

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Укажем основные факторы, влияющие на физическую организацию данных для конкретных БД:
1.произвольная или последовательная обработка данных. Для определения вида обработки используют коэффициент активности файла (k)
k=z1/z ,
где z1 – число записей, считанных за 1 прогон; z - число записей, просмотренных за 1 прогон.
Если k высок, то используют последовательную обработку, например при расчете заработной платы;
3.частота обращения к определенным записям;
4.время ответа (важно для систем реального времени);
5.способность к расширению (особенно, если добавляется записей больше, чем уничтожается);
6.возможность организации поиска по нескольким ключам.
21

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Способы поиска записей
1.Последовательное сканирование файла с проверкой ключа каждой записи. Такой метод используется, если выбран последовательный метод обработки данных или используется файл последовательного доступа. Требует много времени.
2.Блочный поиск. Если записи упорядочены по ключу, то при сканировании не требуется чтение каждой записи. Считывается первая запись блока и ее ключ сравнивается с ключом искомой записи. А далее или просматриваются все записи данного блока или выбирается первая запись следующего блока.
3.Преобразование ключа в адрес - самая быстрая организация поиска. Сейчас применяется технология хэширования – технология быстрого доступа к хранимой записи на основе вычисления специальной функции от заданного значения некоторого поля. Это значение и является адресом для записи.
4.Поиск по индексу. Первичный индекс – индекс, использующий в качестве входной информации первичный ключ. В индексном файле запись состоит из индекса и указателя. Сначала проводится поиск в индексе, а потом по указателю обращаемся к основному файлу с записями. Эффективно, быстро, но требуется память для хранения индекса.
5.Бинарный (двоичный) поиск для записей, упорядоченных по индексу.
6.Поиск по В-дереву для записей, упорядоченных по индексу.
22
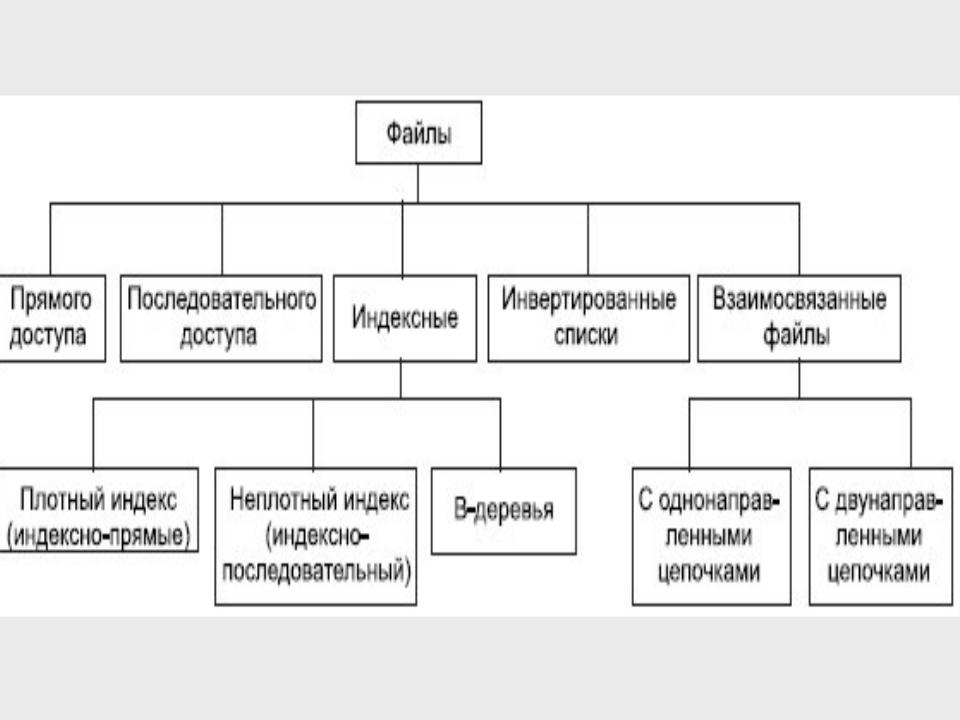
Классификация файлов, используемых в системах баз данных
23

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла.
В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с
последовательной адресацией (магнитофоны, стримеры).
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Для файлов с постоянной длиной записи адрес размещения записи с номером K может быть вычислен по формуле:
ВА + (К- 1) * LZ + 1,
где ВА — базовый адрес, LZ — длина записи.
24

