

2
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
отчет
по лабораторной работе №2
дисциплина - «Моделирование систем»
Тема: «Анализ методов кластеризации в Orange»
|
Студент гр. 5371 |
|
Уруков С.Д. |
|
Преподаватель |
|
Туральчук К.А. |
Санкт-Петербург
2017
Лабораторная работа по классификации состоит из двух частей. В первой части данные берутся из датасета по болезни почек с одним классом и 25 атрибутами. Во второй – из графического представления.
Часть 1
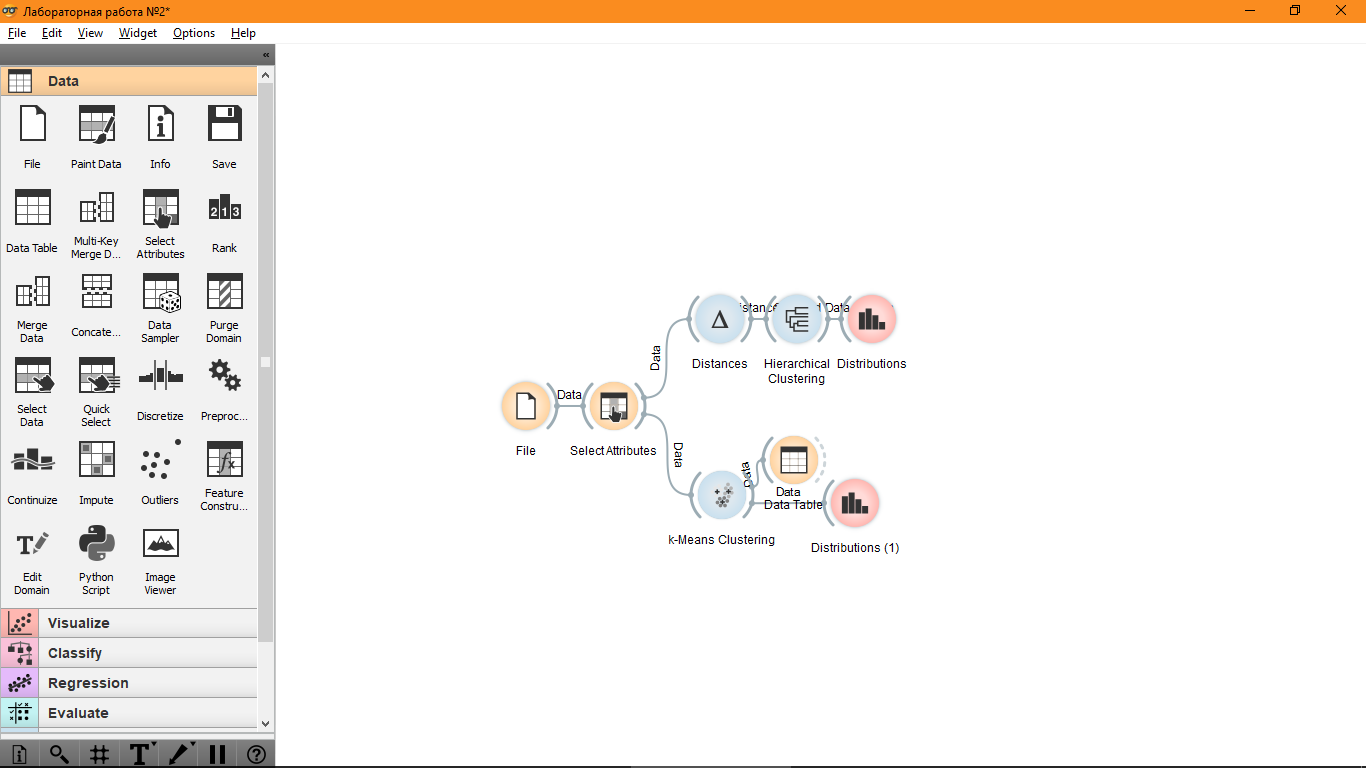
Используются два метода k-means и Hierarchial Clustering.
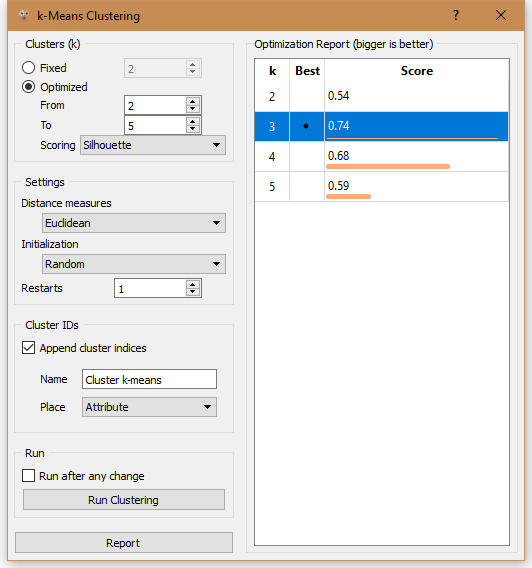
С методом k-means самым оптимальным количеством кластеров выбирается 4 (при выборе от 2 до 5).
