

Технология проектирования и администрирования баз данных и систем данных-Конспект
.pdfРис. 6.10
Модель, приведенная на рис. 6.11, содержит два типа набора:
Тип набора I – ЗАЧЕТЫ-СТУДЕНТА: владелец – СТУДЕНТ, член – СЕМЕСТР+КУРС+СТУДЕНТ.
Тип набора II – ЗАЧЕТЫ-ПО-КУРСУ-В-СЕМЕСТРЕ: владелец – СЕМЕСТР+КУРС, член – СЕМЕСТР+КУРС+СТУДЕНТ. Тип записи СЕМЕСТР+КУРС+СТУДЕНТ связывает типы наборов I и II.
Рис. 6.11
4. Упрощение имен ключей.
В конструкции набора могут иметь следующие имена ключей (см. левый рис. 6.12):

Рис. 6.12
Изъяв из имени ключа каждой записи-члена часть, входящую в состав ключа записи-владельца, .можно упростить ключи так, как показано на правом рис. 6.12.
После упрощения имен ключей логическая модель (рис. 6.11) приобретает вид, показанный на рис. 6.13. Здесь представлены два типа наборов:
Тип набора I – ЗАЧЕТЫ-СТУДЕНТА: владелец – СТУДЕНТ, член – СЕМЕСТР+ КУРС + СТУДЕНТ.
Тип набора II – ЗАЧЕТЫ-ПО-КУРСУ-В-СЕМЕСТРЕ: владелец – СЕМЕСТР+КУРС, член – СЕМЕСТР+КУРС+СТУДЕНТ. Тип записи СЕМЕСТР+КУРС+СТУДЕНТ связывает типы наборов I и II.
5. Реализация взаимосвязей, которые не отражены в логической модели, но на самом деле существуют.
Вводить какие-либо новые взаимосвязи в представленную на рис. 6.11 модель нет никакой необходимости.
Рис. 6.13
Таким образом, на рис. 6.13 получена улучшенная логическая модель, в которой из записи СЕМЕСТР+КУРС+СТУДЕНТ исключены элементы СЕМЕСТР, НОМ-КУРСА и НОМ-СТУДЕНТА (см. рис. 6.11).

7. ФИЗИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
Одним из основных факторов, влияющих на производительность программ, которые взаимодействуют с базой данных, является способ хранения и доступа к данным. Обычно в дополнение к специализированным методам доступа в рамках внешней модели СУБД использует несколько методов доступа внутренней модели. Внутренняя модель – это модель физическая, внешняя же отражает представление пользователя (о базе данных). Некоторые методы доступа внутренней модели совпадают с методами доступа операционной системы. Большинство СУБД позволяют проектировщику базы данных варьировать параметры физической организации. Для того чтобы база данных обеспечивала эффективное хранение и доступ к данным, проектировщик должен хорошо знать методы доступа как внутренней модели (физической), так и внешней (представления пользователя) [1], [3], [4].
7.1. Интерфейсы между пользователем и базой данных
На практике увеличение числа операций физического ввода-вывода, выполняемых при выборке данных для удовлетворения запроса пользователя, приводит к снижению производительности.
В процессе выполнения запроса пользователя система проходит несколько интерфейсов (рис. 7.1).
Рис. 7.1

Выполнение запроса пользователя обеспечивают СУБД, методы доступа внешней и внутренней моделей, а также методы доступа операционной системы.
Интерфейс 1. При получении запроса СУБД «известно» описание представления пользователя и прикладной программы, а также условия безопасности и секретности. На основании представления пользователя определяется, к какой физической базе (базам) данных может осуществляться доступ. Кроме того, из описания физической базы (баз) данных известен используемый метод (методы) доступа внутренней модели. Разные реализации предоставляют различные возможности, однако в большинстве из них поддерживается несколько представлений пользователя о базе данных.
Интерфейс 2. В свою очередь СУБД использует методы доступа внутренней модели, которые в разных системах реализованы по-разному: либо как специализированные методы доступа, предоставляемые СУБД, либо как сформированные из обобщенных методов доступа операционной системы. Примерами могут служить ISAM (индексно-последовательный метод доступа) и BDAM (базисный прямой метод доступа).
Интерфейс 3. Методы доступа внутренней модели совместно с методами доступа операционной системы осуществляют доступ к записи (записям) физической базы данных и создают основу для нахождения нужной записи (записей) методом (методами) доступа, описывающими логические взаимосвязи между различными частями записи базы данных.
Методами доступа операционной системы, а также внешней и внутренней моделей, осуществляют выборку данных из физической базы (баз) данных и их передачу СУБД, которая определяет, какая часть данных может быть выдана пользователю, в каком формате и т. д. АБД должен описать все эти характеристики для СУБД до начала реализации базы данных.
7.2. Методы доступа внутренней модели (физической)
Различают следующие методы доступа внутренней модели: физический последовательный, индексно-последовательный, индексно-произвольный, инвертированный и посредством хеширования. Для каждого из них зададим два критерия:
1.Эффективность доступа – величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа, т. е. запроса конкретной записи базы данных. Физические обращения обеспечивают удовлетворение запроса. Например, если для поиска нужной записи система обращается к двум записям, то эффективность доступа равна 0,5.
2.Эффективность хранения – величина, обратная среднему числу байтов поля вторичной памяти, требуемого для хранения одного байта исходных данных. Кроме исходных данных, память занимают таблицы, управляющая информация, свободная область, резервируемая для расширений, и область, не используемая из-за фрагментации.

