

26.3. Локальные шины.
Шина VL - bus (VLB) или VESA (Video Electroniсs Standart Association) (начало 90-х).
С развитием видеоподсистем существенно возрос объём видеоданных, которыми необходимо обмениваться ЦП с видеоадаптером. при этом наиболее узким местом, содержащим повышение производительности системы стала шина ISA. Поэтому производители ПК решили отделить графические компоненты от шин расширения, передав их функции высокоскоростной локальной шине, расположенной между процессором и памятью. Т.о. в начале 90-х годов разработан стандарт 32-разрядной локальной шины VESAилиVL-bus. Эта шина обходит системную шину и напрямую связывается с ЦПУ.
Шина VL-bus представляет собой расширение интерфейса CPU i486. Физически она реализована в виде разъёма, дополнительного к стандартному разъёму системной шины ISA(EISA).
Теоретическая производительность VL-bus-132 Мбайта/с., реальная- 80 Мбайт/с. Допускает передачу 32-разрядных данных со скоростями, которые обеспечивает СPU. Оговорена максимальная частота-50 МГц. На шине VLB поддерживается 3-4 устройства.
Развитием стандарта стала 64-разрядная шина, которая обеспечивает работу до 3-х периферийных устройств с частотой до 40 МГц и 2-х с частотой 50МГц, теоретическая скорость передачи может быть 400Мбайт/с.
Особенностью шины VLB является то. что она процессорно-зависима и ориентирована на работу в системах с CPU i486.
Поскольку шина VLB напрямую связана с шиной CPU, установка в систему VLB платы, которая не успевает за работой шины на её рабочей частоте, вводят в работу МП цикл ожидания. Это приводит к уменьшению производительности всей системы так как каждый цикл ожидания сказывается не только на работе платы, но и на работе процессора.
Шина VLB является хорошим расширением для работы с графическими контроллерами. Подходит для видео- и мультимедиа приложений. Наиболее широко шина VLB использовалась в 1994-1995г.г.
26.4. Шина pci (Peripheral Component Interconnect) (1992 год).
С увеличением числа ПК с CPU Pentium всё больше системных плат стало выпускаться с шиной PCI, в том числе и для систем на базе МП i486. В отличии от шина VLB, шина PCI является процессорно-независимой.
Шина PCI работает с фиксированной частотой 33МГц, осуществляя передачу 32-разрядных данных, она поддерживает работу до 10 периферийных устройств. Теоретическая максимальная пропускная способность шины-132Мб/с, что соответствует современным МП. Практически, на действующих системах скорость передачи данных достигает 50 Мб/c/, что ниже теоретической. Разъёмы PCI имеют 50 штырьков для сопряжения с другими компонентами(типа PAD-вилка).
Строго говоря, PCI относится к классу т.н. mezzanine-шин, т.е. шин - “пристроек”, поскольку между локальной шиной МП и самой PCI находится специальная микросхема согласующего “моста”(bridge).
Особенности шины PCI.
1. Независимость от процессора.
Наличие контроллера, роль которого выполняет специальная микросхема (мост), позволяет разделить управляющие сигналы локальной шины МП и PCI- шины. Это приводит к тому, что локальная шина может работать с различными процессорами, причем подсоединение большого числа устройств к шине PCI обычно не снижает производительность системы в целом.
Кроме того “мосты” могут использоваться и для связи между шиной PCI и другими системными шинами (например, PCI to ISA Bridge).
2. Полный групповой режим обмена.
Шина PCI поддерживает способ передачи данных, называемый полным групповым режимом обмена, которая обеспечивает постоянное заполнение шины передаваемыми данными. Периферийные устройства ожидают получение данных из основной памяти системы в режиме (linear address), при котором большие объёмы данных считываются или записываются блоками, с однократной передачей адреса. Этот режим позволяет увеличить ширину полосы пропускания, используемую действительно для передачи данных в место ненужных адресов. Уникальность шины PCI заключается в том, что она предусматривает полный групповой режим обмена, как для операции чтения, так и записи. Это особенно важно при работе с современными графическими подсистемами, когда более 90% обращений к данным ЦП представляет собой записи в кадровый буфер из основной памяти.