Но для этого набора данных распределение получилось только по двум классам, а остальные два класса не использовались.
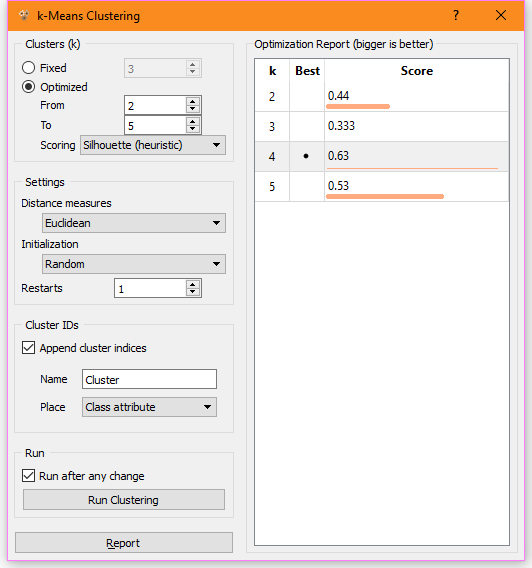
Поэтому был выбран другой метод оценки Silhouette вместо Silhouette (heuristic). Здесь наиболее оптимальным количеством кластеров является два.
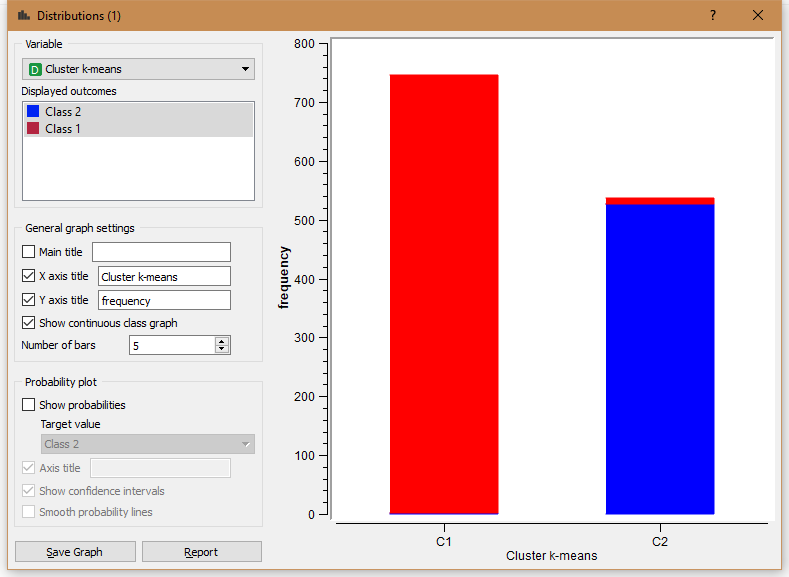
После построена гистограмма. Точками отмечены вероятности для кластеров, отрезки – доверительные интервалы.

Если вручную задавать количество кластеров фиксированным значением, то будет видно, что один из кластеров доминирует над остальными. На этом изображении 3 кластера.

Дальше исследовался метод Hierarchical Clustering. Алгоритмы упорядочивания данных указанного типа исходят из того, что некое множество объектов характеризуется определённой степенью связности. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы, в свою очередь, подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
По выбранным параметрам наблюдаю следующую картину:
Distance Metric = Euclidean


Часть 2
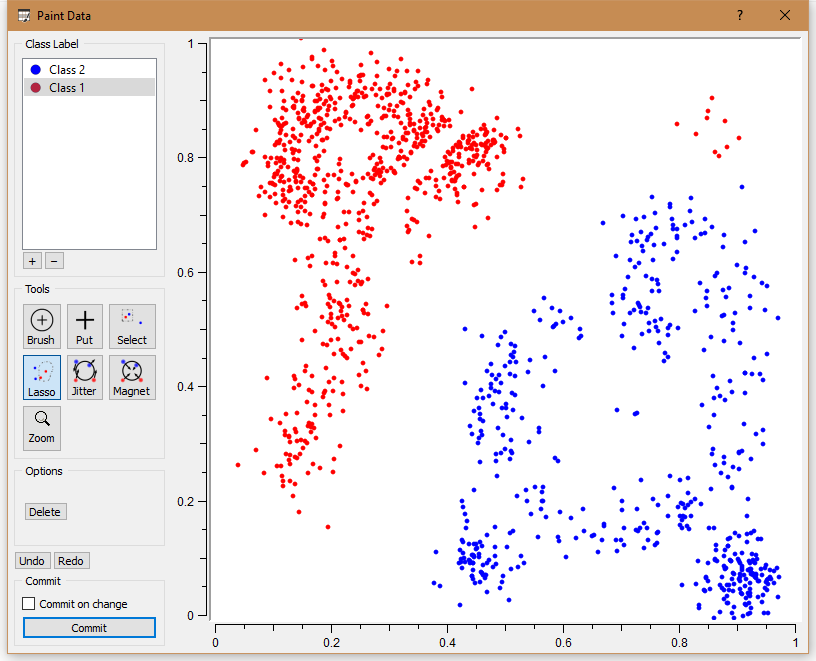
Данные для задачи рисуются через встроенный графический редактор. Кластеризация k-means наиболее оптимальна для двух.
