

Двухуровневые модели.
Эти модели фактически являются распределением пяти указанных функций между двумя процессами, которые выполняются на двух платформах - клиенте и сервере.
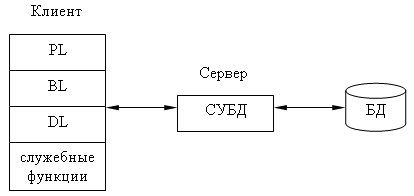
PL - это часть приложения, которая определяется тем, что пользователь видит на экране, когда работает приложение (интерактивные экранные формы, а также все то, что выводится пользователю на экран, результаты решения некоторых промежуточных задач, справочная информация).
Основные задачи PL:
формирование экранных изображений;
чтение и запись в экранные формы информации;
управление экраном;
обработка движений мыши и нажатий клавиш клавиатуры.
BL - это часть кода приложения, которая определяет алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования.
DL - это часть кода приложения, которая связана с обработкой данных внутри приложения (данными управляет собственно СУБД), где используется язык запросов и средства манипулирования данными стандартного языка SQL.
Процессор управления данными (Data Base Manager System Processing) - это собственно СУБД, которая обеспечивает управление и хранение данных. В идеале СУБД должна быть скрыта от BL-приложения. Однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
Классификация архитектур информационных систем не является абсолютно жесткой, наиболее типичная классификация:
1. Система совместного использования файлов – FS-модель Архитектура системы БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут также создавать на рабочих станциях локальные БД, которые используются ими монопольно.
В соответствии с этой моделью один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам и играет роль компонента доступа к информационным ресурсам (то есть к файлам). Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти. На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент. Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере. В системах, построенных по архитектуре файл-сервера все слои системы представляют единое и неделимое целое. БД хранится в виде файла или набора файлов на файл-сервере. Вся логика выборки, хранения и обеспечения непротиворечивости данных возлагается на клиентскую часть. Файл-серверные системы ориентированы на работу с отдельными записями в таблице. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими ОС, обеспечивающими удаленный разделяемый доступ к файлам. Запрос к БД, сформулированный на языке манипулирования данными, преобразуется СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.


Рис. Архитектура «файл – сервер»
Достоинства
Простота логики.
Низкие требования к аппаратному обеспечению и малый объем требуемой памяти.
Не требуют надежных многозадачных и многопользовательских ОС.
Невысокая цена СУБД.
Разделение монопольного приложения на два взаимодействующих процесса.
Сервер может обслуживать множество клиентов, которые обращаются к нему с запросами.
Недостатки
Ограниченность языка и негибкость среды разработки приложений
Слабая масштабируемость
Не обеспечивают многопользовательский режим работы
Трудно поддерживать целостность и непротиворечивость данных
Необходимость ручной блокировки записей или таблиц целиком.
Низкий уровень защищенности как внешней (от взлома), так и внутренней (от ошибок приложений) Например индексы отдельно от таблиц.
Не имеют средств шифрации сетевого трафика
Создают высокую нагрузку на сеть
Бизнес-правила функциональной обработки, сосредоточенные в клиентской части, могут быть противоречивыми
Выводы
Файл-серверная архитектура является достаточно привлекательной альтернативой для создания однопользовательских ИС со слабыми требованиями к защите данных. В целом, в файл-серверной архитектуре имеет "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти.
Для схемы характерно наибольшее суммарное время обработки информации.