

База данных (БД) — совокупность определенным образом организованной информации на какую-то тему (в рамках некоторой предметной области).
Например:
база данных книжного фонда библиотеки;
база данных кадрового состава учреждения;
база данных законодательных актов в области уголовного права;
база данных современной эстрадной песни.
Конечно, вся эта информация может храниться и на бумаге (например, книжный каталог библиотеки). Но современным средством хранения и обработки баз данных является, безусловно, компьютер. В дальнейшем мы будем иметь в виду только компьютерные БД.
Базы данных бывают фактографическими и документальными.
В фактографических БД содержатся краткие сведения об описываемых объектах, представленные в строго определенном формате. Из приведенных выше примеров две первые БД скорее всего будут организованы как фактографические. В БД библиотеки о каждой книге хранятся библиографические сведения: год издания, автор, название и пр. Разумеется текст книги в ней содержаться не будет. В БД отдела кадров учреждения хранятся анкетные данные сотрудников: фамилия, имя, отчество; год и место рождения.
Базы данных в третьем и четвертом примерах наверняка будут организованы как документальные. Первая из них будет включать в себя тексты законов; вторая — тексты и ноты песен; биографическую и творческую справочную информацию о композиторах, поэтах, исполнителях; звуковые записи и видеоклипы. Следовательно, документальная БД содержит обширную информацию самого разного типа: текстовую, графическую, звуковую, мультимедийную.
Современные информационные технологии постепенно стирают границу между фактографическими и документальными БД. Существуют средства, позволяющие легко подключать любой документ (текстовый, графический, звуковой) к фактографической базе данных.
Сама по себе база данных не может обслужить запросы пользователя на поиск и обработку информации. БД — это только «информационный склад». Обслуживание пользователя осуществляет информационная система.
Информационная система — это совокупность базы данных и всего комплекса аппаратно-программных средств для ее хранения, изменения и поиска информации, для взаимодействия с пользователем.
Примерами информационных систем являются системы продажи билетов на пассажирские поезда и самолеты. WWW — это тоже пример глобальной информационной системы.
Далее будет идти речь будет только о фактографических базах данных. Дадим более строгое определение компьютерной БД, чем то, что приводилось выше.
База данных — организованная совокупность данных, предназначенная для длительного хранения во внешней памяти ЭВМ и постоянного применения. Для хранения БД может использоваться как один компьютер, так и множество взаимосвязанных компьютеров.
Если различные части одной базы данных хранятся на множестве компьютеров, объединенных между собой сетью, то такая БД называется распределенной базой данных.
|
|
|
Очевидно, информацию в Internet, объединенную паутиной WWW, можно рассматривать как распределенную базу данных. Распределенные БД создаются также и в локальных сетях.
Модель данных строится по принципу взаимосвязанных таблиц - реляционной.
Один тип объекта является главным, все нижележащие – подчиненными - иерархической.
Любой тип данных одновременно может быть главным и подчиненным - сетевой.
Реляционные базы данных
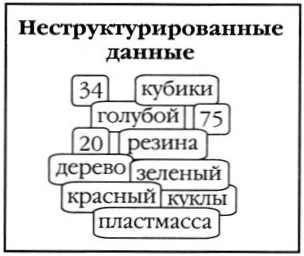
Информация в базах данных может быть организована по разному. Чаще всего используется табличный способ.
Базы данных с табличной формой организации называются реляционными БД.
В чем же их преимущество?
Главное достоинство таблиц — в их понятности. С табличной информацией мы имеем дело практически каждый день. Загляните, например в свой дневник: расписание занятий там представлено в виде таблицы, ведомость с оценками за четверти имеет табличный вид. Когда мы приходим на вокзал, смотрим расписание электричек. Какой вид оно имеет? Это таблица! А еще есть таблица футбольного чемпионата. И журнал учителя, куда он ставит вам оценки — тоже таблица.
Видите, как много примеров, и их еще можно продолжить. Мы настолько привыкли к таблицам, что обычно не требуется никому объяснять, как ими пользоваться. Ну разве что маленькому ребенку, который только учится читать.