Физический последовательный.
Значения ключей физических записей находится в логической последовательности.
В основном применяется для «дампа» и «восстановления».
Может применяться как для хранения, так и для выборки данных. Эффективность использования памяти близка к 100%.
Эффективность доступа физического последовательного метода оставляет желать лучшего. Для выборки нужной записи требуется просмотреть все предшествующие ей записи базы данных.
Индексно-последовательный.
Метод доступа, при использовании которого до осуществления доступа к собственно записям базы данных проверяются значения ключей, называется индексно-последовательным.
Значения ключей физических записей находятся в логической последовательности. Может применяться как для хранения, так и для выборки данных.
В индекс значений ключей заносятся статьи наибольших значений ключей в блоках.
Наличие дубликатов значений ключей недопустимо.
Эффективность доступа зависит от числа уровней индексации, распределения памяти для размещения индекса, числа записей базы данных и уровня переполнения.
Эффективность хранения зависит от размера и изменяемости базы данных.
Индексно-произвольный.
При индексно-произвольном методе доступа записи хранятся в произвольном порядке. Создается отдельный файл из статей, содержащих значения действительного ключа и физические адреса хранимых записей.
Значения ключей физических записей необязательно находятся в логической последовательности.
Хранение и доступ к индексу могут осуществляться с помощью индекснопоследовательного метода доступа.
Индекс содержит статью для каждой записи базы данных. Эти статьи упорядочены по возрастанию. Ключи индекса сохраняют логическую последовательность. Если же они эту последовательность не сохраняют, доступ к индексу осуществляется посредством алгоритма хеширования. Записи базы данных могут быть и не упорядочены по возрастанию ключа.
Может использоваться как для запоминания, так и для выборки данных.
Инвертированный.
Значения ключей физических записей необязательно находятся в логической последовательности.
Может использоваться только для выборки данных.
Индекс может быть построен для каждого инвертируемого поля.
Эффективность доступа зависит от числа записей базы данных, числа уровней индексации и распределения памяти для размещения индекса.

Как правило, инвертированный метод доступа применяется только для выборки. Запоминание осуществляется с помощью каких-либо других методов доступа.
Прямой метод доступа.
При прямом методе адреса памяти, используемые при хранении и поиске физических записей, могут быть уникальными. Каждому ключу записи соответствует уникальный адрес ячейки памяти.
Не требуется упорядоченность значений ключей физических записей.
Между ключом записи и ее физическим адресом существует взаимно однозначное соответствие.
Может применяться как для хранения, так и для поиска.
Эффективность доступа всегда равна единице.
Эффективность хранения зависит от плотности ключей.
Наличие дубликатов ключей недопустимо.
Метод доступа посредством хеширования.
Не требуется логическая упорядоченность значений ключей физических записей. Значениям нескольких ключей может соответствовать один и тот же физический адрес (блок).
Может применяться как для хранения, так и для поиска.
Эффективность доступа зависит от распределения ключей, алгоритма их преобразования и распределения памяти.
Эффективность хранения зависит от распределения ключей и алгоритма их преобразования.
При методе доступа посредством хеширования адрес физической записи
алгоритмически определяется из значения ключа записи.
Как правило, разработчику базы данных приходится находить приемлемое соотношение между эффективностью доступа и эффективностью хранения. Эффективность доступа приобретает особое значение в оперативных системах. Некоторые СУБД сконструированы так, чтобы обновления (базы данных) в оперативном режиме выполнялись оптимальным образом.
7.2.1. Физический последовательный метод доступа
Физический последовательный метод доступа предполагает хранение физических записей в логической последовательности. При использовании в качестве носителя хранимых данных последовательного устройства, программист должен предоставлять системе физические записи в логической последовательности. В том случае, когда носителем служит память прямого доступа, система связывает физические записи таким образом, что они образуют логическую последовательность, даже если они не передавались ей в этой последовательности.
Эффективность доступа. Пусть одна физическая запись выбрана, и предстоит выбрать другую с большим значением ключа. В худшем случае для выборки нужной записи необходимо просмотреть все записи базы данных, а в лучшем достаточно выбрать следующую запись. Число записей, к которым

