

Приклади виконання розбору пропозицій вхідної мови
Розглянемо приклади розбору ланцюжків вхідної мови у вигляді послідовності конфігурацій МП- автомата, виконуючого розбір. Результат розбору представлятимемо у вигляді послідовності номерів правил граматики. На основі знайденої послідовності правил після виконання розбору за відсутності помилок (коли вхідний ланцюжок прийнятий МП- автоматом) можна побудувати дерево синтаксичного розбору.
Даний МП- автомат має тільки один стан. Тоді для ілюстрації роботи МП- автомата записуватимемо кожну його конфігурацію у вигляді трьох складових α β γ δ , де:
α — непрочитана частина вхідного ланцюжка:
β — вміст стека МП- автомата;
γ - послідовність номерів застосованих правил.
У початковому стані весь вхідний ланцюжок не прочитаний, стек автомата містить тільки лексему типу «початок рядку», послідовність номерів правил порожня.
Для зручності читання стек МП- автомата заповнюватимемо в порядку справа наліво, тоді те що знаходиться на верхівці стека вважатиметься крайнім правий символ в ланцюжку β .
Приклад 1
Візьмемо
вхідний ланцюжок
![]()
Після
виконання лексичного аналізу, якщо всі
лексеми типу «ідентифікатор» і
«константа» позначити як «а», одержимо
ланцюжок:![]() Розглянемо
процес синтаксичного аналізу цього
вхідного ланцюжка. Кроки функціонування
МП- автомата позначатимемо символом «
+ ». Символом
Розглянемо
процес синтаксичного аналізу цього
вхідного ланцюжка. Кроки функціонування
МП- автомата позначатимемо символом «
+ ». Символом
![]() позначатимемо
кроки, на яких виконується зрушення
(перенесення), символом «+c»
кроки,
на яких виконується згортка:
позначатимемо
кроки, на яких виконується зрушення
(перенесення), символом «+c»
кроки,
на яких виконується згортка:

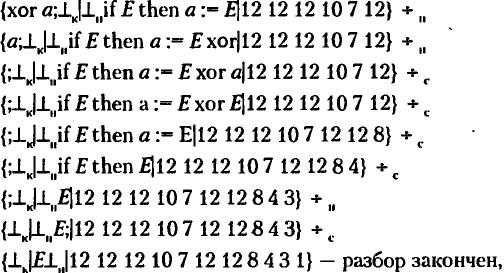 МП-
автомат перейшов в кінцеву конфігурацію,
ланцюжок прийнятий.
МП-
автомат перейшов в кінцеву конфігурацію,
ланцюжок прийнятий.
В результаті одержимо послідовність правив: 12 12 12 107 12 12 8 4 3 1. Цій послідовності правил відповідатиме ланцюжок виведення на основі остовної граматики G*:

Варто звернути увагу, що, так як даний МП- автомат будує правосторонній вивід, в ланцюжку виведення на кожному кроці правило завжди застосовується до крайнього правого нетермінального символу в ланцюжку.
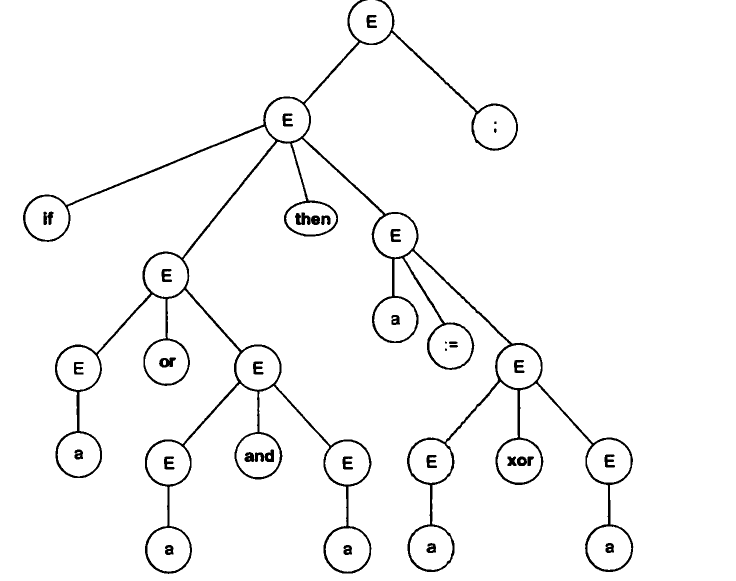
Дерево синтаксичного розбору, яке відповідає даному вхідному ланцюжку, приведено на мал. 3.2.
Приклад 2
Візьмемо
вхідний ланцюжок
![]()
Після
виконання лексичного аналізу, якщо всі
лексеми типу «ідентифікатор» та
«константа» позначити як «а», одержимо
ланцюжок:
![]() .
Розглянемо процес синтаксичного аналізу
цього вхідного ланцюжка:
.
Розглянемо процес синтаксичного аналізу
цього вхідного ланцюжка:
 відношення
передування між лексемами «(» і «then»,
розбір закінчений, МП- автомат не перейшов
в кінцеву конфігурацію, ланцюжок не
прийнятий (видається повідомлення про
помилку).
відношення
передування між лексемами «(» і «then»,
розбір закінчений, МП- автомат не перейшов
в кінцеву конфігурацію, ланцюжок не
прийнятий (видається повідомлення про
помилку).
Реалізація синтаксичного розпізнавача. Розбиття на модулі
У лабораторній роботі № 3, так як і в лабораторній роботі № 2, модулі, що реалізовують синтаксичний аналізатор розділені на дві групи:
модулі, програмний код яких не залежить від вхідної мови;
модулі, програмний код яких залежить від вхідної мови.
До першої групи входять модулі:
SyntSynb — описує структури даних для синтаксичного аналізу та реалізує алгоритм «зсув-згортка» для граматик операторного передування;
ForwLab3 — описує інтерфейс з користувачем.
До другої групи входить один модуль
Syntfiult — містить описи матриці операторного передування і правил початкової граматики.
Таке розбиття на модулі дозволяє використовувати ті ж самі структури даних для організації синтаксичного розпізнавача при зміні вхідної мови.
Окрім цих модулів для реалізації лабораторної роботи № 3 використовуються програмні модулі, що дозволяють працювати з комбінованою таблицею ідентифікаторів, які були створені при виконанні лабораторної роботи № 1, а також модулі, які забезпечують роботу лексичного розпізнавача (ці модулі були створені при виконанні лабораторної роботи № 2).
Стисло опишемо зміст програмних модулів, використовуваних для організації синтаксичного аналізатора.