

Типы связей между отношениями
Все отношения в БД должны быть связаны между собой. Различают связи нескольких типов, для которых введены следующие обозначения: один к одному (1: 1), один ко многим (1: N), многие к одному (N: 1) (перевернутая связь один ко многим) и многие ко многим (N:M).
Связь один к одному (1:1) предполагает, что в каждый момент времени одному кортежу отношения А соответствует не более одного кортежа отношения В и наоборот.
При связи один ко многим (1:N) одному кортежу отношения А соответствует 0,1 или более кортежей отношения В, но каждый кортеж отношения В связан не более чем с одним кортежем отношения А.
Связь многие ко многим (N:M) предполагает, что в каждый момент времени одному кортежу отношения А соответствует 0,1 или более кортежей отношения В и наоборот.
Распределенные базы данных (рбд)
К концу 80-х годов возникли новые условия работы для БД: большие объемы информации возникают во многих местах (например, розничная торговля, полиграфическое и другие производства); источником большого количества данных мог быть и центр, но к этим данным требуется быстрый доступ с периферии (географически распределенное производство, работающее по одному графику). К тому же данные могут запрашиваться и центром, и удаленными потребителями в удаленных местах. Имеется большое количество данных, которые используются в срочных запросах, чаще всего местного характера (продажа авиа- и железнодорожных билетов).
Пример В компьютерном интегрированном полиграфическом производстве необходимой является РБД (рис. 1), связывающая в единое целое процесс управления комплексом различных технологических процессов. Здесь осуществляется работа не с одним, а с системой приложений.

Рис. 01. РБД
Централизованные БД, особенно построенные на классическом подходе, не могли удовлетворить новым требованиям. Быстрое распространение сетей передачи данных, резкое увеличение объема внешней памяти ПК при ее удешевлении в 80-е годы способствовали широкому внедрению РБД.
Концепции распределенных баз данных:
Доступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы. Одним из перспективных направлений СУБД является гибкое конфигурирование системы, при котором распределение функций между клиентской и пользовательской частями СУБД определяется при установке системы.
Способов организации таких баз данных много:
можно разместить таблицы на разных компьютерах
использовать несколько идентичных хранилищ. В этом случае серверы взаимодействуют друг с другом для поддержания синхронизации. Если на одном из серверов происходит обновление данных, оно распространяется и на все остальные серверы.
В распределенной базе данных с симметричной схемой хранения исчезновение одного из серверов приводит к замедлению работы пользователей, находящихся ближе к этому серверу, но в целом система остается работоспособной. К тому же, она легко масштабируется, так как ее не нужно останавливать при добавлении еще одного сервера.
В несимметричной системеможно оптимизировать схему расположения данных. Чем ближе пользователи находятся к нужным им данным, тем меньше на их работу влияют сетевые задержки. В результате серверам приходится обрабатывать меньшие объемы данных. Это также способствует повышению безопасности данных, поскольку их можно физически хранить в тех системах, где пользователи имеют право работать с соответствующими данными. В целом, однако, применение распределенных баз данных связано с достаточно высоким риском. Требуется обеспечить соблюдение мер безопасности сразу на нескольких узлах, что не так-то просто реализовать.
Сервер обычно берет на себя задачи обработки транзакций и хранения данных, хотя в полностью распределенной базе данных за решение этих задач отвечают разные аппаратные компоненты. Три клиента взаимодействуют с двумя модулями обработки транзакций, которые, в свою очередь, работают с двумя хранилищами. Клиенты посылают свои запросы модулям, а те определяют, в каком из хранилищ находятся требуемые данные.