необходимо осуществить доступ для выборки нужной, составляет в среднем половину общего числа записей, содержащихся в базе данных.
Эффективность хранения. Если носителем данных служит последовательное устройство, программист должен предоставлять записи базы данных в логической последовательности. В результате память на носителе будет заполняться плотно. При использовании устройства прямого доступа каждой следующей представляемой физической записи система отводит следующий доступный участок физической памяти. Затем между записями базы данных организуются связи, обеспечивающие возможность логически последовательной выборки.
Эффективность доступа физического последовательного метода крайне низка. Для выборки нужной записи необходимо просмотреть все предшествующие ей записи базы данных. Хранение физических записей в логической последовательности можно использовать для ускорения доступа, если до обращения к собственно записям базы данных проверять значения ключей. Метод доступа, построенный по этому принципу, называется индексно-последовательным, а значения ключей хранятся в «индексе».
7.2.2. Индексно-последовательный метод доступа
Существует множество индексных методов доступа, в основе которых лежит принцип создания отдельного файла или структуры из статей значений действительного ключа. Статья действительного ключа называется статьей индекса, а весь файл действительных ключей, как отмечено выше, – индексом. Индексный файл значительно меньше собственно базы данных, и, поскольку в оперативной памяти могут находиться многие из его статей, скорость поиска в нем гораздо выше.
В индексно-последовательном методе доступа индексный файл всегда упорядочен по так называемому первичному ключу (рис. 7.2). Первичный ключ
– главный атрибут физической записи. По его значению идентифицируется физическая запись. До тех пор, пока это возможно, записи хранятся в той же логической последовательности, что и индекс (отсюда и название «индекснопоследовательный метод доступа»). Поэтому индекс должен содержать ссылки не на каждую запись базы данных по ключу, а на группу записей, хранимых в физическом блоке, по диапазону ключей. Например, если в блоке хранится 10 записей, то для него в индексном файле будет одна статья, а не десять, и размер индексного файла уменьшится в 10 раз.
Последовательная организация индексного файла допускает индексацию его содержимого. Записи индекса группируются в блоки, которые можно также индексировать. При работе с большими файлами такая организация позволяет улучшить характеристики доступа,
На практике ключи редко распределены равномерно, из-за чего предварительное закрепление значений ключей за блоками нежелательно, поэтому при создании файла данных производится первоначальная загрузка в него физических записей, упорядоченных по первичному ключу.

