

4.1. Декомпозиция без потерь
Один из методов избежать аномалии обновления в процессе нормализации – выполнение декомпозиции (разбиения) исходного отношения на меньшие отношения. Эту процедуру надо выполнить так, чтобы оба свойства декомпозиции были сохранены. Первое из них – это свойство обратимости, которое позволит восстановить любой кортеж исходного отношения, используя соответствующие кортежи меньших отношений. Второе – сохранение ограничения, наложенного на исходное отношение, посредством наложения определенных ограничений на каждое из меньших отношений. Иначе говоря, интерес представляет только та декомпозиция, которая выполняется без потери информации.
В качестве примера рассмотрим отношение Поставщики с атрибутами {Код, Статус,Город}. Выполним два варианта декомпозиции отношения Поставщики (Рис. 4.2.):
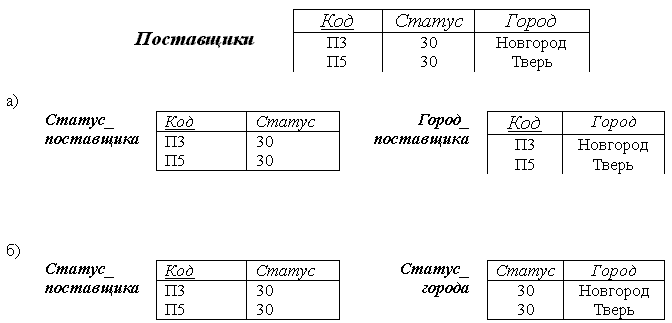
Рис. 4.2. Декомпозиции отношения Поставщики
1. В случае а) информация не утрачивается, поскольку Статус_поставщика и Город_поставщика содержат данные о том, что поставщик П3 имеет Статус 30 и находится в Новгороде. Соответственно и П5 имеет Статус 30 и находится в Твери.
2. В случае б) некоторая информация утрачивается, поскольку оба поставщика имеют Статус 30, но нельзя сказать в каком городе находится каждый из них, т.е. вторая декомпозиция не является декомпозицией без потерь.
Процесс декомпозиции на самом деле является операцией проекции, т.е. каждая из представленных на Рис. 4.2. переменных-отношений: Статус_поставщика, Город_поставщика и Статус_города -- в действительности являются проекциями отношения Поставщики.
Если операцией декомпозиции в процедуре нормализации является операция проекции, то обратной операцией должна быть операция соединения.
Пусть R1 и R2 проекции некоторого отношения R. Какие условия должны быть соблюдены, чтобы обратные соединения R1 и R2 гарантировали бы получение R?
Ответ на это вопрос даёт теорема Хеза.
Теорема Хеза: Пусть R{A, B, C} является отношением, где А, В и С атрибуты этого отношения. Если R удовлетворяет Ф3 А®В, то R равно соединению его проекции
{A, B} и {A,C}.
Обозначим А-Код, B-Статус, C-Город. Согласно теореме Хеза, отношение Поставщики можно разбить на проекции:
{Код, Статус} и {Код, Город} без утраты информации
и на проекции:
{Код, Статус} и {Статус, Город} с потерей информации.
4.2. Первая, вторая и третья нормальные формы.
Перейдем к процедуре нормализаций и дадим определение 1НФ.
Отношение находится в первой нормальной форме(1НФ ) тогда и только тогда, когда все используемые в нем домены содержат только скалярные значения.
Воспользуемся ранее рассмотренными таблицами: ПОСТАВЩИКИ, ТОВАР И ПОСТАВКИ (рис.1.4) – и на их базе составим одну таблицу , включающую основные поля этих таблиц.
Дадим этой таблице название: ПЕРВАЯ. Эта таблица будет содержать следующие поля:
ПЕРВАЯ {Код_поставщика, Статус, Город , Код_товара, Квота }
ПЕРВИЧНЫЙ КЛЮЧ {Код_поставщика, Код_товара }.
Введем дополнительные ограниченичения для данных таблицы ПЕРВАЯ в виде функциональной зависимости Город ® Статус, т. е. статус поставщика определяется местом его нахождения. Например, все поставщики из Новгорода должны иметь статус 10, а поставщики из Москвы – статус 20.
Все множество функциональных зависимостей для таблицы ПЕРВАЯ изображены в виде диаграммы, представленной на Рис. 4.3.
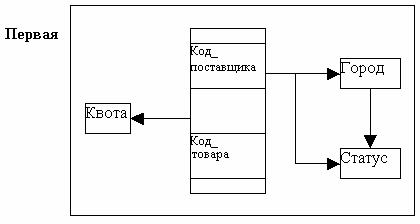
Рис. 4.3. Функциональные зависимости для таблицы Первая
Из этой диаграммы видно , что первичный ключ таблицы представляет собой комбинацию двух полей: {Код_поставщика, Код_товара }.
Кроме того, стрелки начинаются не только с первичных ключей, но и с неключевых атрибутов. Не все атрибуты неприводимо зависимы от первичного ключа. В частности, атрибуты Статус и Город, каждый в отдельности зависимы от Код_поставщика и не являются взаимно независимыми.
