

Сортировка последовательности Метод прямого слияния
Слияние означает объединение двух или или более в одну упорядоченную последовательность с помощью повтора выбора из доступный в данный момент элементов.

В)
а) 3 5 8 9
б)1 2 4 8
Выбираем меньший из ключей 1 и 3, берем его в список В. Затем в списке откуда забрали элемент переходим к следующему и сравниваем 2 и 3 min=2 в список В и в списке Б продвигаемся на следующий. Сравниваем 3 и 4 и продвигаем данные. При исчерпании исходных списков остаток из других без сравнений переходит в В.
Сначала формируем упорядоченные пары
1 и n/2 , 2 и (n/2)+1
Полученные пары объединить в тетрады(4 элемента), тетрады в восьмерки и т.д. ,пока не получим правильный вектор записи. Ее называют деревом слияний.



 3
5 6 9 4 4 1 7
3
5 6 9 4 4 1 7
3 5 6 9 14 4 7 j ярус 1 3 4 4 5 6 7 9
Процесс слияния имеет несколько вариантов:
Можно выполнять все слияния на одном ярусе => переходить на следующий
Упорядочив две пары записи сливаем их и получив две тетрады объединяем их не получив оставшихся
!!!Слияние всегда требует дополнительного массива
В примере: рекурсивное слияние использует авторов: Боуз, Непьсон.
Для получения правильного вектора надо слить начальную половины списков А и Б(1,2,35), зачем конечные(4889). Разделить второй подсписок после первого. Дополнительно выполнить слияние 2 половины первого, и 1 половины второго размещая результат в тех же позициях. Каждый из 3-х этапов слияния (L,R и ср) можно свести к 3-м этапам слияния вдвое меньших частей, пока по рекурсиям не придем к действию с ключами одиночками.
Sli для слияния двух частей
Voz: Boolean; если false сортируется по убыванию
Prcedure Bose (var x:array of integer; voz:Boolean = false)
m=1
, h=high(x)




j=0
j+m<=1
частей
m=m+m
m>h


 m - размер
частей
m - размер
частей
Sli(j,m,m)



end J=j+m+m

 +
+
j+r<=h
End sli



m>1

xj<xj+2



m=m
div 2
xjxj+2

Sli(i,r,m)


J+r+m<=h

+
Sli(i+m,r,m)