Рис. 7.2
Индексный файл и файл данных организованы последовательно. Индексный файл содержит только максимальные значения первичных ключей записей каждого блока.
Наибольшее либо наименьшее значение ключа последней содержащейся в блоке записи (большинство поставляемых методов доступа обеспечивают загрузку файла данных по возрастанию значения первичного ключа) заносится в индексный файл (рис. 7.2).
Каким же образом метод доступа осуществляет включение новых записей? В зависимости от значений добавляемых записей может потребоваться изменение элементов индекса. Что происходит, когда в блоке нет места для размещения новой записи? Возможны два пути решения этой проблемы:
1.Запись запоминается в отдельной области, называемой областью переполнения, и блок в этой области связывается в цепочку с блоком, которому логически принадлежит запись. Обращения к записям в области переполнения могут значительно снизить эффективность доступа.
2.При невозможности введения записи в блок он делится пополам. Первый из двух вновь созданных блоков содержит половину записей, находящихся в исходном блоке, а второй – другую половину. (Иногда разделение блока производится таким образом, что первый блок содержит две трети записей исходного блока, а второй – оставшуюся одну треть.) Затем в индексном файле создается новая статья. По сравнению с организацией цепочек записей в области переполнения при использовании данного метода эффективность доступа в большинстве случаев выше. Однако при многократном расщеплении одних и тех же
блоков следует разгрузить и реорганизовать файл, а также создать новый индексный файл.
Для очень больших файлов целесообразно строить несколько индексных файлов. Индексный файл следующего уровня содержит указатели на индексный файл предыдущего уровня. Построение системы индексации этого
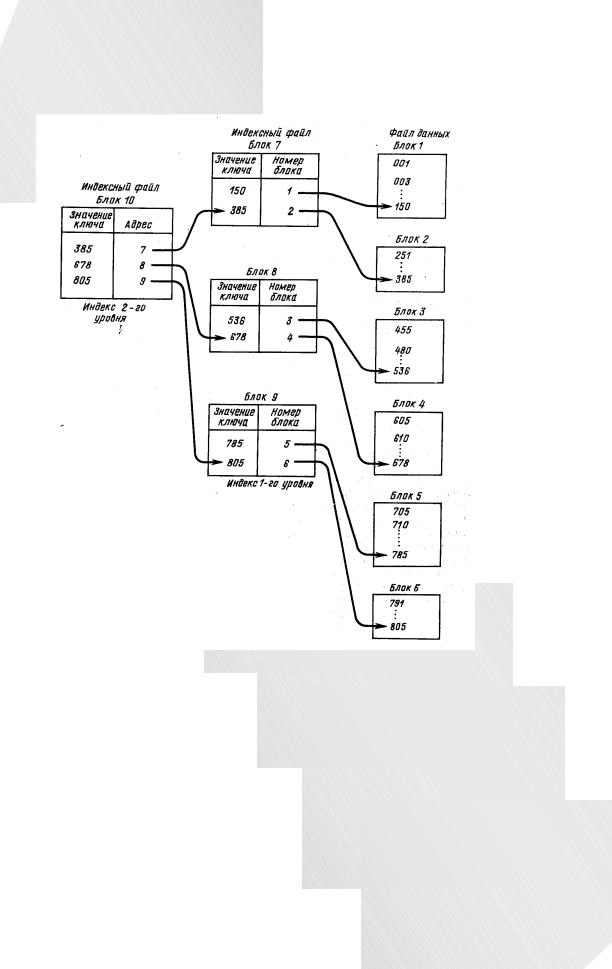
типа может обеспечить приемлемые размеры индексного файла высшего уровня и возможность хранения его в памяти процессора. На рис. 7.3 показано построение индексного файла более высокого уровня.
Рис. 7.3
Чтобы достичь наивысшей производительности при работе с индекснопоследовательными файлами, необходимо учесть следующие факторы.
Эффективность доступа.
1.Размеры базы данных. По мере расширения базы данных индекс приобретает все большее число элементов. Вероятным результатом этого является повышение уровня индексации. Но наличие индексного файла большого размера или высокий уровень индексации снижают эффективность доступа. В большой базе данных решающим фактором становится скорость выборки первичных и вторичных ключей.
2.Размер блока. Средний размер блока .и число блоков в базе данных – величины взаимообратные. Чем больше размер блока, тем меньшее их число хранится в базе данных, и тем соответственно меньше элементов в индексе. Следует также принимать во внимание время передачи больших блоков по каналам. Необходимо определить оптимальный

размер блока базы данных.
3.Обновление базы данных. Высокая активность включения и удаления записей базы данных снижает эффективность доступа, поэтому время от времени необходимо проводить реорганизацию базы данных и индексных файлов. В некоторых системах частое обновление несущественно снижает эффективность доступа. Однако использование методов, обеспечивающих возможность поддержания эффективности доступа на постоянном уровне, приводит к увеличению размера базы данных, т. е. к снижению эффективности хранения.
4.Индекс высшего уровня в памяти процессора. Выделение достаточного для размещения индекса высшего уровня памяти процессора повышает
эффективность доступа. Эффективность хранения.
1.Размеры базы данных. Для размещения записей, добавляемых в базу данных после начальной загрузки, используется свободная область, резервируемая во время начальной загрузки. Эффективность хранения зависит от того, какую часть памяти, отводимой базе данных, занимает эта свободная область. Поскольку записи должны быть организованы логически последовательно, эффективность хранения зависит и от того, в какой части базы данных частота включения и удаления записей базы данных наиболее высока. Определение числа свободных физических блоков и их частей требует проведения соответствующего анализа.
2.Размер блока. Размер блока и число блоков – два фактора, влияющие на эффективность хранения. При значительной длине блока статьи индекса занимают меньший объем памяти. По мере увеличения длины блоков сокращается их число. С ростом числа блоков требуется больше уровней
индексации.
Также следует отметить, что большинство систем допускают только уникальные значения ключей индекса.
7.2.3. Индексно-произвольный метод доступа
При таком методе доступа записи хранятся в произвольном порядке и создается отдельный файл статей, включающих значения действительного ключа, и физические адреса хранимых записей. Статья, содержащая действительный ключ и адрес, называется статьей индекса, а весь файл – индексом. Каждой записи базы данных соответствует статья индекса. Существует два основных способа создания индекса и доступа к нему индексно-произвольного метода доступа. Первый способ заключается в применении для ведения индекса схемы упорядочения (например, система IMS обеспечивает так называемое вторичное индексирование, которое иллюстрируется рис. 7.4). Доступ к индексу последовательный. Последовательная организация индекса дает возможность последовательно обрабатывать записи. При втором способе индекс не упорядочивается, но к нему осуществляется произвольный доступ (например, система DMS-11 обеспечивает произвольный доступ к статьям индекса, рис. 7.5). В этом случае