

-
Формирование обучающей и проверочной последовательностей
Как было упомянуто ранее исходную выборку следует разбивать на две подвыборки A и B. Подвыборка A используется для определения коэффициентов модели (обучающая последовательность), а подвыборка B — для определения качества (проверочная последовательность). При этом соотношение количества данных в обеих выборках может быть как 50/50, так и 60/40.
Рассмотрим задачу отыскания правила разбиения всего множества имеющихся изображений (исходного множества) на два подмножества (обучающую и проверочную последовательности) в зависимости от свойств исходного множества.
Пусть
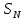 —
основное выборочное пространство
объектов, причем каждому объекту из
—
основное выборочное пространство
объектов, причем каждому объекту из
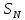 соответствует
одно из вполне определенных изображений
соответствует
одно из вполне определенных изображений
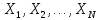 .
Предположим, что
.
Предположим, что
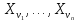 некоторая
перестановка
некоторая
перестановка
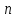 изображений
из
изображений
из
 (n<N).
Будем
говорить о подмножестве
(n<N).
Будем
говорить о подмножестве
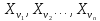 как о v-й
выборке объема
как о v-й
выборке объема
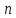 из
конечной совокупности
из
конечной совокупности
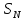 .
Каждая
составляющая этой совокупности может
быть многомерным вектором в пространстве
признаков. Предполагается, что
распределение совокупности остается
неизменным в течение всего наблюдения.
.
Каждая
составляющая этой совокупности может
быть многомерным вектором в пространстве
признаков. Предполагается, что
распределение совокупности остается
неизменным в течение всего наблюдения.
Для
того чтобы определить статистические
свойства конечной совокупности
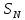 по
выборке
объема
по
выборке
объема
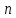 ,
нужно найти такое
,
нужно найти такое
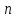 ,
чтобы результаты статистической
обработки любой выборки объема
,
чтобы результаты статистической
обработки любой выборки объема
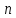 хорошо
согласовались с результатами обработки
всей совокупности. Кроме того, нужно,
чтобы оставшееся подмножество из (
хорошо
согласовались с результатами обработки
всей совокупности. Кроме того, нужно,
чтобы оставшееся подмножество из (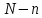 )
элементов
достаточно хорошо характеризовало
конечную совокупность
)
элементов
достаточно хорошо характеризовало
конечную совокупность
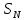 .
.
(*)
Предположим,
что задача состоит в оценке каких-либо
параметров. Допустим, что оценивается
некоторый параметр
 по выборке объема
по выборке объема
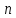 ,
например какой-либо коэффициент
уравнения. Обозначим через
,
например какой-либо коэффициент
уравнения. Обозначим через
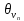 оценку параметра
оценку параметра
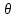 по v-й
выборке объема
по v-й
выборке объема
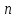 .
Тогда
согласно неравенству Чебышева имеем
.
Тогда
согласно неравенству Чебышева имеем
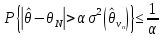 ,
(V.7)
,
(V.7)
где
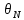 — математическое ожидание оценок
— математическое ожидание оценок
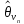 ;
;
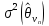 — дисперсия оценок
— дисперсия оценок
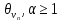 .
.
Очевидно,
что
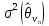 является функцией по крайней мере двух
переменных:
является функцией по крайней мере двух
переменных:
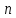 и
и
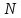 .
При
.
При
 эта
функция обращается в нуль, а по мере
возрастания разности
эта
функция обращается в нуль, а по мере
возрастания разности
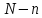 также
возрастает. Обозначим ее следующим
образом:
также
возрастает. Обозначим ее следующим
образом:
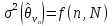 .
.
В
неравенстве (V.7)
величина
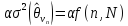 определяет
порог, который с вероятностью, не большей,
чем
определяет
порог, который с вероятностью, не большей,
чем
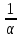 , не будет превышен отклонением оценки
параметра от его среднего значения,
определенного по всем возможным выборкам
объемом
, не будет превышен отклонением оценки
параметра от его среднего значения,
определенного по всем возможным выборкам
объемом
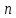 .
Назовем
этот порог порогом
достоверности выборки
объемом
.
Назовем
этот порог порогом
достоверности выборки
объемом
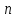 .
.
Для
того чтобы оценки, полученные по обучающей
и проверочной последовательностям,
были одинаково точны, необходимо и
достаточно, чтобы пороги достоверности
этих выборок были равны, т. е. 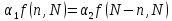 ,
(V.8)
,
(V.8)
где
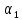 и
и
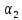 характеризуют
требования, предъявляемые к обучению
и проверке соответственно.
характеризуют
требования, предъявляемые к обучению
и проверке соответственно.
При
выполнении условия (V.8)
пороги достоверности одинаковы и для
обучения и для проверки, но вероятности
их превышения различны и зависят от
выбора
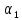 и
и
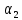 .
В любом случае нужно так выбрать
.
В любом случае нужно так выбрать
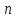 ,
чтобы
удовлетворялось равенство (V.8).
Так, например, при
,
чтобы
удовлетворялось равенство (V.8).
Так, например, при
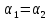 это равенство справедливо при
это равенство справедливо при
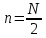 для любых функций. Если же
для любых функций. Если же
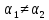 ,
то для определения
,
то для определения
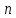 нужно
знать характер функции
нужно
знать характер функции
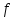 ,
что не всегда возможно. Это затрудняет
общее решение задачи. Но в конкретных
случаях, когда вид функции известен,
задача решается полностью. Например,
если оцениваемым параметром является
математическое ожидание, то
,
что не всегда возможно. Это затрудняет
общее решение задачи. Но в конкретных
случаях, когда вид функции известен,
задача решается полностью. Например,
если оцениваемым параметром является
математическое ожидание, то