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
1.Конец записи отличается специальным маркером.
2.В начале каждой записи записывается ее длина.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ = F(K),
где NZ — номер записи, K — значение ключа, F( ) — функция.
Когда не удается построить взаимно-однозначную функцию, либо эта функция будет иметь множество незадействованных значений, которые соответствуют недопустимым значениям ключа применяют различные методы хэширования (рандомизации) и создают специальные хэш- функции.
25

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Суть методов хэширования состоит в том, что берутся
значения ключа ( или некоторые его характеристики) и
используются для начала поиска, то есть вычисляется
некоторая хэш-функция h(k) и полученное значение
берется в качестве адреса начала поиска.
Допускается, что нескольким разным ключам может
соответствовать одно значение хэш-функции (то есть один адрес). Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хэш-функции, называются синонимами.
Поэтому при использовании хэширования как метода доступа необходимо принять два независимых решения:
выбрать хэш-функцию;
выбрать метод разрешения коллизий.
26

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Индексирование данных
Для ускорения доступа к записям по ключевому атрибуту (или группе атрибутов) создаётся специальная структура – индекс, который определяет соответствие значения атрибута (группы атрибутов) и местоположение записи.
Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс.
Сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным
индексом.
27

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Файлы с плотным индексом, или индексно-прямые файлы
Рассмотрим файлы с плотным индексом. В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в них имеет следующий вид:
Значение ключа Номер записи
Здесь значение ключа — это значение первичного ключа, а номер записи
— это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
28

ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
Длина доступа к произвольной записи оценивается не в абсолютных значениях, а в количестве обращений к устройству внешней памяти, которым обычно является диск. Именно обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в оперативной памяти.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является логарифмический, или бинарный, поиск. Максимальное количество шагов поиска определяется двоичным логарифмом от общего числа элементов в искомом пространстве поиска:
Tn = log2N,
где N — число элементов.
При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения)
29
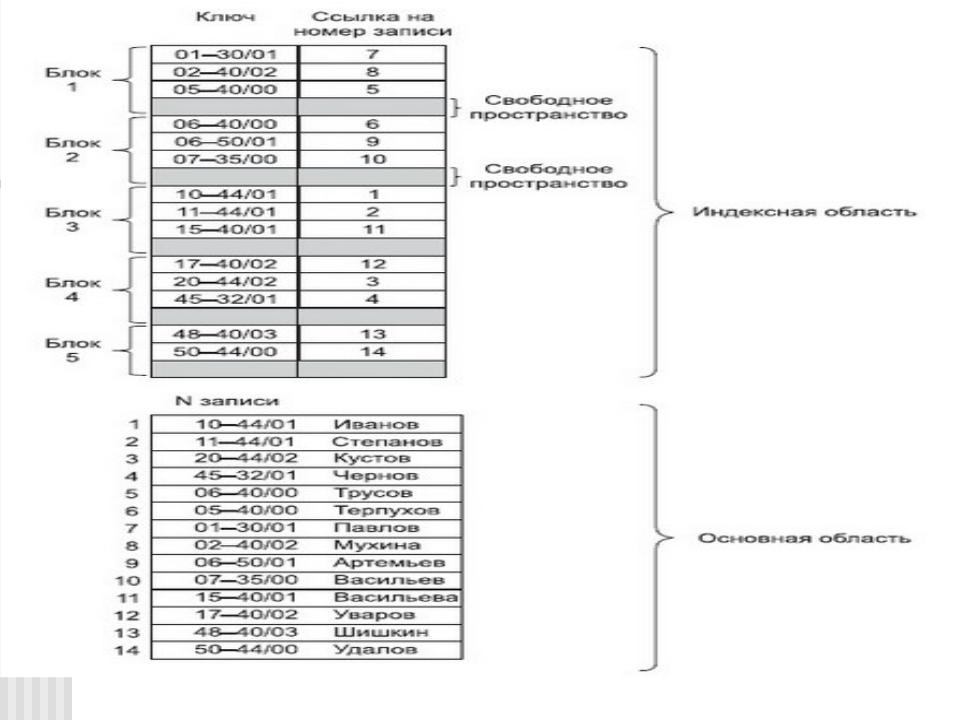
Пример организации файла с плотным индексом |
30 |