3. Управление шиной и параллельное выполнение (конкурентность) операций.
Улучшение качества функционирования достигается также за счет поддержки шиной PCI функций управления шиной (bus mastering) и конкурентности операций. Функция управления шиной заложена в большинстве шин, она позволяет любому интеллектуальному периферийному устройству "взять на себя" управление шиной для того, чтобы ускорить выполнение высокоприоритетных задач, требующих большой пропускной способности шины. Конкурентность (параллельное выполнение) операций – уникальное свойство шины PCI, обеспечивающее возможность одновременной работы микропроцессора с этими устройствами, временно управляющими шиной. Это позволяет, например, ЦП выполнять числовые операции с плавающей занятой в прикладной программе - электронной таблице, в то время как будет продолжаться обмен данными по шине PCI между платой Ethernet и локальной сетью. Такое распараллеливание операций невозможно осуществить с помощью шины VL/VESA.
4. Совместимость.
Так как шина PСI сконструирована как дополнение к шине ввода - вывода, она полностью совместима с шинами ISA, EISA и MCA. И хотя каждая вычислительная система имеет ограниченное число слотов, спецификация PCI позволяет изготовителям систем предложить заказчикам так называемые "слоты двойного назначения", в которые можно вставлять как платы с соединителем PCI, так и с каким-либо другим соединителем из числа стандартных - ISA, EISA, MCA. Например, в компьютере HP Vectra XP имеются 2 слота PCI, в том числе один является слотом двойного назначения PCI/ISA. И, наконец, любая PCI- совместимая плата будет работать с любой PCI- содержащей системой вне зависимости от того, какая шина ввода – вывода или какой микропроцессор используется в данной системе. Этим свойством не обладает шина VL/VESA: предназначенные для нее платы расширения рассчитаны на конкретное быстродействие процессора и шины ввода - вывода.
5. Эффективность затрат.
Спецификация PCI разработана с целью снижения общих затрат на проектирование вычислительной системы. Использованы микросхемы с высокой степенью интеграции. В отличие от компонентов VL/VESA, имеющих более 80 выводов, компоненты PCI имеют всего 50 выводов для сопряжения с другими компонентами.
6. Перспективы.
Шина PCI спроектирована с учетом перспектив развития отрасли. В частности, предусматривается расширение до 64 разрядов, такое расширение 32-разрядной шины сможет удвоить пропускную способность системы, доведя ее до 264 Мбайт/с. Не менее важно то, что все коммуникации между 32-разрядными и 64-разрядными периферийными устройствами прозрачны для пользователя из-за специального разъема, сопрягаемого как с 32-разрядными, так и 64-разрядными платами. PCI предусматривает также возможность автоконфигурирования. Каждая из периферийных плат PCI должна содержать специальный 256-байтный заголовок, доступ к которому осуществляется в течение специальных циклов автоконфигурации PCI. В заголовке предусмотрены поля, указывающие на производителя платы, тип и версию устройства, его функции, требования по занимаемому адресному пространству, прерываниям, свойствам циклов работы по шине. Программа инициализации опрашивает устройства и назначает системные ресурсы в соответствии с требованиями, содержащимися в конфигурационных заголовках. Пользователю больше не надо задавать параметры в программе конфигурации, которая происходит автоматически во время выполнения программы инициализации.
PCI признана наиболее перспективной архитектурой локальной шины для отрасли, заняла ведущее место в 1995-1996 г.
Типовая архитектура вычислительной системы с локальной шиной PCI представлена на рис. 26.4.
Шина PCI является 32-разрядной мультиплексной шиной. Мультиплексность означает, что один за другим, по тем же линиям передаются сначала адрес, затем данные. Это позволяет уменьшить число линий шины и получить более дешёвое решение (особенно с учётом реализации группового режима обмена).
Для подключения большого числа периферийных устройств (более 10-ти) используются дополнительные мосты (PCI to PCI).