Для иллюстрации некоторых трудностей, порождаемых этими стрелками, рассмотрим таблицу ПЕРВАЯ, представленную на рис. 4.4.
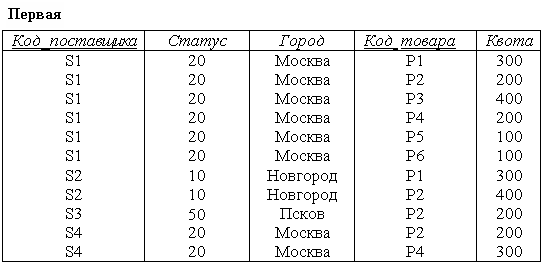
Рис. 4.4. Таблица данных Первая
В каждом кортеже с Код_поставщика S1 в атрибуте Город указано значение: Москва, а в каждом кортеже с значением Москва, в атрибуте Статус стоит число 20 и т. д.
При работе с таблицами, содержащими избыточные данные, могут возникнуть проблемы , которые называются аномалиями обновления . Эти аномалии подразделяются на аномалии вставки – INSERT, аномалии удаления – DELETE и аномалии модификации – UPDATE.
Для проверки таблицы ПЕРВАЯ подвергнем ее испытаниям при помощи перечисленных выше операций.
Операция INSERT:
В таблице ПЕРВАЯ не показан поставщик S5 из Твери, хотя в таблице ПОСТАВЩИК он присутствует. Дело в том, что до тех пор, пока он не произвел поставку товара, для него не задано значение первичного ключа, а резервирование кортежа со значением первичного ключа NULL правилами СУБД не поддерживается.
Операция DELETE:
Если в таблице ПЕРВАЯ удалить кортеж с значением Код_поставщика S3, то будет утрачена информация о поставщике и о том, что поставщик находился в Пскове.
В том и другом случае основная проблема заключается в том, что отношение Первая содержит информацию о товарах и о поставщиках. Удаление информации о поставщиках вызывает удаление информации о товарах и наоборот. Наша задача разделить информацию на несколько частей: информацию о товарах записать в одно отношение, а информацию о поставщиках — в другое.
Таким образом, процедуру нормализации можно охарактеризовать как процедуру разбиения логически не связанной информации по отдельным отношениям.
Операция UPDATE:
Название города для определённого поставщика повторяется несколько раз. Если при обновлении поставщик S1 переместится из Москвы в Тулу, то возникает проблема поиска в таблице Первая всех кортежей, в которых соединены S1 и значение "Москва".
Для решения выше перечисленных проблем, нужно произвести декомпозицию таблицы Первая и представить ее в виде следующих таблиц:
Вторая (Код_поставщика, Статус, Город) ;
Поставки (Код_поставщика, Код_товара, Квота).
Составим диаграмму ФЗ для этих таблиц:
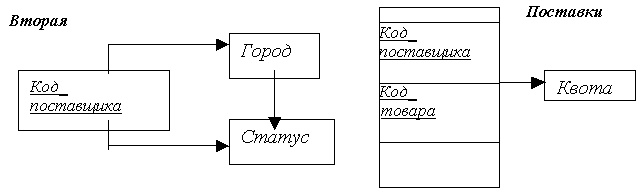
Рис. 4.5. Диаграмма ФЗ для таблиц Вторая и Поставки
Таблица данных для этих отношений примет вид:
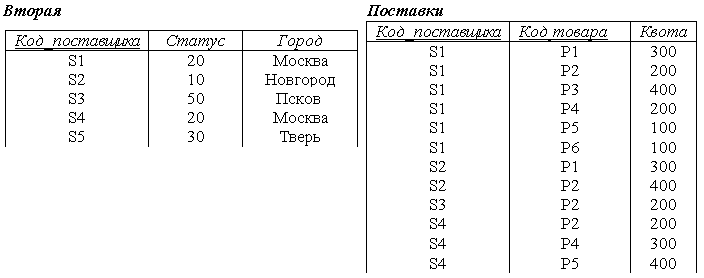
Рис. 4.6. Таблицы данных Вторая и Поставки
1. С помощью вставок (INSERT) в отношение Вторая можно включить информацию, что поставщик S5 находится в Твери, даже если к данному моменту поставку он не произвел.
2. Теперь можно удалить (DELETE) информацию о поставке, удаляя из отношения Поставки соответствующий кортеж S3 P2, при этом информация о том, что поставщик S3 находится в Пскове, не утрачивается.
3. В отношении Вторая название города для каждого поставщика появляется всего один раз. Иначе говоря, избыточность данных Код_поставщика ® Город устранена.
Благодаря этому в соответствующем кортеже отношение Вторая с лёгкостью можно заменить для поставщика S1, например, город Москва на Тулу.
Таким образом, разбиение отношения Первая на отношения Вторая и Поставки состоит в исключении зависимостей, которые не были неприводимыми.