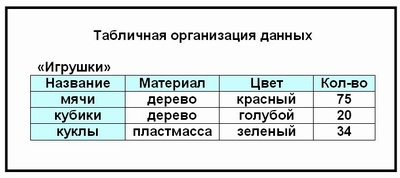
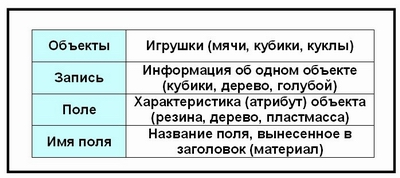
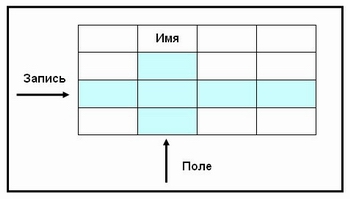
В реляционных БД строка таблицы называется записью, а столбец — полем. В общем виде это выглядит так:
Каждое поле таблицы имеет имя. Например, в таблице «Игрушки» имена полей такие: НАЗВАНИЕ, МАТЕРИАЛ, ЦВЕТ, КОЛИЧЕСТВО.
Одна запись содержит информацию об одном объекте той реальной системы, модель которой представлена в таблице.
Например, одна запись о каком либо объекте — это информация об одной игрушке.
Поля — это различные характеристики (иногда говорят — атрибуты) объекта. Значения полей в одной строчке относятся к одному объекту. Разные поля отличаются именами. А чем отличаются друг от друга разные записи? Записи различаются значениями ключей.
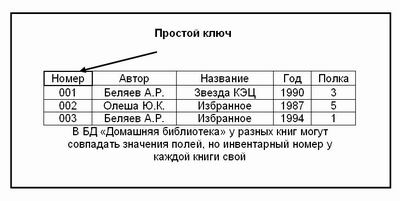
Главным ключом в базах данных называют поле (или совокупность полей), значение которого не повторяется у разных записей.
В БД «Домашняя библиотека» разные книги могут иметь одного автора, могут совпадать названия книг, год издания, полка. Но инвентарный номер у каждой книги свой (поле НОМЕР). Он-то и является главным ключом для записей в этой базе данных.
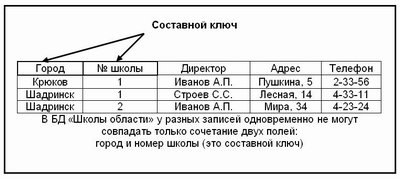
Не всегда удается определить одно поле в качестве ключа. Вот, например, база данных, которая хранится в компьютере управления образования области. В ней содержатся сведения о всех средних школах районных центров в виде такой таблицы:
В такой таблице у разных записей не могут совпасть только одновременно два поля ГОРОД и НОМЕР ШКОЛЫ. Эти два поля вместе образуют составной ключ: ГОРОД-НОМЕР ШКОЛЫ. Составной ключ может состоять и более чем из двух полей.
С каждым полем связано еще одно очень важное свойство — тип поля.
Тип определяет множество значений, которые может принимать данное поле в различных записях.
|
|
|
В реляционных базах данных используются четыре основных типа полей:
числовой;
символьный;
дата;
логический.
Числовой тип имеют поля, значения которых могут быть только числами. Например, в БД «Погода» три поля числового типа: ТЕМПЕРАТУРА, ДАВЛЕНИЕ, ВЛАЖНОСТЬ.
Символьный тип имеют поля, в которых будут храниться символьные последовательности (слова, тексты, коды и т.п.). Примерами символьных полей являются поля АВТОР и НАЗВАНИЕ в БД «Домашняя библиотека»; поле ТЕЛЕФОН в БД «Школы».
Тип «дата» имеют поля, содержащие календарные даты в форме «день/месяц/год» (в некоторых случаях используется американская форма: месяц/день/год). Тип «дата» имеет поле ДЕНЬ в БД «Погода».
Логический тип соответствует полю, которое может принимать всего два значения: «да» — «нет» или «истина» — «ложь» или (по-английски) «true» — «false». Если двоичную матрицу представить в виде реляционной БД (табл. 6.4, 6.5), то ее полям, принимающим значения «О» или «1», удобно поставить в соответствие логический тип. При этом «1» заменится на значение «истина», «О» — на значение «ложь».
Итак, значения полей — это некоторые величины определенных типов.
От типа величины зависят те действия, которые можно с ней производить.