где
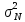 —
дисперсия, определенная по всей выборке
—
дисперсия, определенная по всей выборке
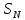 .
В
этом случае должно выполняться равенство
.
В
этом случае должно выполняться равенство

откуда
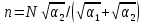 .
(V.9)
.
(V.9)
Задавая
требуемые значения
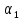 и
и
 ,
можно определить нужный объем обучающей
выборки.
,
можно определить нужный объем обучающей
выборки.
Возникает
вопрос, нельзя ли, основываясь на
статистических свойствах исходного
множества, получить какие-либо рекомендации
по выбору
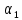 и
и
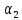 .
Рассмотрим один из возможных подходов
к выбору коэффициентов
.
Рассмотрим один из возможных подходов
к выбору коэффициентов
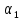 и
и
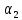 .
В
задаче обучения распознаванию образов.
Для простоты будем считать, что основная
совокупность состоит из элементов
только двух классов:
.
В
задаче обучения распознаванию образов.
Для простоты будем считать, что основная
совокупность состоит из элементов
только двух классов:
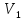 и
и
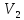 ,
причем
,
причем
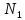 и
и
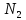 —
числа элементов, принадлежащих классам
—
числа элементов, принадлежащих классам
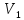 и
и
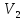 соответственно.
соответственно.
Предлагаемый
подход основан на следующем предположении.
Если при
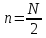 оценки
математического ожидания достаточно
точны, то требования к обучению могут
быть несколько снижены, а требования к
проверке ставятся в прямую зависимость
от степени пересечения подмножеств.
Если же подмножества таковы, что оценки
их математических ожиданий при
оценки
математического ожидания достаточно
точны, то требования к обучению могут
быть несколько снижены, а требования к
проверке ставятся в прямую зависимость
от степени пересечения подмножеств.
Если же подмножества таковы, что оценки
их математических ожиданий при
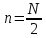 сильно
отличаются от действительных значений,
а пересечение этих подмножеств
незначительно, то для удовлетворительной
классификации следует увеличить точность
оценок увеличением объема обучающей
последовательности. При этом приходится
жертвовать точностью проверки в надежде
на то, что при правильной оценке параметров
классификация будет удовлетворительной.
Если же пересечение подмножеств велико,
то никаким повышением точности оценок
нельзя избежать ошибочной классификации.
Следовательно, в этом случае целесообразно
повысить требования к проверке в ущерб
обучению путем увеличения объема
проверочной последовательности.
сильно
отличаются от действительных значений,
а пересечение этих подмножеств
незначительно, то для удовлетворительной
классификации следует увеличить точность
оценок увеличением объема обучающей
последовательности. При этом приходится
жертвовать точностью проверки в надежде
на то, что при правильной оценке параметров
классификация будет удовлетворительной.
Если же пересечение подмножеств велико,
то никаким повышением точности оценок
нельзя избежать ошибочной классификации.
Следовательно, в этом случае целесообразно
повысить требования к проверке в ущерб
обучению путем увеличения объема
проверочной последовательности.
Опираясь
на это предположение, ориентировочный
выбор коэффициентов
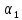 и
и
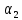 для
каждого класса в отдельности целесообразно
осуществлять согласно формуле
для
каждого класса в отдельности целесообразно
осуществлять согласно формуле
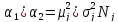 ,
(V.10)
,
(V.10)
где
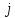 — номер класса (
— номер класса (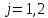 );
);
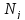 —
число изображений класса
—
число изображений класса
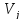 в
совокупности
в
совокупности
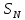 ;
;
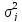 —
дисперсия класса
—
дисперсия класса
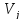 ,
определенная по совокупности
,
определенная по совокупности
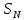 ;
;
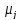 выбирается из соотношения
выбирается из соотношения
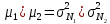 (
(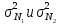 —
дисперсия
классов
—
дисперсия
классов
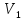 и
и
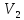 соответственно;
соответственно;
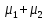 —
расстояние между средними значениями
классов). Задавшись определенным
значением
—
расстояние между средними значениями
классов). Задавшись определенным
значением
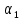 по формуле (V.9),
можно выбрать соответствующее
по формуле (V.9),
можно выбрать соответствующее
 ,
которое будет зависеть от статистических
свойств
,
которое будет зависеть от статистических
свойств
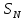 .
Если
классов больше двух, то
.
Если
классов больше двух, то
 можно определить для каждой пары классов.
Поскольку каждой паре классов соответствует
свое соотношение (V.10),
то
можно определить для каждой пары классов.
Поскольку каждой паре классов соответствует
свое соотношение (V.10),
то
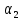 нужно
выбирать различным для каждой пары, а
из всех
нужно
выбирать различным для каждой пары, а
из всех
 ,
относящихся к одному и тому же классу,
нужно
выбирать наибольшее.
Когда уже определены
,
относящихся к одному и тому же классу,
нужно
выбирать наибольшее.
Когда уже определены
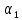 и
и
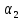 для каждого класса, нетрудно по формуле
(V.9)
определить соответствующие числа
для каждого класса, нетрудно по формуле
(V.9)
определить соответствующие числа
 .
Обучающая
последовательность составляется из
.
Обучающая
последовательность составляется из
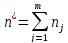 элементов, где
элементов, где
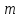 —
число классов.
—
число классов.