

Предложение group by.
Рассмотрение данного предложения тесно связано с определёнными стандартом SQL статистическими функциями. Их синтаксические диаграммы представлены на рис. 8.
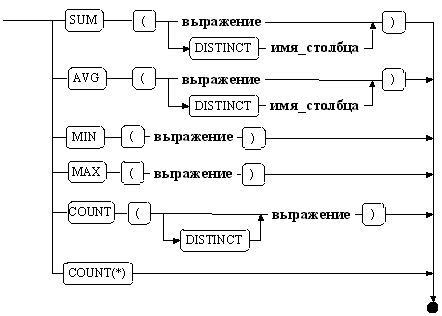
Рис. 8.
функция SUM() вычисляет сумму всех значений переданного в качестве аргумента выражения;
функция AVG() вычисляет среднее всех значений переданного в качестве аргумента выражения;
функция MIN() находит наименьшее из всех значений переданного в качестве аргумента выражения;
функция MAX() находит наибольшее из всех значений переданного в качестве аргумента выражения;
функция COUNT() подсчитывает количество значений, содержащихся в столбце;
функция COUNT(*) подсчитывает количество строк в таблице результатов запроса;
Аргументом статистической функции может быть простое имя столбца или допустимое в SQL выражение. Значения NULL статистическими функциями, согласно стандарту ANSI/ISO, обрабатываются согласно следующим правилам:
если какие-либо из значений, содержащихся в столбце, равны NULL, при вычислении результата функции они исключаются;
если все значения в столбце равны NULL, то функции SUM(), AVG(), MIN() и MAX() возвращают значение NULL; функция COUNT() возвращает ноль;
если в столбце нет значений (т.е. столбец пустой), то функции SUM(), AVG(), MIN() и MAX() возвращают значение NULL; функция COUNT() возвращает ноль;
функция COUNT(*) подсчитывает количество строк и не зависит от наличия или отсутствия в столбце значений NULL; если строк в таблице нет, эта функция возвращает ноль.
Если перед аргументом любой статистической функции (кроме COUNT(*), MIN() и MAX()) указать ключевое слово DISINCT, то повторяющиеся значения не будут учитываться при получении результатов.
Предложение GROUP BY «схлопывает» строки с одинаковыми значениями в перечисленных в нем колонках в одну. Т.е. каждое уникальное сочетание значений, перечисленных в предложении GROUP BY, образует группу, и отображается одной строкой. Все колонки, перечисленные после ключевого слова SELECT и не перечисленные в предложении GROUP BY, должны быть либо аргументами статистических функций или участвовать в вычислении аргумента для статистической функции, либо константами. Когда в столбце группировки содержится значение NULL, возникают дополнительные осложнения. В предложении WHERE при сравнении двух значений NULL результат имеет значение NULL, т.е. два значения NULL не считаются равными. Если такое соглашение применить в предложении GROUP BY, то это приведёт к тому, что каждая строка со значением NULL в столбце группировки будет помещена в отдельную группу, что очень неудобно. Поэтому в стандарте ANSI/ISO определено, что два значения NULL в предложении GROUP BY считаются равными.
Предложение having.
Так же как и предложение WHERE задаёт условия отбора строк запроса, предложение HAVING задаёт условия отбора для групп, созданных при помощи предложения GROUP BY. Если предложение GROUP BY отсутствует, то группой считается вся итоговая выборка (в отличие от предложения WHERE, в предложении HAVING можно и нужно использовать статистические функции). Условие отбора в предложении HAVING задаётся аналогично условию в предложении WHERE, но с некоторыми ограничениями. Так как предложение HAVING накладывает условие на группу записей, то и используемое в нём условие отбора применяется не к отдельным строкам, а к группе в целом. Это значит, что в последнее может входить только:
константа;
статистическая функция, возвращающая одно значение для всех строк, входящих в группу;
столбец, указанный в предложении GROUP BY;
выражение, включающее в себя один или несколько из вышеперечисленных элементов и никаких других.