Например, с числовыми величинами можно выполнять арифметические операции, а с символьными и логическими — нельзя.
Для взаимодействия пользователя с базами данных используют системы управления данными (СУБД).
Принципы построения систем управления баз данных следуют из требований, которым должна удовлетворять организация баз данных:
Производительность и готовность. Запросы от пользователя базой данных удовлетворяются с такой скоростью, которая требуется для использования данных. Пользователь быстро получает данные всякий раз, когда они ему необходимы.
Минимальные затраты. Низкая стоимость хранения и использования данных, минимизация затрат на внесение изменений.
Простота и легкость использования. Пользователи могут легко узнать и понять, какие данные имеются в их распоряжении. Доступ к данным должен быть простым, исключающим возможные ошибки со стороны пользователя.
Простота внесения изменений. База данных может увеличиваться и изменяться без нарушения имеющихся способов использования данных.
Возможность поиска. Пользователь базы данных может обращаться с самыми различными запросами по поводу хранимых в ней данных. Для реализации этого служит так называемый язык запросов.
Целостность. Современные базы данных могут содержать данные, используемые многими пользователями. Очень важно, чтобы в процессе работы элементы данных и связи между ними не нарушались. Кроме того, аппаратные ошибки и различного рода случайные сбои не должны приводить к необратимым потерям данных. Значит, система управления данными должна содержать механизм восстановления данных.
Безопасность и секретность. Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это права, от неавторизированной модификации (изменения) данных или их разрушения. Секретность определяется как право отдельных лиц или организаций решать, когда, как какое количество информации может быть передано другим лицам или организациям.
Одно из самых важных преимуществ современных СУБД состоит в логической и физической независимости данных. Например, база данных, реализованная в СУБД DBASE, физически содержит, как минимум, три файла. В то же время эту же базу данных можно перенести в СУБД Microsoft Access, где она физически разместится в одном файле. При этом логическая организация данных не изменится.
Развитие аппаратного и программного обеспечения, средств телекоммуникаций привело к тому, что на сегодняшний день наметился переход от традиционных баз данных, хранящих числа и символы объектно-реляционным базам данных, где каждая запись может содержать данные со сложным поведением. Пример тому развитие internet-технологий. Современный настольные компьютеры и программы просмотра Web - браузеры - позволяют осуществлять поиск в глобальной сети и просматривать большую часть мультимедийных данных.
Далее на примере одной из самых распространенных систем управления базами данных - Microsoft Access входит в состав популярного пакета Microsoft Office - мы познакомимся с основными типами данных, способами создания баз данных и с приемами работы с базами данных.
Существует огромное количество СУБД, например: Lotus Approach, Visual FoxPro, Borland Paradox, Borland dBase.
Лекция №2
2. Модели организации данных
В иерархической модели объекты-сущности и отношения предметной области представляются наборами данных, которые имеют древовидную (иерархическую) структуру. Иерархическая модель данных была исторически первой. На ее основе в конце 60-х — начале 70-х годов были разработаны первые профессиональные СУБД.
Пример структуры иерархической БД приведен на рис. 5.1.
Основное внимание в ограничениях целостности в иерархической модели уделяется целостности ссылок между предками и потомками с учетом основного правила: никакой потомок не может существовать без родителя.
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков.
Достоинством сетевой мидели данных является возможность ее эффективной реализации. В сравнении с иерархической моделью сетевая модель предоставляет бульшие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность ее понимания обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей из-за допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике.
Реляционная модель данных предложена сотрудником фирмы IВМ Эдгаром Коддом и основывается на понятии отношения (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является двумерная таблица.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта, информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
3. Реляционные базы данных
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Термины РМД представлены в табл. 5.1
Таблица 5.1 Термины реляционной модели
Термин реляционной модели Эквивалентный термин
Отношение Таблица
Схема отношения Строка заголовков столбцов таблицы (заголовок таблицы)
Кортеж Строка таблицы, запись
Сущность Описание свойств объекта
Атрибут Столбец, поле
Домен Множество допустимых значений атрибута
Первичный ключ Уникальный идентификатор
Кардинальность Количество строк
Степень Количество столбцов
Реляционная база данных представляет собой хранилище данных, содержащее набор двухмерных таблиц. Данные в таблицах должны удовлетворять следующим принципам.