 -
-
Sli(i+m,r-m,m)
Организация динамических списков.
Память выделяется компилятором как введено под var. Можно объединить в массив группу элементов. Будет линейка байт.
Поиск растет динамически и сокращается. Элементы списка имеют поле информационное поле и поле ссылочное(по адресу переходит к следующему элементу).
Список – группа однотивных элементов связанные между собой ссылками (на следующий список или двумя на след и на предыдущ элемент). С каждым элементов необходимо сопоставить хотя бы одну ссылку указывающую на следущий элемент. Динамическое выделение памяти будем программировать явно и для выделения динамической памяти будем использовать
GetMen(p,sizeof(тип элемента списа)); (выделение памяти)
Getmep запишет адрес первого байта выделенного динамической памятью
New(p) Размер выделяемой памяти в байтах.
Выделяет динамическую память и ссылка p всегда типизированная, поэтому в типе по котому будет объявлена динамическая ссылка есть структура.
Под тайпом нужно организовать 2 вида. Ccылочный тип, и на что будет ссылаться. Рекорд содержит ключ следующего элемента.
Type
ptr=^Node;
Node=record
key:integer
next:Ptr;
end;
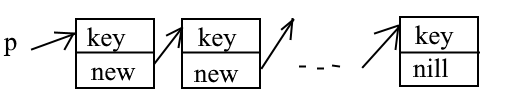
Nil 0000:0000 ссылка в ни куда
Freemem(p); освобождает память
Самая простая операция – включение элемента в начало списка
Var q,p:ptr
Разместим элемент типа node в динамической памяти
Begin
p:=nil;
For i:=0 to memo.lines.coumt-1 do begin
GetMem(q,sizeof(node)); ссылка на выделенную память присвоенной элементу q
Присваиваем новые значения
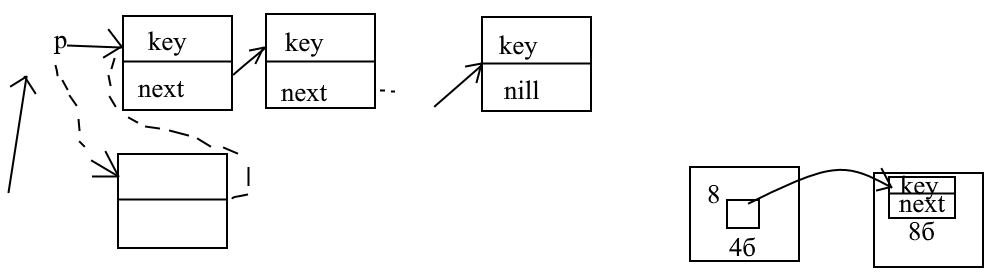
q^.key:=strtiont(memo.lines(i));
q^.next:=p; ^-операция разыменования, позволяет получать доступ к данным. (без нее на ссылается на адрес)
p:=q;
end;
p-> 3 2 1 ссылается на первый элемент.
Фактически фрагмент программы соответствует формированию динамического стека.
Если список пустой p то ссылка содержит nil
При извлечение элемента из стека получаем порядок обратный порядку включения элемента. Если это не устраивает, тогда элементы добавляем в конец списка. Чтобы каждый раз не искать хвостовой элемент, в этом случае организуют вторую ссылку указывающую на хвост(последний элемент) динамического списка.
Допустим включить в список после элемента списка.
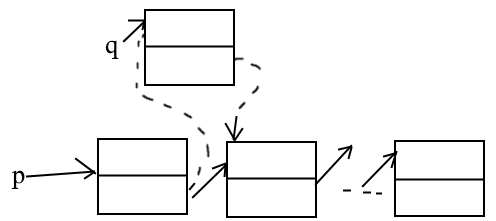
q^.Next:=p^next;
p^.next:=q;
Новые элемент p дублирует значение, а потом заносит в новую.
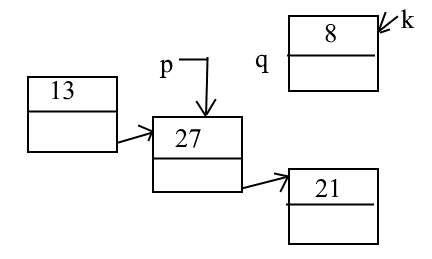
Исключение. Исключение элемента, следующего за p и включение исключенного элемента в голову другого списка.
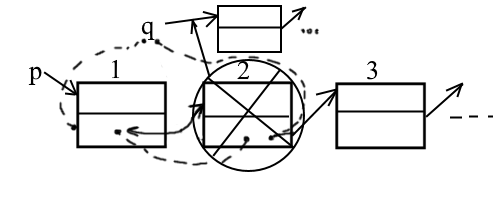
Var p,q,r:ptr;
begin
r:=p^.next
p^.next:=r^.next
r^.next:=q;
q:=r;
Список
не пуст? P=nil
?
Конец
обработки


 Например
с каждый элементом списка -
будет
выполнять операцию Q(x).
Например
с каждый элементом списка -
будет
выполнять операцию Q(x).
Q-выполнение
операции
 r:=p; +
r:=p; +
while (p<>Nil) and (p^.key<>x) do begin
Переход
к следующему элементу.

 Q(x);
Q(x);
p:=p^.next;
end;
p:=r
Задача состоит чтении текста, выборки из него слов и подсчете частоты появления. Называется алфавитный частотный словарь.
Решение: найдем список всех найденных слов в списке. Если слово обнаруживается, то его счетчик частоты увеличивается +1 если слова в списке нет, то оно туда включается. Предположим, что слова выделены из текста и закодированы целыми числами. Находятся входной последовательности.
 Procedure
Search(x(что
ищем):integer;
(сам
список будет параметром по ссылке т.к.
берем на выходе)
var
root:ptr);
Процедура
поиска
Procedure
Search(x(что
ищем):integer;
(сам
список будет параметром по ссылке т.к.
берем на выходе)
var
root:ptr);
Процедура
поиска
w=root

(w<>nil)
and (w^.key<>x)
key:integer; -



 Count:integer;
Count:integer;
next:ptr;
W:=w^.next
 Procedure
TForm1Button1.Click() +
Procedure
TForm1Button1.Click() +

 var
var
W=nil
W^.count:=w^.count

 assignfile(f,’..’);
assignfile(f,’..’);

 reset(f);
+
reset(f);
+
W=root
GetMem(root,sizeof(node)) root^.key:=x
root^.count:=1
root^next:=w
 while
not eof(f) do begin
while
not eof(f) do begin
realdn(f,a);
end
end;