Рис. . Распределенные серверы
В идеальном случае, клиенты не знают, является система распределенной или нет. Они лишь посылают ей запросы, а система возвращает клиентам результаты этих запросов. Как она это делает, клиентов не интересует. На практике распределенные базы данных проявляют разную "прозрачность". В крайнем случае, РБД хранится на нескольких независимых серверах, а клиентскому приложению приходится выбирать сервер в зависимости от того, какую информацию требуется получить. Это подразумевает, что таблицы, находящиеся на разных серверах, не имеют никаких внутренних связей. Естественно, такая организация РБД лишь изредка оказывается полезной.
Это означает, что информация физически хранится на разных ЭВМ, связанных сетью передачи данных. Любой узел (участок) может выполнять приложение и участвовать в работе, по крайней мере, одного приложения.
К достоинствам РБД относятся:
1) соответствие структуры РБД структуре организаций;
2) гибкое взаимодействие локальных БД;
3) широкие возможности централизации узлов;
4) непосредственный доступ к информации, снижение стоимости передач (за счет уплотнения и концентрации данных);
5) высокие системные характеристики (малое время отклика за счет распараллеливания процессов, высокая надежность);
6) модульная реализация взаимодействия, расширения аппаратных средств, возможность использования объектно-ориентированного подхода в программировании;
7) возможность распределения файлов в соответствии с их активностью;
8) независимые разработки локальных БД через стандартный интерфейс.
Вместе с тем РБД обладают более сложной структурой, что вызывает появление дополнительных проблем (избыточность, несогласованность данных по времени, согласование процессов обновления и запросов, использования телекоммуникационных ресурсов, учет работы дополнительно подсоединенных локальных БД, стандартизация общего интерфейса) согласования работы элементов.
Серьезные проблемы возникают при интеграции в рамках РБД однородных (гомогенных) локальных БД с одинаковыми, чаще всего реляционными, моделями данных.
Проблемы значительно усложняются, если локальные БД построены с использованием различных моделей данных (неоднородные, гетерогенные РБД).
Распределенная база данных (РБД) (DDB – Distributed DataBase) - система логически интегрированных и территориально распределенных БД, языковых, программных, технических и организационных средств, предназначенных для создания, ведения и обработки информации.
Это означает, что информация физически хранится на разных ЭВМ, связанных сетью передачи данных. Любой узел (участок) может выполнять приложение и участвовать в работе, по крайней мере, одного приложения.
Большинство требований, предъявляемых к РБД, аналогично требованиям к централизованным БД, но их реализация имеет свою специфику. В РБД иногда полезна избыточность.
Дополнительными специфическими требованиями являются:
1) ЯОД в рамках схемы должен быть один для всех локальных БД;
2) доступ должен быть коллективным к любой области РБД с соответствующей защитой информации;
3) подсхемы должны быть определены в месте сосредоточения алгоритмов (приложений, процессов) пользователя;
4) степень централизации должна быть разумной;
5) необходимы сбор и обработка информации об эффективности функционирования РБД.
Состав и работа РБД
Схема
РБД может быть представлена в виде,
показанном на рис. 2.
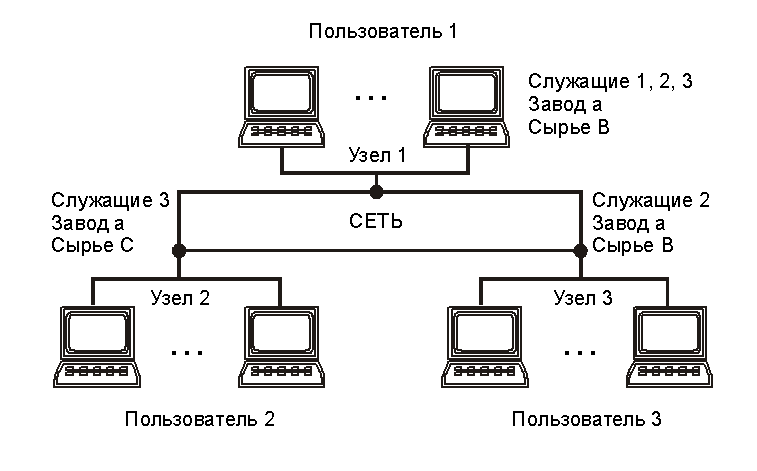
Рис. 02. Схема РБД
В ней выделяют пользовательский, глобальный (концептуальный), фрагментарный (логический) и распределенный (локализационный) уровни представления данных, определяющие сетевую СУБД.
Общий набор (система таблиц) данных, хранимых в РБД, показан в табл. 1.
Таблица 1.

Это глобальный уровень, который определяется при проектировании теми же методами, что и концептуальная модель централизованной БД.
Не все данные глобального уровня доступны конкретному пользователю. Наиболее полные данные (пользовательский, внешний уровень) имеются в узле 1 головного предприятия. В узлах (участках) 2, 3 данные менее полные. Так, в узле 3 они имеют вид, показанный в табл. 2.
Таблица 1.

Пользовательский уровень состоит из фрагментов (например, строки A, B, C, 1, 2, 3 или столбцы табл. 1) глобального уровня, которые составляют фрагментарный, логический уровень.
Выделяют горизонтальную и вертикальную фрагментацию (расчленение).
Горизонтальное фрагментирование связано с делением данных по узлам. Горизонтальные фрагменты не перекрываются.
Вертикальная фрагментация связана с группированием данных по задачам.
Фрагментация чаще всего не предполагает дублирования информации в узлах. В то же время при размещении фрагментов по узлам (локализации) распределенного уровня в узлах разрешается иметь копии той или иной части РБД.
Так, например, локализация для примера в табл. 1. может иметь вид, показанный в табл..
Таблица .