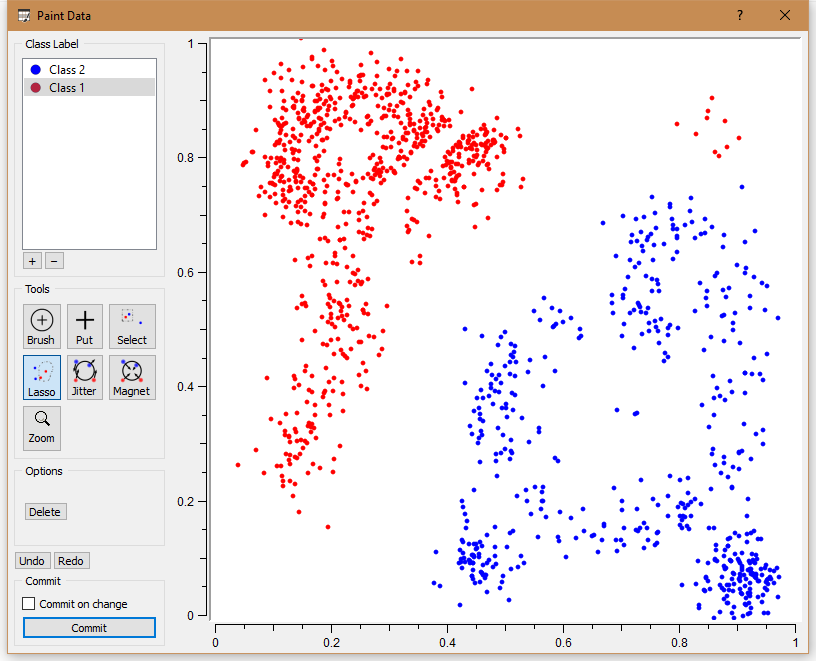
Наблюдается небольшая ошибка из-за того, что на графическом представлении несколько точек расположены нехарактерно для большинства.

Теперь с 3 классами. Для более быстрых вычислений было взято немного данных.
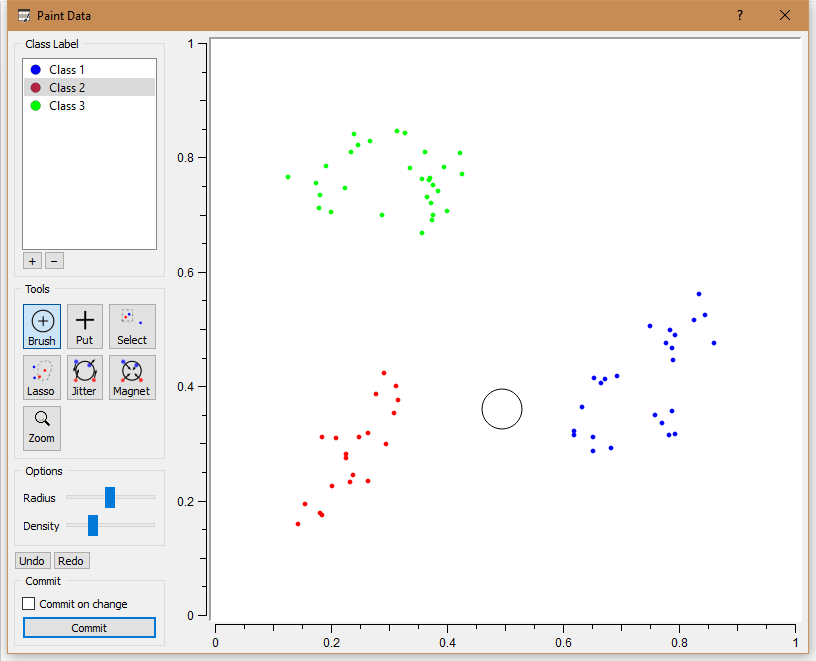
Метод k-means по методу оценки Silhouette выбирает 3 класса и со 100% точностью кластеризует точки так, как это и рисовалось.