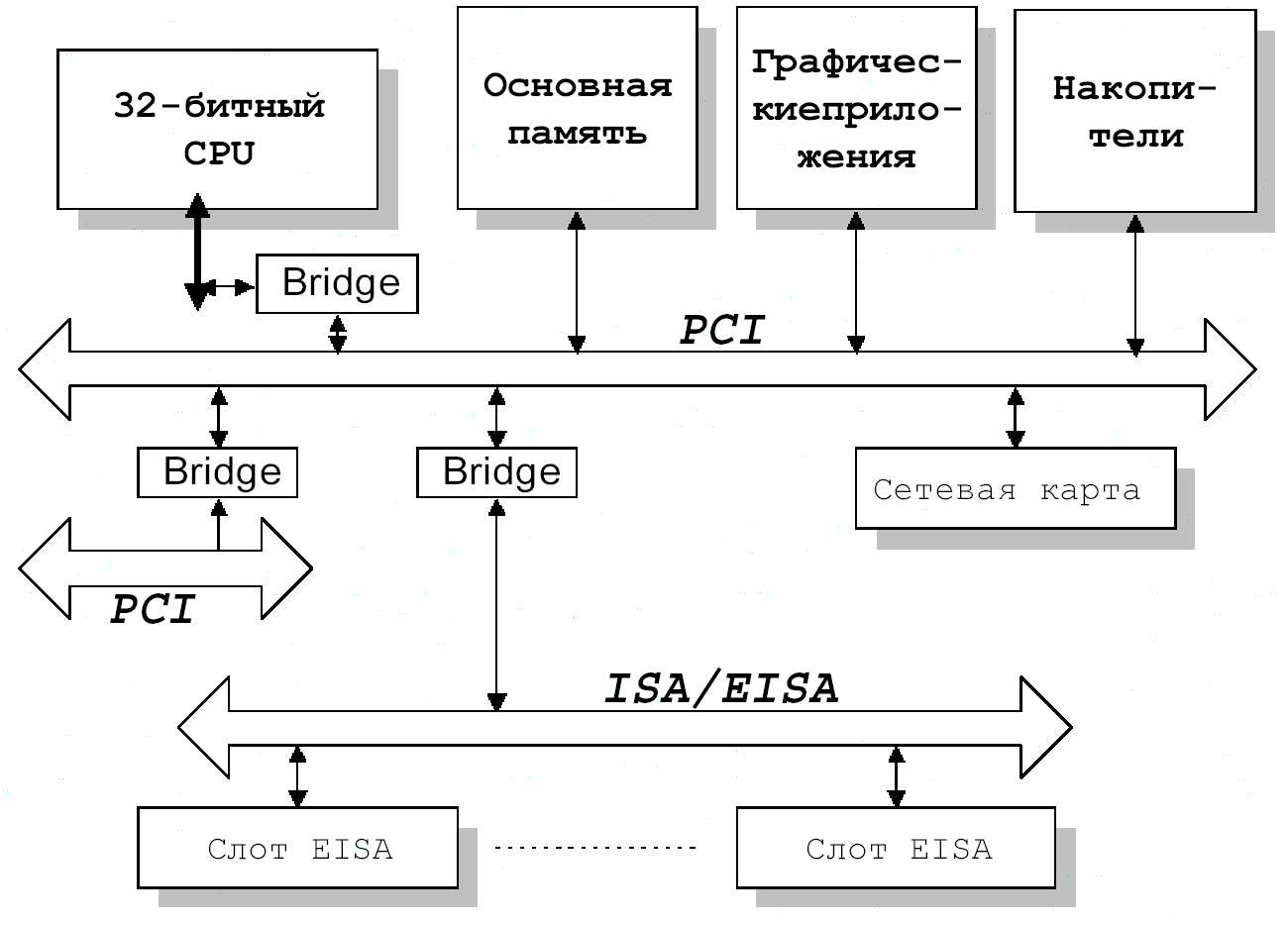
Рис.26.4.