форме, однако одно из полей может зависеть от ключа через другое не ключевое поле, что приводит к избыточности. Например, в таблице «Сотрудник» (табл. 4.3), содержащей поля «Сотрудник» (ключ), «Оклад» и «Должность», существует такая зависимость. Поле «Должность» зависит от поля «Сотрудник», а «Оклад» – от «Должности» для данного сотрудника, т.е. «Оклад» зависит от поля «Сотрудник» через не ключевое поле «Должность». Для приведения в соответствие с третьей нормальной формой следует разделить исходную таблицу на две. В первой будут поля «Сотрудник» (ключ) и «Должность», а во второй – «Должность и «Оклад».
Таблица 4.2
Булочная

Таблица 4.3.
Сотрудник

Для обеспечения целостности данных в реляционных БД должны выполняться определенные правила. Так для любой таблицы первичный ключ должен быть уникальным и не пустым (иметь конкретное значение). Для связанных таблиц все связи должны быть реальными, т.е. каждый вторичный ключ в подчиненной таблице должен ссылаться на действующий первичный ключ в главной таблице. В примере «Клиент – Заказ» (рис. 2.12 и табл. 2.1, 2.2) это означает, что если есть записи в таблице «Заказ» с номером клиента 1274, то должна быть запись в таблице «Клиент» с таким номером клиента. Для связанных таблиц правила ссылочной целостности предусматривают действия, которые должны выполняться при вставке, обновлении и удалении записей в одной из таблиц. Так, например, правило «Каскад» требует при удалении (или обновлении) записи в главной таблице удаления (или обновления) всех соответствующих записей в подчиненной таблице. В нашем примере это означает, что если удаляется запись с номером клиента 1251 в таблице «Клиент», то в таблице «Заказ» будут удалены все записи с заказами, сделанными этим клиентом. Правила ссылочной целостности устанавливаются при проектировании БД.
Возможности ускоренного поиска данных в реляционной базе обеспечиваются созданием индексов, в которые выносятся упорядоченные значения (по возрастанию или убыванию) ключа и номера записей исходной таблицы, соответствующие этим значениям. Индексы позволяют при поиске использовать не последовательный просмотр записей до нахождения требуемой, а специальные алгоритмы, простейшим из которых является алгоритм помещения указателя в средину индекса и сравнения ближайшего значения ключа с искомым. Если ближайшее значение ключа в индексе больше искомого значения, то указатель перемещается в средину «верхней» половины таблицы, меньше – в средину «нижней», и опять производится сравнение. Если в таблице N записей, то при самом неблагоприятном варианте искомое значение ключа будет в последней записи, и придется проделать N шагов. Для рассмотренного простейшего алгоритма число шагов при поиске определяется как log 2 N.
Одним из основных достоинств реляционной модели является привычное для пользователя-экономиста представление данных в форме таблиц. Структуры данных легко создавать и понимать, программы для манипулирования данными также пишутся достаточно просто. Другим достоинством является наличие теоретически обоснованных методов получения минимальной избыточности представления данных. Существуют специальные методы нормализации, в частности, средствами некоторых СУБД есть возможность в результате анализа исходной таблицы получить варианты нормализованных таблиц и устранить избыточность.
Существенным недостатком модели можно считать низкое быстродействие при реализации операции соединения. Нормализация данных реляционной модели приводит к значительной фрагментации данных, в то время как в большинстве задач необходимо объединение фрагментированных данных. Недостатком, обусловившим появление многомерной модели, является невозможность использования данных базы аналитиками (а не программистами) для оперативного анализа данных, изменяющихся во времени. Другим недостатком этой модели в последние годы стала считаться идея пассивного множества данных, положенных в ее основу. Этой моделью не предусмотрено описание реального поведения данных, а также в ней ограничены семантические возможности, затруднено представление смысла данных. Это привело к появлению объектно-ориентированной модели данных.