

Введение
Программа представляет собой конкретные, основанные на некотором реальном представлении и строении данных воплощения абстрактных алгоритмов. Будем опираться на теории Хоара – о структурных организационных данных. Воплощение этой теории на языке Паскаль.
Суть теории Хоара:
Данные прежде всего представляют абстракции реальных объектов и рассматривают их как абстрактные образования со структурами не обязательно предусматривать в общепринятых языках программирования. В процессе программирования программы структура программы согласуются с программой ограничивается в процессе программы.
Фундаментальные структуры данных:
Запись, массив, множества – элементы структуры данных.
К ним предоставляются требования: Должны легко реализовываться; блоки должны соответствовать математическим понятиям, отображающих заложенные идеи алгоритма.
Основные понятия структур данных.
Абстрагирование.
Значительный объем информации, подлежащий обработке представляет абстракцию некоторого фрагмента реального мира.
В общем случае абстрагирование – это упрощение факторов. При решении конкретной задачи выбирают уровень абстрагирования. Т.е. определяют множества данных предоставляющую реальную ситуацию. Затем выбирают способ предоставления этой информации. При выборе необходимо учитывать возможность этой системы и системы программы. Необходимо учитывать операции которые нужно выполнить.
Другой уровень абстрагирования. Абстрагирование от конкретных устройств.
Этот уровень автоматически дает язык программирования. Язык программирование предоставляет множества основных абстракций общих для большинства задач обработки данных.
Концепция типов данных – в обработке данных классификация типов играет такую-же роль, что и математике.
Основной принцип классификации – любая константа, переменная, выражение, функция относится к определенному типу.
Любой тип определяет множества значение, который может принимать переменная или выражение, которому может относиться константа и которая может формировать операцией или функцией.
Тип любой величины может быть выведен по ее виду или описанию
Каждая операция или функция требует аргументов определенного типа.
Паскаль предоставляет методы определения типа данных. Новый тип определяется на базе ранее определенных.
Мощность типа Т – число различных значащих, входящих в тип Т. Мощность задает размер данных необходимого для размещения типа Т.
Тип определяет размер значений и способ кодировании. На базе любого типа можно построить иерархическую структуру. Конечные элементы должны быть атомарны (непрерывны).
Любой язык программы располагается несколькими методами, определенными базами структур. Объединение может быть статическим или динамическим. Для каждого базового простого типа предопределено множество операций. Основные операции – сравнение и присваивание (x=y, x:=y). Для сложных структур эти простые операции приводят к непростым вычислениям. Для стандартных простых типов в языке определенных операции позволяют получить новые значения.
Фундаментальные структуры данных
Проблема представления данных заключается в отображении абстрактных структур на память машины.
Пусть память – это массив отдельных ячеек, называемый словами, индексы этих слов назовем адресам.
 var
store:array
address of word;
var
store:array
address of word;
Мощность типов addres и word в зависимости от машины может изменяться.
Представление массивов всегда заключается в отображении абстракций массива с компонентами типа Т на память с компонентами типа word. Массив следует отображать так, чтобы все вычисление адреса по компонентам было проще. Адрес i для j компонента массива
i=i0+j*s i0 – адрес компоненты s – число слов, занимаемый одной компонентой. Желательно чтобы s было целым. Если s не целое, то его округляют до ближайшего верного целого. Тогда каждая компонента будет занимать столько слов. Процесс округления называется выравниванием данных. Коэффициенты использования памяти – частное от деление на минимальные размеры памяти на фактически использованные. Цель любого реализатора устремить U к 1
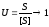
Выравнивание во всех трансляторах используется всегда.
S>0.5 S≤0.5 U>0.5 U(коэф) можно значительно увеличить, если в каждое слово указывать более одной компоненты массива. Этот процесс называется упаковка. При упаковке слова n компонент.

Доступ к i компоненте определяется следующем вычислением:
i=i div n+1 k:=i mod n
пр. Пусть упаковка по 6 компонентов в слове для массива А содержит 30 элементов. Вычислить адрес 26. i=26 n=6 j=26 div 6+1=5 k=26 mod 6=2
Ответ: В 5ом слове на 2ом месте
Представление записей
Запись отображает в памяти вычислительной машины простым объединением отображений их компонентов. Адрес компоненты ri относительно начальные записи r, называется смещением Ki
Ki=S1+S2+…Si-1
Si – это размер i поля
Упаковка выгодна, когда в одно слово памяти можно уложить несколько полей.
Т.к.
транслятор может вычислять смещение
=> может определить смещение полей
внутри слова.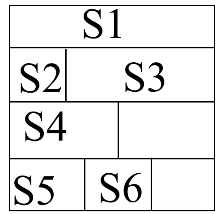
На многих архит. записей на много эффективней, нежели чем на массиве.
Представление множества
Множества S удобно представить в памяти машины с помощью битового вектора или характеристической функцией.
Этот массив логически значим, причем i-я составляющая указывает, что i присутствует в множестве S.
c(s)=i in S
Например:
 var
S:set
of [1..10]
begin
S:=[]
S:=S+[1];
S:=S-[1];
S:=S+[2,3,4,5];
var
S:set
of [1..10]
begin
S:=[]
S:=S+[1];
S:=S-[1];
S:=S+[2,3,4,5];