1. Значения атрибутов должны быть атомарными (иными словами,
каждое значение, содержащееся на пересечении строки и колонки,
должно быть не расчленяемым на несколько значений).
2. Значения каждого атрибута должны принадлежать к одному и тому же типу.
3. Каждая запись в таблице уникальна.
4. Каждое поле имеет уникальное имя.
5. Последовательность полей и записей в таблице не существенна.
Отношение является важнейшим понятием и представляет собой
двумерную таблицу, содержащую некоторые данные.
Сущность есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении.
Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы.
Ключом отношения называется совокупность его атрибутов, однозначно идентифицирующих каждый из кортежей отношения. Иными словами, множество атрибутов К, являющееся ключом отношения, обладает свойством уникальности. Следующее свойство ключа — неизбыточность. То есть никакое из собственных подмножеств множества К не обладает свойством уникальности.
Каждое отношение всегда имеет комбинацию атрибутов, которая может служить ключом. Ее существование гарантируется принципом № 3 РМД. По крайней мере, вся совокупность атрибутов обладает свойством уникальности.
Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи отношения. Все эти комбинации атрибутов являются возможными ключами отношения. Любой из возможных ключей может быть выбран как первичный.
Ключи обычно используют для достижения следующих целей:
» исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются);
» упорядочения кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним — возрастание, а по другим — убывание);
» организации связывания таблиц.
Важным является понятие внешнего ключа. Внешний ключ можно определить как множество атрибутов одного отношения R2, значения которых должны совпадать со значениями возможного ключа другого отношения R1.
Атрибуты отношения К2, составляющие внешний ключ, не являются ключевыми для данного отношения.
С помощью внешних ключей устанавливаются связи между отношениями.
Ограничения целостности реляционной модели можно разделить на две группы — ограничения целостности сущностей и ограничения целостности ссылок.
Ограничения целостности сущностей заключаются в требовании уникальности кортежей отношения (записей таблицы). Отсюда вытекают следующие ограничения:
» отсутствие кортежей-дубликатов (данное требование предъявляется лишь к атрибутам первичных ключей);
» отсутствие атрибутов с множественным характером значений.
Ограничения целостности ссылок заключаются в том, что для любой записи с конкретным значением внешнего ключа должна обязательно существовать запись связанной таблицы-отношения с соответствующим значением первичного ключа.
К отношениям можно применять систему операций, позволяющую получать одни отношения из других. Например, результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся отношений. Поэтому можно разделить обрабатываемые данные на хранимую и вычисляемую части.
Основной единицей обработки данных в реляционных БД является отношение, а не отдельные его кортежи (записи).
Отсутствие упорядоченности записей в таблицах усложняет поиск. На практике с целью быстрого нахождения нужной записи вводят индексирование полей (обычно ключевых). Создание индексных массивов заключается в построении дополнительной упорядоченной информационной структуры для быстрого доступа к записям.
Как для самих таблиц, так и для индексных массивов применяются линейные и нелинейные структуры. В качестве линейных структур индексных массивов в большинстве случаев выступают инвертированные списки. Инвертированный список строится по схеме таблицы с двумя колонками — «Значение индексируемого поля» и «Номера строк» рисунок.
Значение индексируемого поля («год рождения») Номера строк
1970 3
1971 5,17,123,256
1972 31,32,77
1973 11,45,58, 167,231
1974 7,8,9, 10,234,235,236
Рис. Пример инвертированного списка
Инвертированные списки чаще всего применяются для индексации полей, значения которых в разных записях могут повторяться. В этом случае количество ситуаций, при которых требуется добавление или удаление строк индекса, невелико и затраты на переупорядочение индекса при изменениях данных в базовой таблице незначительны.
Строки инвертированного списка упорядочиваются по значению индексируемого поля. Для доступа к нужной записи исходной таблицы сначала в упорядоченном инвертированном списке отыскивается строка с требуемым значением поля, затем считываются номера соответствующих записей основной таблицы, к которым осуществляется доступ по этим номерам.
Нелинейные структуры индексов применяются для создания индексных массивов ключевых полей или тех полей, значения по которым не повторяются. При организации индексов в таких случаях чаще всего используются древовидные иерархические структуры в виде В-деревьев.