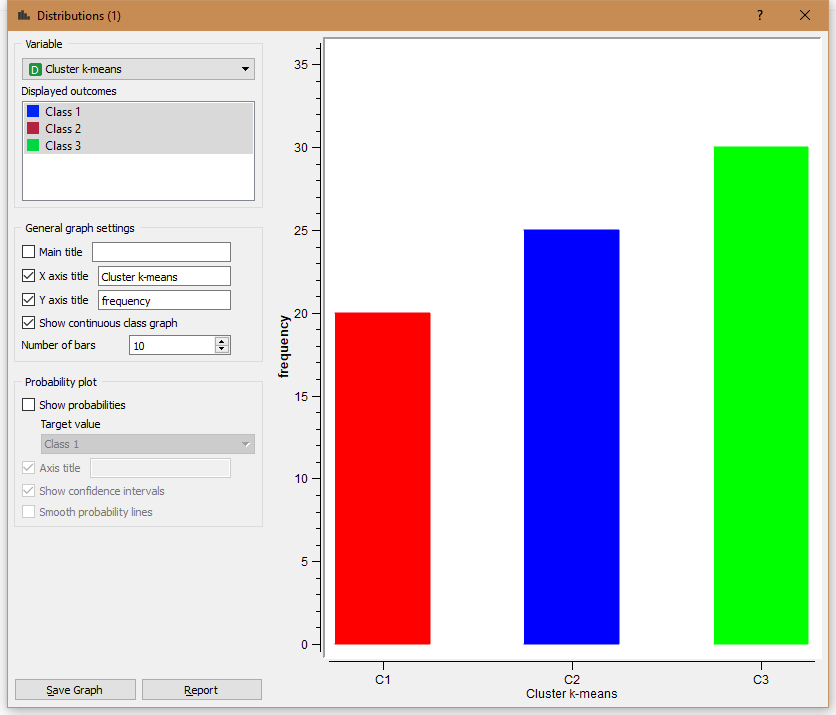
Далее был использован метод Hierarchial Clustering. Алгоритм сработал таким образом, что объекты поделились на два класса. Возможно, что это объясняется небольшим количеством данных, потому что после этого я увеличил количество точек на рисунке и метод сработал довольно точно.
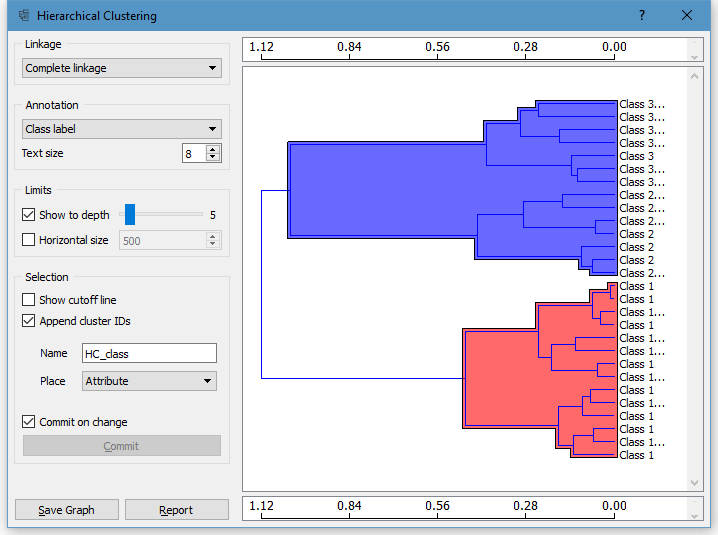
Вывод:
В ходе работы были исследованы два метода кластеризации k-means и Hierarchial Clustering. Разные подходы к кластеризации приводили к разным результатам.
The algorithm begins by creating k centroids. It then iterates between an assign step (where each sample is assigned to its closest centroid) and an update step (where each centroid is updated to become the mean of all the samples that are assigned to it. This iteration continues until some stopping criteria is met; for example, if no sample is re-assigned to a different centroid.
Agglomerative hierarchical clustering, instead, builds clusters incrementally, producing a dendogram. The algorithm begins by assigning each sample to its own cluster (top level). At each step, the two clusters that are the most similar are merged; the algorithm continues until all of the clusters have been merged. Unlike k-means, you don't need to specify a k parameter: once the dendogram has been produced, you can navigate the layers of the tree to see which number of clusters makes the most sense to your particular application.